学界 | 价值传播网络,在更复杂的动态环境中进行规划的方法
选自arXiv
机器之心编译
参与:陈韵竹、张倩
本文提出了一种基于价值迭代的参数高效差异化规划模块——价值传播网络(Value Propagation Networks),可以通过强化学习进行训练,用来完成未见过的任务。该模块能泛化到更大尺寸的地图中,并学习在动态环境中进行导航。此外,该模块能够在环境包含随机元素时学习进行规划,为各类交互式导航问题提供具有成本效益的学习系统,从而构建低级别、尺寸不变的规划器。
1 引言
规划是许多领域人工智能体的关键组成部分。然而,经典规划算法的局限性在于,对于每种可能的规划实例,人们都需要知道如何为其搜索最优(或至少合理的)方案。环境动态和状态复杂度的增加给规划的写作人员制造了困难,甚至使其完全不切实际。「学习做规划」旨在解决这些问题,这也就是为什么「学习做规划」一直是活跃研究领域的原因之一 [Russell et al., 1995, Kaelbling et al., 1996]。出于实用性考虑,我们提出,学习规划者的方法应该有至少两个属性:算法的轨迹应是自由的,即不需要最优规划者的轨迹;算法应该可以泛化,即学习规划者应该能解决同类型但未曾遇到的实例和/或规划期。
在强化学习(RL)中,学习规划可以被认为是寻找环境预期回报最大化策略的问题。其中,这种策略是一个贪婪函数(greedy function),选择将访问具有较高智能体价值状态的行动。这又将问题转移到如何成功估计状态值的问题。解决此问题常用的算法之一是价值迭代(VI),它通过收集和传播所看到的奖励来估计值,直到达到固定点。然后,可以通过在所需的状态-行为对上展开所获得的价值函数来构建策略或规划。
当环境可以表示为占据栅格图(二维网格)时,可以使用深度卷积神经网络(CNN)来近似该规划算法,从而在网格单元上传播奖励。这使得人们能够通过规划者的步骤直接加以区分,并执行价值函数的端到端学习过程。Tamar et al. [2016] 训练了这样一个模型——价值迭代网络(Value Iteration Networks,VIN)——该模型对来自搜索/规划算法的轨迹采用了有监督的损失函数,其目标是通过使用卷积层迭代学习值寻找可以解决此类环境中最短路径任务的参数值。但是,此基准需要良好的目标价值估计,这违反了我们所希望的无轨迹属性并限制了其在交互、动态、设置中的使用。此外,它没有利用模型结构将其泛化到更难的任务实例中去。这正是我们进一步着手研究的内容。
在这项研究中,我们进一步规范了 VIN 的使用,从而更准确地表示类似 gridworld 的场景结构,使价值迭代模块能够在强化学习框架内自然地使用,这超出了初始工作的范围,同时还消除了一些限制以及约束原始架构的基本假设。研究表明,我们的模型不仅可以在动态环境中学习规划和导航,而且它们的层次结构提供了一种方法来泛化导航任务,其中所需的规划期和地图的大小比在训练时所看到的大得多。
