【清华大学】知识图谱从哪里来:实体关系抽取的现状与未来
知识图谱
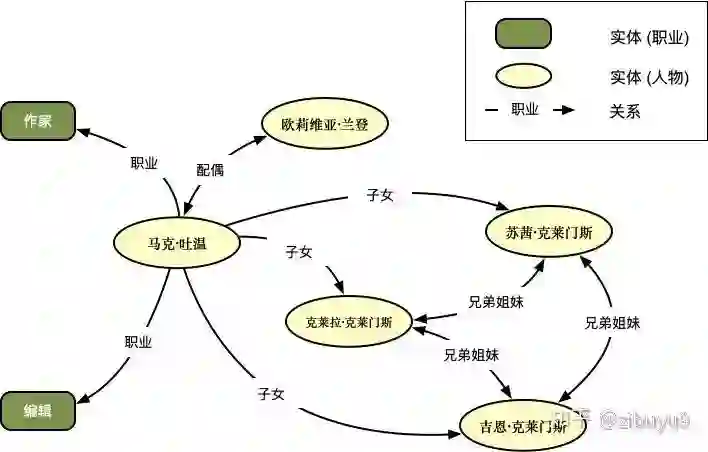

实体关系抽取是一个经典任务,在过去的20多年里都有持续研究开展,特征工程、核方法、图模型曾被广泛应用其中,取得了一些阶段性的成果。随着深度学习时代来临,神经网络模型则为实体关系抽取带来了新的突破。
神经网络关系抽取模型
面向自然语言文本序列已经有很多神经网络类型,例如循环神经网络(RNN、LSTM)、卷积神经网络(CNN)和Transformer等,这些模型都可以通过适当改造用于关系抽取。最初,工作 [1,2] 首次提出使用CNN对句子语义进行编码,用于关系分类,比非神经网络方法比性能显著提升;工作 [3,4] 将RNN与LSTM用于关系抽取;此外,工作 [5] 提出采用递归的神经网络对句子的语法分析树建模,试图在提取语义特征的同时考虑句子的词法和句法特征,这个想法也被不少后续工作的进一步探索。这里,我们列出一个表格,总结各类典型神经网络在基准测试数据集合SemEval-2010 Task-8 [6] 上的效果。
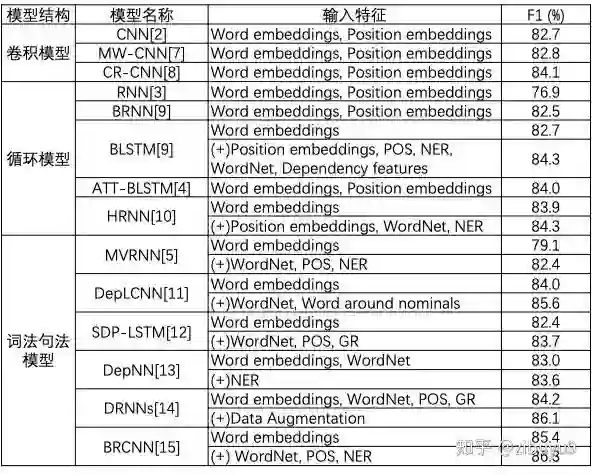
从上表可以看出,这些神经网络模型均取得了优异的实验结果,且相互之间没有显著的性能差异。这是否意味着关系抽取问题就此解决了呢?实际上并非如此。SemEval-2010 Task-8的任务设定为,对预先定义好的关系类别标注大量的训练和测试样例,样例都是相对简单的短句,而且每种关系的样例分布也比较均匀。然而,实际应用中往往面临很多挑战:
数据规模问题:人工精准地标注句子级别的数据代价十分高昂,需要耗费大量的时间和人力。在实际场景中,面向数以千计的关系、数以千万计的实体对、以及数以亿计的句子,依靠人工标注训练数据几乎是不可能完成的任务。
学习能力问题:在实际情况下,实体间关系和实体对的出现频率往往服从长尾分布,存在大量的样例较少的关系或实体对。神经网络模型的效果需要依赖大规模标注数据来保证,存在”举十反一“的问题。如何提高深度模型的学习能力,实现”举一反三“,是关系抽取需要解决的问题。
复杂语境问题。现有模型主要从单个句子中抽取实体间关系,要求句子必须同时包含两个实体。实际上,大量的实体间关系往往表现在一篇文档的多个句子中,甚至在多个文档中。如何在更复杂的语境下进行关系抽取,也是关系抽取面临的问题。
开放关系问题。现有任务设定一般假设有预先定义好的封闭关系集合,将任务转换为关系分类问题。这样的话,文本中蕴含的实体间的新型关系无法被有效获取。如何利用深度学习模型自动发现实体间的新型关系,实现开放关系抽取,仍然是一个”开放“问题。
所以说,SemEval-2010 Task-8这样的理想设定与实际场景存在巨大鸿沟,仅依靠神经网络提取单句语义特征,难以应对关系抽取的各种复杂需求和挑战。我们亟需探索更新颖的关系抽取框架,获取更大规模的训练数据,具备更高效的学习能力,善于理解复杂的文档级语境信息,并能方便地扩展至开放关系抽取。
我们认为,这四个方面构成了实体关系抽取需要进一步探索的主要方向。接下来,我们分别介绍这四个方面的发展现状和挑战,以及我们的一些思考和努力。
