学界 | 史上最大的实体关系抽取数据集!清华大学自然语言处理团队发布 FewRel

AI 科技评论按,在去年的 EMNLP2018 上,由孙茂松教授领导的清华大学自然语言处理实验室发布了一个大规模精标注关系抽取数据集 FewRel。据了解,这是目前最大的精标注关系抽取数据集。
该数据集包含 100 个类别、70,000 个实例,全面超越了以往的同类精标注数据集。FewRel 不仅可以应用在经典的监督/远监督关系抽取任务中,在新兴的少次学习(few-shot learning)任务上也有极大的探索价值和广阔的应用前景。
团队还发布了论文《FewRel: A Large-Scale Supervised Few-Shot Relation Classification Dataset with State-of-the-Art Evaluation》,该论文由清华大学自然语言处理实验室的博士生韩旭、姚远,本科生朱昊、于鹏飞、王子云共同合作完成。文章对 FewRel 数据集的构造原理给出了详细解释,感兴趣的童鞋可以点击下面的论文地址阅读原文:
FewRel 网站地址:https://thunlp.github.io/fewrel.html
论文地址:http://aclweb.org/anthology/D18-1514
关系抽取(relation extraction)是自然语言处理中的一项重要任务,其通过从纯文本中抽取关系事实,来构建和扩充知识图谱(knowledge graph)。例如,从句子「马云创办了阿里巴巴」中,可以抽取出关系事实(马云, 创始人, 阿里巴巴),其中马云和阿里巴巴被称为实体(entity),而创始人则是他们的关系(relation)。关系抽取是知识获取的重要途径,对于理解自然语言和理解世界知识意义重大。
目前的关系抽取模型面临着一个极大的问题:训练数据不足。相比计算机视觉中的相关任务,语言相关的标注更加困难,需要标注者掌握相应的知识。就如下表 1 中所示,已有精标注关系抽取数据集在关系数量和实例数量上都较少,这极大限制了关系抽取的发展。

表 1:常用精标关系抽取数据集对比
作为目前关系抽取领域最大的精标注数据集,FewRel 中有 100 类关系,共 70,000 个实例,是很好的实验数据集。此前,加州大学圣巴巴拉分校计算机科学系助理教授王威廉实验室与IBM合作的 NAACL 2019 论文 Sentence Embedding Alignment for Lifelong Relation Extraction 就用到了这个数据集。(论文查看地址:http://t.cn/EMQDhMb)
FewRel 是以 Wikipedia 作为语料库,以 Wikidata 作为知识图谱构建的。

图 1: Wikidata 和 Wikipedia(图来自 Wikidata 和 Wikipedia 官网)
Wikipedia 作为互联网上的自由百科全书,因其巨大的体量和蕴含的丰富知识而备受 NLP 学者青睐。与其相对应的知识图谱 Wikidata,则是 Wikipedia 中知识的结构化。目前 Wikidata 中已有超过 5000 万个实体,千余种关系。
清华大学自然语言处理实验室数据集团队首先利用这两者构造了一个远监督的数据集。那么,什么是远监督?知识图谱中已经包含了许多实体以及他们之间的关系,我们可以假设,若两个实体 h 和 t 间有关系 r,而一个句子中同时出现了 h 和 t,则该句子表达了它们之间的关系 r。通过这种方法可以自动获得大规模的标注数据,然而这一数据是充满噪声的,几乎无法直接用来训练模型。在远监督数据集的基础上,去掉出现重复实体对的句子,去掉少于 1000 个样本的类,最终留下 122 类,共 122,000 个实例,然后进行人工标注。
在这一过程中,每个实例都会有多个标注员进行标注,通过冗余保证标注质量。在此之后再进行一轮质量筛选,最后留下 100 类,共 70,000 句高质量标注的关系抽取数据。最终数据集中,每句的平均长度为 24.99,一共出现 124,577 个不同的单词/符号。
据了解,FewRel 的意义不仅仅是一个大规模的数据集。因为关系数量的众多,学界可以在 FewRel 上进行更多维度的探索,其中很重要的一个方向就是少次学习(few-shot learning)。人可以接触很少的例子而学会认知一种新的事物,从这一点出发,深度学习模型能否具备从少量样本中快速学习的能力呢?目前在 CV 领域已有了很多这方面的尝试,但在 NLP 当中,尤其是关系抽取上,还缺乏类似的探索。尤其因为以往的关系抽取数据集关系数量和实例数量较少,而通常 few-shot 模型需要在大规模数据上预训练,需要在类别较多的数据上做 sample 评测,所以很难开展相关工作。
FewRel 的出现打开了少例关系抽取的大门,其名字中的 Few 也正是取自 Few-shot。通过下面的表 2 我们可以看到,FewRel 与 CV 中的 few-shot 数据集 mini-ImageNet 具有相同的规模,可见其足以支撑相关的研究。
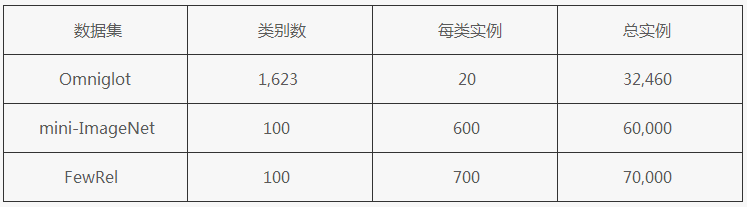
表 2:FewRel 与两个 CV 中 Few-Shot 数据集对比
除此之外,FewRel 还可以帮助科研人员进行需要较多关系类别的相关研究,终身学习(lifelong learning)就是其中一个方向。目前大部分关系抽取模型都是在预先定义好的类别中进行探索,而我们知道,世界知识是不断增长的,关系数量也不是停滞的,如何让一个模型能不断接收新的训练样本,同时不至遗忘之前的知识,是一个十分值得探索的课题。而相关实验需要有大量关系类别的精标数据,FewRel 正好满足条件。
据了解,未来 FewRel 团队还将公开其构建数据集时所使用的基于 Wikipedia 的远监督数据,将远监督数据与精标数据相结合,研究人员可以进一步探索远监督的降噪机制,以及如何使用两种数据进行半监督学习。
由于精标数据可以被视作「种子」,远监督数据可以被看作巨大的语料库,FewRel 还可以用在主动学习(active learning)和自启动算法(bootstrapping)方面的研究中。然而,近几年来,在关系抽取领域少有人进行类似探索,其原因就是数据集的缺乏。伴随着 FewRel 的出现,相信接下来这些重要方向的研究必然会有所推进。
点击阅读原文,查看清华大学刘知远老师相关文章