我们的主要贡献包括:(1)引入 VProp——这是一个网络规划模块,通过强化学习能成功学习解决路径搜寻任务,(2)展现了只在小图训练的基础上也具有的在大型未见过的地图中泛化的能力,(3)表明无论是在转换函数还是观察复杂度方面,我们的模块可以学习在具有比静态「网格世界」更复杂的动态环境中进行规划。

图 1:VIN 数据集随机图和我们训练环境一些随机配置之间的比较。在我们自定义的网格世界中,块的数量随着尺寸的增加而增加,但它们在总可用空间中的百分比保持不变。在图中,为了提高可视化效果,智能体和目标以圆形显示,但实际上它们仍占据单个单元格。
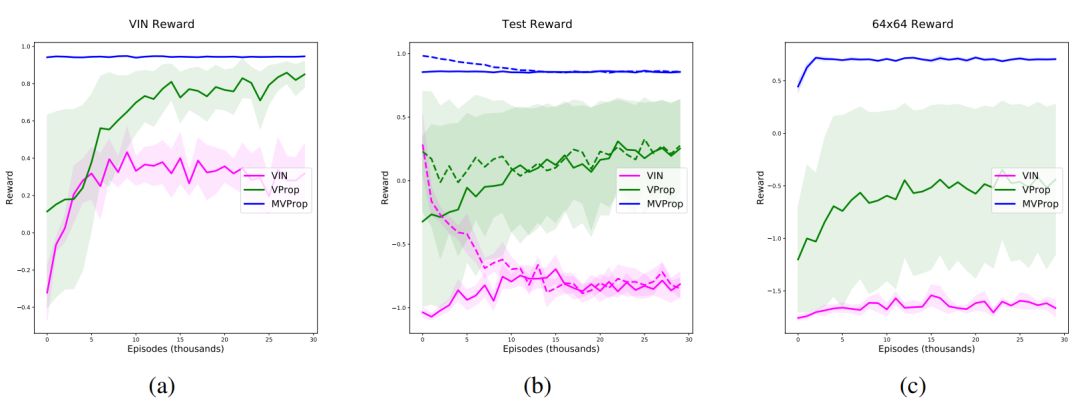
图 2:在我们的课程中所训练的所有模型的平均、最小和最大奖励。请再次注意,在前两张图中,地图大小为 32×32。a 和 c 分别展示了 VIN 数据集和我们生成的 64×64 图的性能。b 显示受课程设置所限(虚线)和未受限(实线)时在评估图上的表现情况。
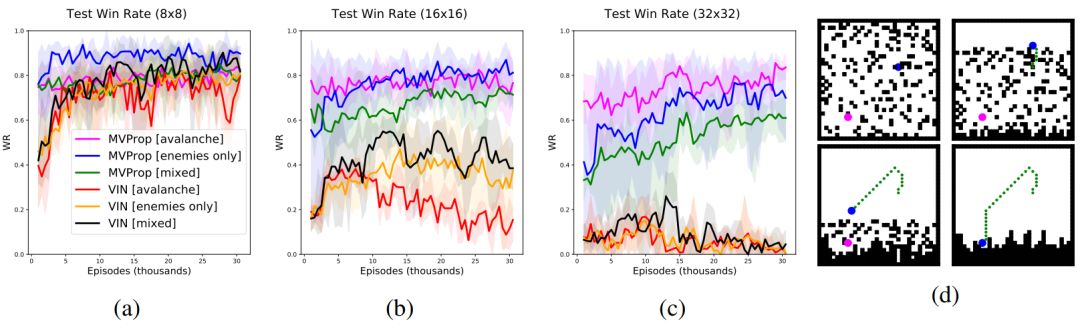
图 3:在我们的动态实验中获得的平均、最小和最大测试获胜率。每个智能体都以与静态世界实验相似的方式在场景的 8x8 实例上进行了训练。图 3d 显示了在雪崩测试配置训练后获得的策略示例。智能体和目标显示为圆形以提高可视化效果,但它们仍占用单个单元格。
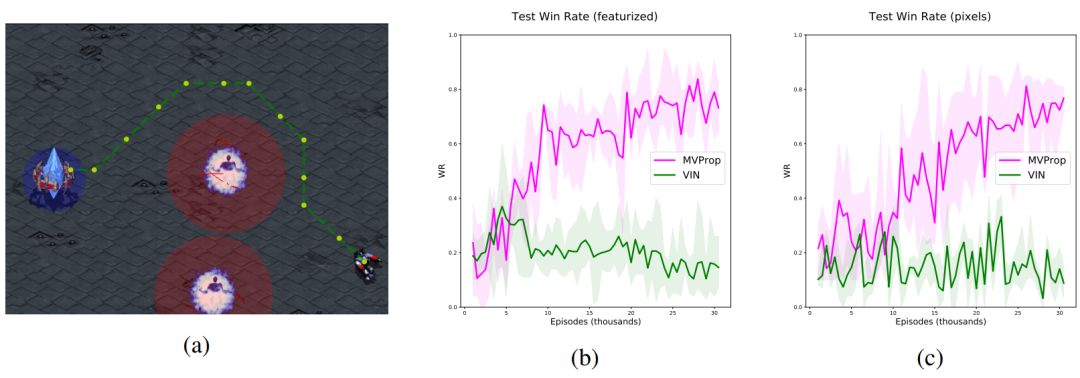
图 4:星际争霸的导航结果。图 4a 显示了训练后期随机场景中产生的轨迹。红色和蓝色覆盖图(未展示给智能体)表示其与每个实体交互所需的距离。
论文:Value Propagation Networks

论文地址:https://arxiv.org/pdf/1805.11199.pdf
摘要:本文提出了价值传播网络(Value Propagation Networks),这是一种基于价值迭代的参数高效差异化规划模块,可以通过强化学习进行训练,用来完成未见过的任务,还能泛化到更大尺寸的地图中,并且可以学习在动态环境中进行导航。此外,我们还证明,该模块能够在环境包含随机元素时学习进行规划,为各类交互式导航问题提供具有成本效益的学习系统,从而构建低级别、尺寸不变的规划器。我们在 MazeBase 网格世界的静态和动态配置进行了评估,使用了几种不同尺寸的随机生成环境;此外还在星际争霸导航场景中对其进行了评估,结果表明它具有更复杂的动态特性以及像素输入。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