更大规模的训练数据
神经网络关系抽取需要大量的训练数据,但是人工标注这些训练数据非常费时昂贵。为了自动获取更多的训练数据训练模型,工作 [16] 提出了远程监督(Distant Supervision)的思想,将纯文本与现有知识图谱进行对齐,能够自动标注大规模训练数据。
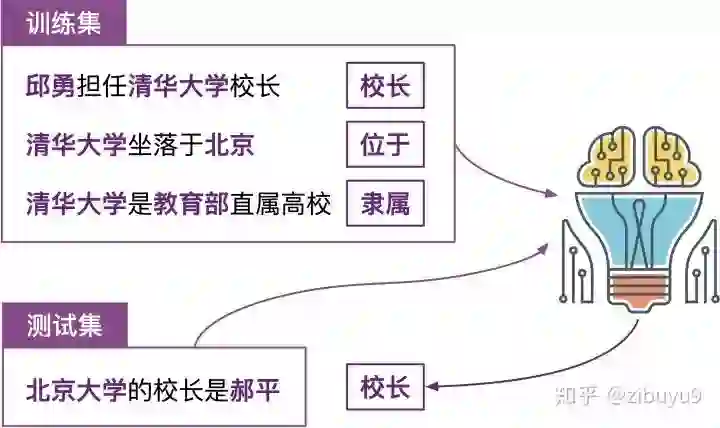
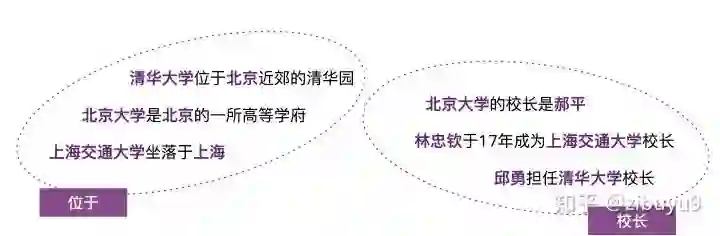
远程监督的思想并不复杂,具体来说:如果两个实体在知识图谱中被标记为某个关系,那么我们就认为同时包含这两个实体的所有句子也在表达这种关系。再以(清华大学,位于,北京)为例,我们会把同时包含“清华大学”和“北京”两个实体的所有句子,都视为“位于”这个关系的训练样例。
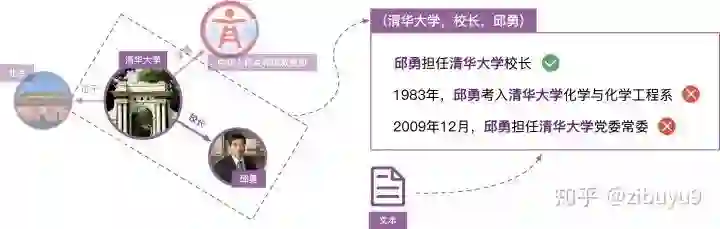
远程监督的这种启发式标注规则是把双刃剑,它是自动标注训练数据的有效策略,但其过强的设定不可避免地产生错误标注。例如对于知识图谱中(清华大学,校长,邱勇)这个三元组事实,句子“邱勇担任清华大学校长”可以反映“清华大学”与“邱勇”之间“校长”的关系;但是句子“邱勇考入清华大学化学与化学工程系”以及“邱勇担任清华大学党委常委”并不表达“校长”关系,但却会被远程监督的启发式规则错误地标注为“校长”关系的训练实例。
虽然远程监督思想非常简单也存在很多问题,不过它为更多收集训练数据开启了新的纪元。受到这个思路的启发,很多学者积极考虑如何尽可能排除远程监督数据中的噪音标注的干扰。从2015年开始,基于远程监督与降噪机制的神经关系抽取模型得到了长足的发展,工作 [17] 引入了多实例学习方法,利用包含同一实体对的所有实例来共同预测实体间关系。我们课题组林衍凯等人工作 [19] 提出句子级别注意力机制,对不同的实例赋予不同的权重,用以降低噪音实例造成的影响。工作 [20] 引入对抗训练来提升模型对噪音数据的抵抗能力。工作 [21] 则构建了一套强化学习机制来筛除噪音数据,并利用剩余的数据来训练模型。
总结来说,已有对远程监督的降噪方法可以兼顾了关系抽取的鲁棒性与有效性,也具有较强的可操作性和实用性。不过,使用已有知识图谱对齐文本来获取数据训练关系抽取模型,再利用该模型来抽取知识加入知识图谱,本身就有一种鸡生蛋与蛋生鸡的味道。不完善的知识图谱对齐所得到的文本训练数据也将是不完善的,对那些长尾知识而言,仍难以通过这种远程监督机制来得到训练实例。如何提出更有效的机制来高效获取高质量、高覆盖、高平衡的训练数据,仍然是一个值得深入思考的问题。
更高效的学习能力
即使通过远程监督等办法能够自动获取高质量的训练数据,由于真实场景中关系和实体对的长尾分布特点,绝大部分的关系和实体对的可用样例仍然较少。而且,对于医疗、金融等专业领域的专门关系,受限于数据规模的问题可用样例也很有限。而神经网络模型作为典型的data-hungry技术,在训练样例过少时性能会受到极大影响。因此,研究者们希望探索有效提升模型学习能力的方法,以更好地利用有限训练样例取得满意的抽取性能。
