AI魔方大师:1.2秒解魔方超世界纪录2倍,平均移动28步
看点:目前破解三阶魔方的世界纪录保持者,用时也需3.47秒。


导语:1.2秒是什么概念呢?要知道,目前破解三阶魔方的世界纪录保持者,用时也需3.47秒。
智东西7月16日消息。近日,加州大学欧文分校(University of California,Irvine,简称UCI)的研究人员研发出了一个名为DeepCubeA的AI算法,它利用深度强化学习(Deep Reinforcement Learning)的方法,可以在没有任何领域知识或人类游戏指导的情况下快速破解魔方,并且速度是人类极限的两倍。
在人类领域,第10届世界魔方协会(WCA)锦标赛于今年7月14日在墨尔本举行,来自德国的菲利普·威尔(Philipp Weyer)获得冠军,而他的成绩则是在6.74秒内解出3×3×3的魔方。
然而,目前该项世界纪录的保持者是来自中国的杜宇生,他只用了3.47秒就破解了这个难题。
DeepCubeA人工智能程序的研究成果已于美国时间2019年7月15日发表在《自然机器智能》杂志上,名为《用深度强化学习和搜索破解魔方(Solving the Rubik’s cube with deep reinforcement learning and search)》。

1.2秒内破解魔方,平均移动28步
该论文的第一作者、UCI的博士生Forest Agostinelli表示,DeepCubeA系统由一个深层神经网络组成,可以在1.2秒内破解魔方,平均移动28步。
在这项研究中,DeepCubeA算法能够破解100%随机打乱的魔方方块,并在60.3%的游戏时间里计算出最短的目标解决路径,将魔方的六个面都解成同一个颜色。
研究人员表示,该算法还适用于其他组合游戏,如15拼图、24拼图、35拼图、48拼图、Lights Out和推箱子游戏。
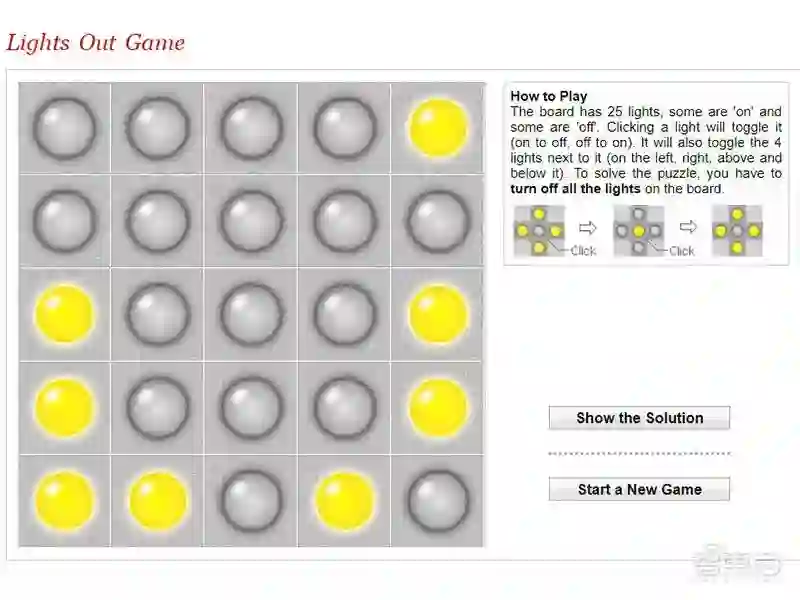
▲Lights Out游戏
UCI的计算机科学教授皮Pierre Baldi表示,这项研究为人们展示了一个人工智能系统,它可以自动学习如何破解标志性的魔方和其他类似的问题,这些问题的特点是有许多的可能性和非常少的解决方案,并且通过随机移动的方式也几乎无法提供解决方案。
用100亿个魔方组合进行训练
DeepCubeA是使用强化学习来进行训练的。
在这项研究中,研究人员想要了解人工智能是如何采取行动,以及需要多长时间才能完善自己的方法。
