作者:Yujun Shen、Bolei Zhou
机器之心编译
参与:蛋酱、魔王
无监督条件下,GAN 模型潜在语义的识别似乎是一件非常具有挑战性的任务。最近,香港中文大学周博磊等人提出了一种名为「SeFa」的方法,为该问题提供了更优解。
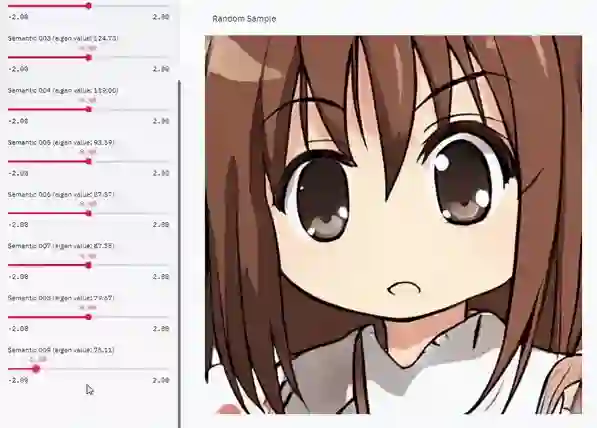
SeFa 方法能够识别出不同 GAN 模型的潜在语义,进而进行图像编辑。如下图所示:
![]()
除了动漫以外,SeFa 方法还可以处理场景、人物、动物、物体等不同的图像。
![]()
![]()
猫姿势的上下移动。需要注意的是,在图像变换过程中,我们可以看到,还是有伪影的存在。
![]()
![]()
接下来,我们来看该问题的难点以及 SeFa 方法的新颖之处。
生成对抗网络(GAN)在图像合成领域的应用已经十分广泛。近期的一些研究表明,在学习合成图像时,GAN 会自发地在潜在空间中表示出多种可解释属性,如用于人脸合成的性别特征、用于场景合成的光照条件。通过正确识别这些语义,我们可以将 GAN 学习到的知识重新利用,合理地控制图像生成过程,从而实现图像编辑功能的更广泛应用,如人脸操纵和场景编辑。
解释 GAN 潜在空间的关键点在于找到与人类可理解属性相对应的子空间。通过这种方法,将潜码(latent code)向特定子空间的方向移动,即可对应地改变合成图像的语义。然而,由于潜在空间的高维性以及图像语义的多样性,在潜在空间中寻找有效方向是极具挑战性的。
现有的监督学习方法通常先随机抽取大量潜码,然后合成一组图像,并使用一些预定义标签进行图像标注,最后利用这些标注样本学习潜在空间中的分离边界(separation boundary)。要想得到训练该边界的标签,要么引入预训练语义预测器,要么利用图像的一些简单统计信息。
港中文周博磊等人提出新方法「SeFa」,解释 GAN 内部表征
以往的方法严重依赖于预定义的语义和标注样本,存在局限性。最近,来自香港中文大学的研究者提出了一种新的生成方法,
不再将合成样本作为中间步骤,而是通过直接探索 GAN 的生成机制来解释其内部表征
。
![]()
论文地址:https://arxiv.org/pdf/2007.06600.pdf
代码地址:https://github.com/genforce/sefa
项目主页:https://genforce.github.io/sefa/
具体而言,对于所有基于神经网络的 GAN,第一步通常采用一个全连接层将潜码输入到生成器中,它提供了将潜在空间投影到变换空间(transformed space)的驱动力。这种变换实际上过滤了潜在空间中一些不重要的方向,从而突出了图像合成的关键方向。
能够识别这些重要的潜在方向,我们就能够控制图像生成过程,即编辑合成图像的语义。
在这篇论文中,研究者提出了一种新颖而简单的闭式方法「SeFa」,可用于 GAN 的潜在语义分解。现有方法通常使用三个步骤(采样、标注和边界搜索),而 SeFa 方法只需使用 GAN 模型学得的权重进行语义发现。
实验结果表明,
这一方法能够通过非常快速和高效的实现(1 秒内),识别通用的潜在语义
,在无监督条件下即可从不同类型的 GAN 模型中识别多种语义。具体方法可见论文。
下图展示了一些操作实例。即使我们不知道图像中对象的底层 3D 模型或姿态标签,也仍然进行旋转,并且该方法支持在 PGGAN、StyleGAN、BigGAN、StyleGAN2 等多个 GAN 模型中发现人类可理解的语义。