实际上,人类可以通过少量样本快速学习知识,具有“举一反三”的能力。为了探索深度学习和机器学习“举一反三”的能力,提出了少次学习(Few-shot learning)任务。通过设计少次学习机制,模型能够利用从过往数据中学到的泛化知识,结合新类型数据的少量训练样本,实现快速迁移学习,具有一定的举一反三能力。
过去少次学习研究主要集中于计算机视觉领域,自然语言处理领域还少有探索。我们课题组韩旭同学等的工作 [21] 首次将少次学习引入到关系抽取,构建了少次关系抽取数据集FewRel,希望推动驱动自然语言处理特别是关系抽取任务的少次学习研究。如下图所示,关系抽取少次学习问题仅为每种关系提供极少量样例(如3-5个),要求尽可能提高测试样例上的关系分类效果。
FewRel论文工作初步尝试了几个代表性少次学习方法包括度量学习(Metric learning)、元学习(Meta learning)、参数预测(Parameter prediction)等,评测表明即使是效果最佳的原型网络(Prototypical Networks)模型,在少次关系抽取上的性能仍与人类表现相去甚远。
为了更好解决远程监督关系抽取的少次学习问题,我们课题组的高天宇同学等的工作 [22] 提出了基于混合注意力机制的原型网络,同时考虑实例级别和特征级别的注意力机制,在减少噪音标注影响的同时,能更好地关注到句中的有用特征,实现高效少次学习。工作 [24] 则提出多级匹配和整合结构,充分学习训练样例之间的潜在关联,尽可能挖掘为数不多的样例中的潜在信息。工作 [24] 则采用了预训练语言模型BERT来处理关系抽取中的少次学习问题,基于海量无监督数据训练的BERT,能够为少次学习模型提供有效的语义特征,在FewRel数据上取得了超过人类关系分类的水平。
在对少次学习关系抽取探究的过程中,课题组的高天宇同学等进一步发现两个长期被忽视的方面 [25]:要将少次学习模型用于生产环境中,应具备从资源丰富领域迁移到资源匮乏领域(low-resource domains)的能力,同时还应具备检测句子是否真的在表达某种预定义关系或者没有表达任何关系的能力。为此他们提出了FewRel 2.0,在原版数据集FewRel的基础上增加了以下两大挑战:领域迁移(domain adaptation)和“以上都不是”检测(none-of-the-above detection)。
对于领域迁移挑战,FewlRel 2.0 采集了大量医疗领域的数据并进行标注,要求关系抽取模型在原语料进行训练后,还可以在这些新领域语料上进行少次学习。对于“以上都不是”检测,FewRel 2.0 在原N-way K-shot设定(给定N个新类型,每个类型给定K个训练样本)上,添加了一个“以上都不是”选项,大大增加了分类和检测难度。
初步实验发现,以往有效的模型(包括基于BERT的模型)在这两大挑战任务均有显著性能下降。尽管高天宇同学等在FewRel 2.0论文中也尝试了一些可能的解决思路:例如对于领域迁移尝试了经典的对抗学习方法,模型性能得到了一定的提升;对于“以上都不是”检测,提出了基于BERT next sentence prediction task的BERT-PAIR模型,可以在”以上都不是”挑战取得一点效果。但这两大挑战依然需要更多创新探索。