因此,研究人员先用电脑模拟出一个完整的魔方,然后将魔方打乱。DeepCubeA的任务则是需要尽快地找到最低的“功能成本”来破解方法,其中包括计算成本和移动量。
另一方面,由于魔方有大约43万亿个可能的组合,这使DeepCubeA随机开始进行训练是不实际的。因此,研究人员选择反向训练,将DeepCubeA放置于序列中的一个特殊状态,让它从已经破解的部分中开始进行深度强化学习。
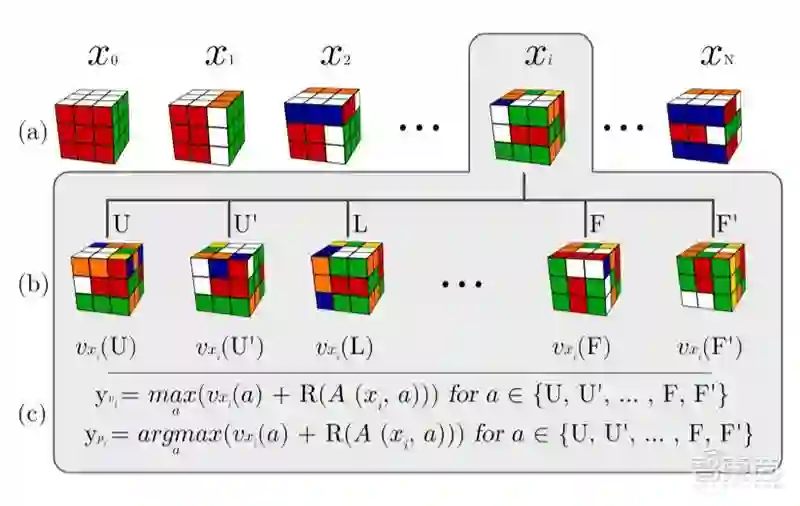
随后,研究人员用100亿个不同的魔方组合,对DeepCubeA进行了为期两天的隔离训练,并要求它在30步之内破解所有的魔方。
除此之外,研究人员还用1000个魔方难题对该算法进行测试,结果显示,该算法不仅解决了所有的难题,并且还能在60.3%的时间里,以最少的移动步数完成了测试。
Baldi表示,顶级魔方玩家需要大约50次移动,才能在4秒内破解魔方,但DeepCubeA可以在20步内完成,这证明了AI的策略和人类的推理策略是不同的。
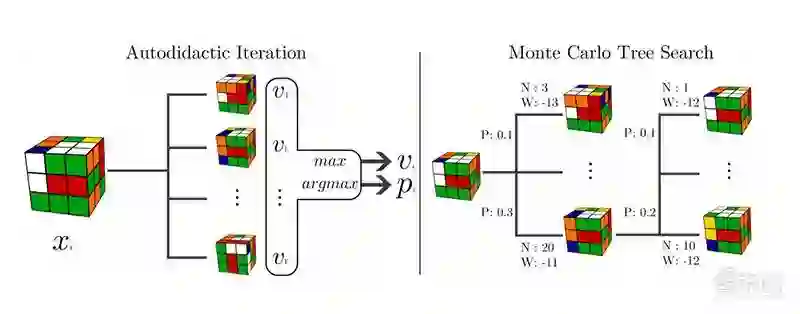
结合符号、数学和抽象思维
Baldi认为,虽然魔方是一个玩具,但破解魔方问题需要更多的符号、数学和抽象思维,因此一个能够破解魔方的深度学习机器,也将越来越接近成为一个能够思考、推理、计划和决策的系统。
“机器人和一些需要进行规划才能解决问题的其他领域也具有这些特征,”Baldi补充说。“想象一下,一个机器人负责清理厨房,它需要做出许多动作,但让厨房变得干净的步骤却很少,随意移动脏盘子的方法是行不通的。”
他还表示,从广泛层面来说,DeepCubeA能将机器学习AI和符号AI连接起来,以帮助人类进行规划和推理,以解决更多更复杂的问题。

▲魔方创造者Erno Rubik

结语:将为人们提供更高效的解决方案
一直以来,破解魔方都被人们认为是一个经典的规划问题。DeepCubeA的AI算法通过把神经网络与符号AI相结合,能够将复杂的环境提取为知识,并进行推理以解决问题。
DeepCubeA不仅是对人类速度领域的进一步超越,同时在未来的工作中,它也许能应用在其他具有复杂特征的各种问题中,例如机器人操作、蛋白质结构预测等领域,为人们提供更高效得解决方案。
论文连接:https://www.nature.com/articles/s42256-019-0070-z
文章来源:Forbes、The Registe
智东西公开课预告
7月17日起,AI推理公开课NVIDIA专场重磅开讲!从理论到代码,两节课带你掌握AI推理优化方法。扫码免费报名听课。







