Nature:闭关修炼9个月,AlphaStar达成完全体,三种族齐上宗师,碾压99.8%活跃玩家

新智元报道
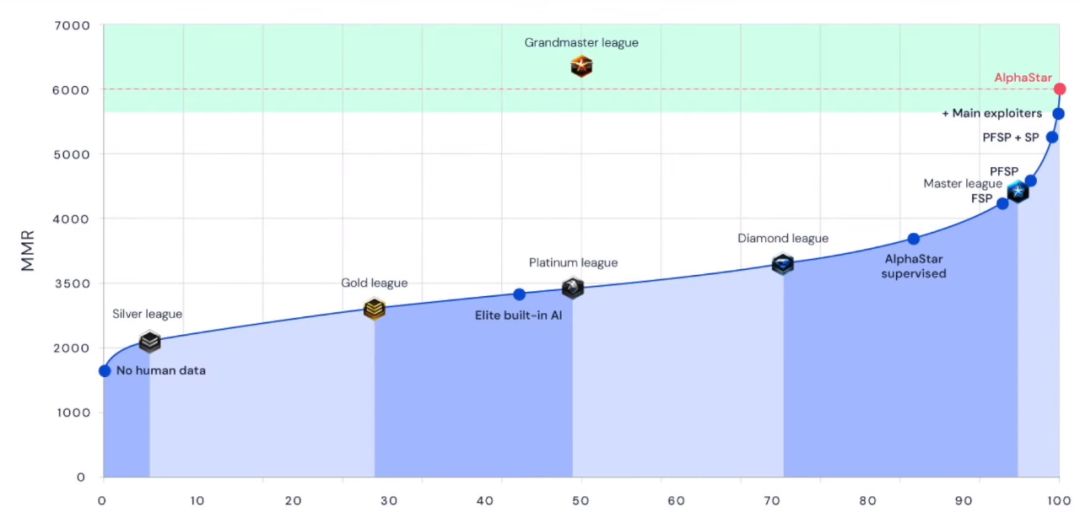
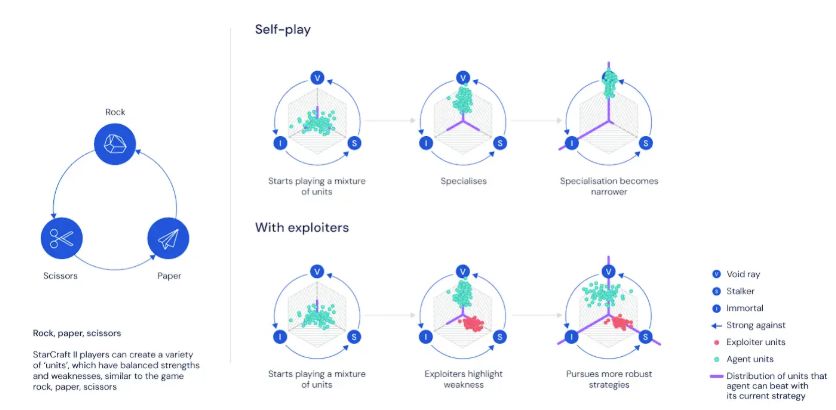
【新智元导读】闭关修炼9个月,DeepMind打造的《星际争霸2》游戏AI实现进化!新版的AlphaStar在官方战网真实对战中,使用3个种族均达到最高的“宗师”段位,表现超过了99.8%的人类活跃玩家。面对AI,竞技游戏领域人类玩家的生存空间越来越小了。来新智元 AI 朋友圈说说你的观点~


登录查看更多
相关内容

专知会员服务
131+阅读 · 2020年4月19日
Arxiv
5+阅读 · 2019年11月1日
Arxiv
5+阅读 · 2018年7月11日




相关VIP内容
专知会员服务
131+阅读 · 2020年4月19日
相关资讯
相关论文
Arxiv
5+阅读 · 2019年11月1日
Arxiv
5+阅读 · 2018年7月11日