总结来说,探索少次学习关系抽取,让关系抽取模型具备更强大高效的学习能力,还是一个非常新兴的研究方向,特别是面向关系抽取的少次学习问题,与其他领域的少次学习问题相比,具有自身独有的特点与挑战。不论是基于已有少次学习技术作出适于NLP和关系抽取的改进,还是提出全新的适用于关系抽取的少次学习模型,都将最大化地利用少量标注数据,推动关系抽取技术的落地实用。
更复杂的文本语境
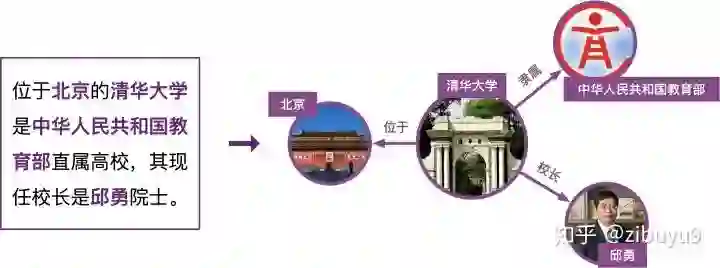
现有关系抽取工作主要聚焦于句子级关系抽取,即根据句内信息进行关系抽取,各类神经网络模型也擅长编码句子级语义信息,在很多公开评测数据能够取得最佳效果。而在实际场景中,大量的实体间关系是通过多个句子表达的。如下图所示,文本中提到多个实体,并表现出复杂的相互关联。根据从维基百科采样的人工标注数据的统计表明,至少40%的实体关系事实只能从多个句子中联合获取。为了实现多个实体间的跨句关系抽取,需要对文档中的多个句子进行阅读推理,这显然超出了句子级关系抽取方法的能力范围。因此,进行文档级关系抽取势在必行。
文档级关系抽取研究需要大规模人工标注数据集来进行训练和评测。目前文档级关系抽取数据集还很少。工作 [26,27] 构建了两个远程监督的数据集,由于没有进行人工标注因此评测结果不太可靠。BC5CDR [28] 是人工标注的文档级关系抽取数据集,由1,500篇PubMed文档构成是生物医学特定领域,且仅考虑“化学诱导的疾病”关系,不一定适合用来探索文档级关系抽取的通用方法。工作 [29] 提出使用阅读理解技术回答问题的方式从文档中提取实体关系事实,这些问题从”实体-关系“对转换而来。由于该工作数据集是针对这种方法量身定制的,也不那么适用于探索文档级关系抽取的通用方法。这些数据集或者仅具有少量人工标注的关系和实体,或者存在来自远程监督的噪音标注,或者服务于特定领域或方法,有这样或那样的限制。
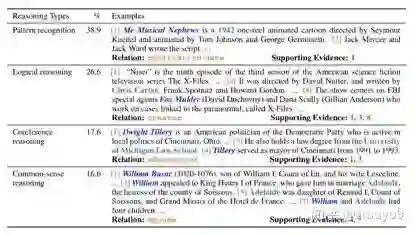
为了推动文档级关系抽取的研究,课题组姚远同学等 [30] 提出了DocRED数据集,是一个大规模的人工标注的文档级关系抽取数据集,基于维基百科正文和WikiData知识图谱构建而成,包含5,053篇维基百科文档,132,375 个实体和53,554 个实体关系事实,是现有最大的人工标注的文档级关系抽取数据集。如下图所示,文档级关系抽取任务要求模型具有强大的模式识别、逻辑推理、指代推理和常识推理能力,这些方面都亟待更多长期的研究探索。
更开放的关系类型
现有关系抽取工作一般假设有预先定义好的封闭关系集合,将任务转换为关系分类问题。然而在开放域的真实关系抽取场景中,文本中包含大量开放的实体关系,关系种类繁多,而且关系数量也会不断增长,远超过人为定义的关系种类数量。在这种情况下,传统关系分类模型无法有效获取文本中蕴含的实体间的新型关系。如何利用深度学习模型自动发现实体间的新型关系,实现开放关系抽取,仍然是一个”开放“问题。