![]()
研究者在多个 SOTA GAN 模型上进行大量实验,以评估所提出方法的效果,这些模型包括 PGGAN、StyleGAN、BigGAN 和 StyleGAN2。这些模型在多个数据集上进行了训练,包括人脸(CelebA-HQ 和 FF-HQ)、动漫人脸、场景和物体(LSUN)、街景和 ImageNet 等。为了对人脸进行定量分析,研究者在之前研究 [23] 的基础上,使用 ResNet-50 在 CelebA 数据集上训练了一个属性预测器。
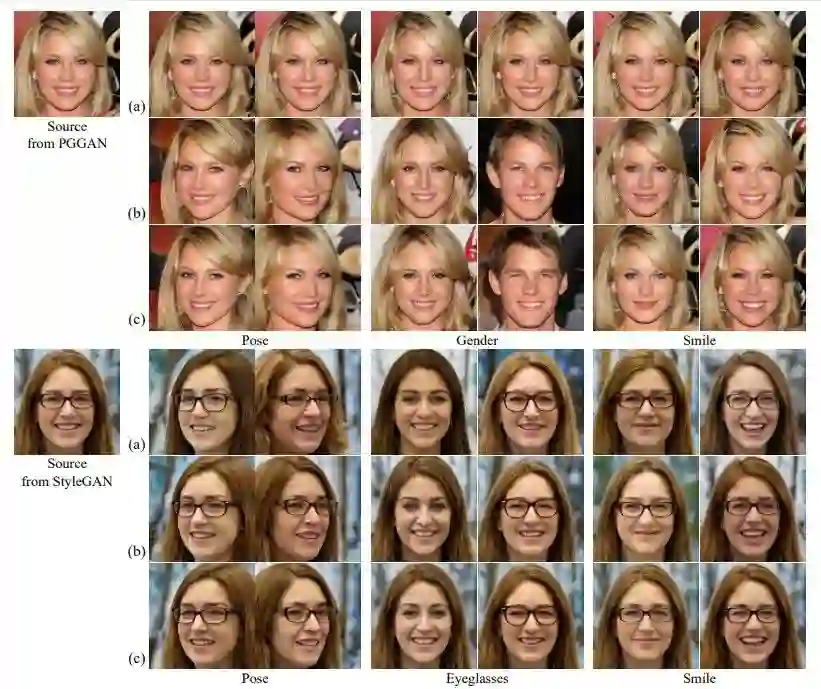
下图 3 展示了与基于采样的无监督方法之间的定性对比。
可以看出,SeFa 的生成结果(b 行)更接近于监督方法 InterFaceGAN(c 行)所生成的结果。例如在 StyleGAN 上使用 PCA 编辑姿势时,身份和发型会发生变化(a 行)。
![]()
图 3:语义定性对比。(a)基于采样的无监督方法 [10];(b)该研究提出的闭式方法 SeFa;(c)监督方法 InterFaceGAN。
以下图 4 为例,当使用 Info-PGGAN 进行编辑时,头发的颜色会发生变化。
![]()
图 4:Info-PGGAN (a) 和 SeFa (b) 发现语义的定性对比。
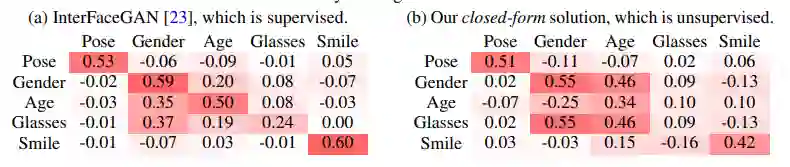
接下来,研究者对比了 SeFa 与监督学习 SOTA 方法 InterFaceGAN 在潜在语义发现方面的性能,具体而言从以下两个角度进行分析:(a)在分离语义方面的区别,(b)识别语义的多样性。
![]()
表 2 展示了通过评估语义得分随潜码调整而发生的变化,对不同方法进行重新评分分析。每一行展示了将潜码朝某个方向移动的结果。
在下图 5 中,研究者将本文方法与监督方法 InterFaceGAN 进行对比。如图 5 (a) 所示,SeFa 成功地识别了与发色、发型和肤色这些要素对应的方向。同时该方法还可以识别更复杂的属性 ,如图 5 (b) 中的不同发型。
![]()
图 5:a)多样化的语义,InterFaceGAN 因缺乏语义预测期而无法识别;b)无法用二元属性描述的不同发型。
随后,研究者将 GAN 逆映射方法引入到这项工作中,以实现真实图像的处理。具体而言,给定一个待编辑的目标图像,我们首先将它投影到潜码,然后使用发现的潜在语义来调整逆代码。
如下图 6 所示,该研究提出的闭式方法所发现的语义是足够精确的,可以操纵真实的图像。例如,研究人员设法在输入图像中添加或删除眼镜(图 6 的第四列)。
![]()
图 6:对真实图像进行不同面部属性的处理。所有语义都是用 SeFa 找到的,GAN 逆映射用于将作为目标的真实图像投影回 StyleGAN 的潜在空间。
这部分验证了 SeFa 算法的泛化能力,即应用到在不同数据集上训练的各类 SOTA GAN 模型的效果。
![]()
图 7:从基于风格的生成器中发现的层级语义。其中街景模型使用了 StyleGAN2 进行训练,其他模型使用了 StyleGAN。
![]()
图 8:从 BigGAN 中发现的多样性语义,该模型在 ImageNet 上进行了有条件的训练。这些语义被进一步用于处理不同类别的图像。
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。
![]()