为了实现面向开放领域的开放关系抽取,研究提出开放关系抽取(Open Relation Extraction,OpenRE)任务,致力于从开放文本抽取实体间的任意关系事实。开放关系抽取涉及三方面的“开放”:首先是抽取关系种类的开放,与传统关系抽取不同,它希望抽取所有已知和未知的关系;其次是测试语料的开放,例如新闻、医疗等不同领域,其文本各有不同特点,需要探索跨域鲁棒的算法;第三是训练语料的开放,为了获得尽可能好的开放关系抽取模型,有必要充分利用现有各类标注数据,包括精标注、远程监督标注数据等,而且不同训练数据集的关系定义和分布也有所不同,需要同时利用好多源数据。
在前深度学习时代,研究者也有探索开放信息抽取(Open Information Extraction,OpenIE)任务。开放关系抽取可以看做OpenIE的特例。当时OpenIE主要通过无监督的统计学习方法实现,如Snowball算法等。虽然这些算法对于不同数据有较好的鲁棒性,但精度往往较低,距离实用落地仍然相距甚远。
最近,课题组吴睿东同学等的工作 [31] 提出了一种有监督的开放关系抽取框架,可以通过”关系孪生网络“(Relation Siamese Network,RSN)实现有监督和弱监督模式的自由切换,从而能够同时利用预定义关系的有监督数据和开放文本中新关系的无监督数据,来共同学习不同关系事实的语义相似度。具体来说,关系孪生网络RSN采用孪生网络结构,从预定义关系的标注数据中学习关系样本的深度语义特征和相互间的语义相似度,可用于计算包含开放关系文本的语义相似度。而且,RSN还使用了条件熵最小化和虚拟对抗训练两种半监督学习方法进一步利用无标注的开放关系文本数据,进一步提高开放关系抽取的稳定性和泛化能力。基于RSN计算的开放关系相似度计算结果,模型可以在开放域对文本关系进行聚类,从而归纳出新型关系。
课题组高天宇同学等人工作 [32] 则从另一个角度出发,对于开放域的特定新型关系,只需要提供少量精确的实例作为种子,就可以利用预训练的关系孪生网络进行滚雪球(Neural SnowBall),从大量无标注文本中归纳出该新型关系的更多实例,不断迭代训练出适用于新型关系的关系抽取模型。
总结来说,开放域关系抽取在前深度学习时代取得了一些成效,但如何在深度学习时代与神经网络模型优势相结合,有力拓展神经网络关系抽取模型的泛化能力,值得更多深入探索。
总结
为了更及时地扩展知识图谱,自动从海量数据中获取新的世界知识已成为必由之路。以实体关系抽取为代表的知识获取技术已经取得了一些成果,特别是近年来深度学习模型极大地推动了关系抽取的发展。但是,与实际场景的关系抽取复杂挑战的需求相比,现有技术仍有较大的局限性。我们亟需从实际场景需求出发,解决训练数据获取、少次学习能力、复杂文本语境、开放关系建模等挑战问题,建立有效而鲁棒的关系抽取系统,这也是实体关系抽取任务需要继续努力的方向。
我们课题组从2016年开始耕耘实体关系抽取任务,先后有林衍凯、韩旭、姚远、曾文远、张正彦、朱昊、于鹏飞、于志竟成、高天宇、王晓智、吴睿东等同学在多方面开展了研究工作。去年在韩旭和高天宇等同学的努力下,发布了OpenNRE工具包 [33],经过近两年来的不断改进,涵盖有监督关系抽取、远程监督关系抽取、少次学习关系抽取和文档级关系抽取等丰富场景。此外,也花费大量科研经费标注了FewRel (1.0和2.0)和DocRED等数据集,旨在推动相关方向的研究。
本文总结了我们对实体关系抽取现状、挑战和未来发展方向的认识,以及我们在这些方面做出的努力,希望能够引起大家的兴趣,对大家有些帮助。期待更多学者和同学加入到这个领域研究中来。当然,本文没有提及一个重要挑战,即以事件抽取为代表的复杂结构的知识获取,未来有机会我们再专文探讨。
限于个人水平,难免有偏颇舛误之处,还请大家在评论中不吝指出,我们努力改进。需要说明的是,我们没想把这篇文章写成严谨的学术论文,所以没有面面俱到把每个方向的所有工作都介绍清楚,如有重要遗漏,还请批评指正。

广告时间
我们课题组在实体关系抽取方面开展的多项工作(如FewRel、DocRED等)是与腾讯微信模式识别中心团队合作完成的。微信模式识别中心是微信AI(WeChat AI)下辖的中心之一,主要关注自然语言处理相关的研究和产品。研究方面,他们的研究工作涵盖对话系统、知识学习、认知推理、机器翻译等多个方向,今年在ACL、EMNLP、AAAI等会议上发表论文20多篇,也在多个比赛中获得优异成绩,学术成果颇丰。产品方面,他们开发的小微对话系统和微信对话开放平台在音箱、公众号自动客服等场景方面也有不俗的表现,但投入的人力比亚马逊Alex团队要少得多,也算是对微信“小”团队做大事风格的一种体现。微信模式识别中心团队学术与产品双强的特点也为我们的合作带来了不一样的体验,一方面双方都对世界前沿技术的研究保持了高度的热情,能够一起勠力同心做一些需要时间打磨、但影响深远的探索,另一方面真实的产品也为我们的研究提供了不同的视角和应用的场景,真正做到了强强联合、优势互补,是非常值得合作的团队。
我们与腾讯微信的这些合作是基于“清华-腾讯联合实验室”开展的。我们与腾讯高校合作中心合作多年,参与了包括清华-腾讯联合实验室(与清华各院系开展合作的学校级平台)、犀牛鸟专项基金(面向各类老师的前沿探索研究性项目)、犀牛鸟精英人才培养计划(面向学生,腾讯和清华双导师联合在腾讯培养科研型人才)等项目。感谢腾讯高校合作中心为高校与腾讯搭建的协作共赢的产学研合作平台,大家可以关注腾讯高校合作微信公众号Tencent_UR了解最新信息。
这里还要特别介绍我们与微信模识中心的对接人Patrick Li(由于不可言说的原因只好用他英文名,并非为了装B)和林衍凯。Patrick是我的师弟,跟我已经有十几年的交情,清华贵系2005级本科生,2009级博士生。他从本科时就加入我们课题组,当时我与他合作发表了我的第一篇EMNLP 2009论文,后来他来我们课题组读博,跟随孙茂松老师和刘洋老师从事机器翻译研究,做出很多有影响力的成果。他是我们合作项目的负责人,目前在微信模式识别中心负责领导NLP基础技术的研究和应用工作,在技术和人品方面都可谓有口皆碑,与他合作过的同学都印象深刻。现在,他主要关注自动问答、信息抽取、机器翻译等方面工作。也许正是受到Patrick的”感召“,我们组的林衍凯同学(nlp.csai.tsinghua.edu.cn)今年博士毕业后,也选择加入了他们团队,也在和我们一起合作开展知识图谱和自动问答方面的研究工作。
图穷匕见,读者中如果有希望找自然语言处理和知识图谱方面实习或工作的同学,欢迎联系Patrick Li(patrickpli@tencent.com),让我们共同努力,开展有意思有意义的研究工作。

作者简介
韩旭,清华大学计算机科学与技术系博士三年级同学,主要研究方向为自然语言处理、知识图谱、信息抽取。在人工智能领域国际著名会议AAAI、ACL、EMNLP、COLING、NAACL上发表多篇论文,是OpenKE、OpenNRE等开源项目的开发者之一。主页:
高天宇,清华大学计算机系大四本科生,主要研究方向为自然语言处理、知识图谱、关系抽取。在人工智能领域国际著名会议AAAI、EMNLP上发表多篇论文,是OpenNRE等开源项目的主要开发者之一。主页:

刘知远,清华大学计算机系副教授、博士生导师。主要研究方向为表示学习、知识图谱和社会计算。主页:

参考文献
[1] ChunYang Liu, WenBo Sun, WenHan Chao, Wanxiang Che. Convolution Neural Network for Relation Extraction. The 9th International Conference on Advanced Data Mining and Applications (ADMA 2013).
[2] Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, Jun Zhao. Relation Classification via Convolutional Deep Neural Network. The 25th International Conference on Computational Linguistics (COLING 2014).
[3] Dongxu Zhang, Dong Wang. Relation Classification via Recurrent Neural Network. arXiv preprint arXiv:1508.01006 (2015).
[4] Peng Zhou, Wei Shi, Jun Tian, Zhenyu Qi, Bingchen Li, Hongwei Hao, Bo Xu. Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification. The 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016).
[5] Richard Socher, Brody Huval, Christopher D. Manning, Andrew Y. Ng. Semantic Compositionality through Recursive Matrix-Vector Spaces. The 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL 2012).
[6] Iris Hendrickx, Su Nam Kim, Zornitsa Kozareva, Preslav Nakov, Diarmuid Ó Séaghdha, Sebastian Padó, Marco Pennacchiotti, Lorenza Romano, Stan Szpakowicz. SemEval-2010 Task 8: Multi-Way Classification of Semantic Relations between Pairs of Nominals. The 5th International Workshop on Semantic Evaluation (SEMEVAL 2010).
[7] Thien Huu Nguyen, Ralph Grishman. Relation Extraction: Perspective from Convolutional Neural Networks. The 1st Workshop on Vector Space Modeling for Natural Language Processing (LatentVar 2015).
[8] Cícero dos Santos, Bing Xiang, Bowen Zhou. Classifying Relations by Ranking with Convolutional Neural Networks. The 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2015).
[9] Shu Zhang, Dequan Zheng, Xinchen Hu, Ming Yang. Bidirectional Long Short-Term Memory Networks for Relation Classification. The 29th Pacific Asia Conference on Language, Information and Computation (PACLIC 2015).
[10] Minguang Xiao, Cong Liu. Semantic Relation Classification via Hierarchical Recurrent Neural Network with Attention. The 26th International Conference on Computational Linguistics (COLING 2016).
[11] Kun Xu, Yansong Feng, Songfang Huang, Dongyan Zhao. Semantic Relation Classification via Convolutional Neural Networks with Simple Negative Sampling. The 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP 2015).
[12] Yan Xu, Lili Mou, Ge Li, Yunchuan Chen, Hao Peng, Zhi Jin. Classifying Relations via Long Short Term Memory Networks along Shortest Dependency Paths. The 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP 2015).
[13] Yang Liu, Furu Wei, Sujian Li, Heng Ji, Ming Zhou, Houfeng Wang. A Dependency-Based Neural Network for Relation Classification. The 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2015).
[14] Yan Xu, Ran Jia, Lili Mou, Ge Li, Yunchuan Chen, Yangyang Lu, Zhi Jin. Improved Relation Classification by Deep Recurrent Neural Networks with Data Augmentation. The 26th International Conference on Computational Linguistics (COLING 2016).
[15] Rui Cai, Xiaodong Zhang, Houfeng Wang. Bidirectional Recurrent Convolutional Neural Network for Relation Classification. The 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016).
[16] Mike Mintz, Steven Bills, Rion Snow, Daniel Jurafsky. Distant Supervision for Relation Extraction without Labeled Data. The 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2009).
[17] Daojian Zeng, Kang Liu, Yubo Chen, Jun Zhao. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. The 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP 2015).
[18] Yankai Lin, Shiqi Shen, Zhiyuan Liu, Huanbo Luan, Maosong Sun. Neural Relation Extraction with Selective Attention over Instances. The 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016).
[19] Yi Wu, David Bamman, Stuart Russell. Adversarial Training for Relation Extraction. The 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP 2017).
[20] Jun Feng, Minlie Huang, Li Zhao, Yang Yang, Xiaoyan Zhu. Reinforcement Learning for Relation Classification from Noisy Data. The 32th AAAI Conference on Artificial Intelligence (AAAI 2018).
[21] Xu Han, Hao Zhu, Pengfei Yu, Ziyun Wang, Yuan Yao, Zhiyuan Liu, Maosong Sun. FewRel: A Large-Scale Supervised Few-Shot Relation Classification Dataset with State-of-the-Art Evaluation. The 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP 2018).
[22] Tianyu Gao, Xu Han, Zhiyuan Liu, Maosong Sun. Hybrid Attention-based Prototypical Networks for Noisy Few-Shot Relation Classification. The 33th AAAI Conference on Artificial Intelligence (AAAI 2019).
[23] Zhi-Xiu Ye, Zhen-Hua Ling. Multi-Level Matching and Aggregation Network for Few-Shot Relation Classification. The 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019).
[24] Livio Baldini Soares, Nicholas FitzGerald, Jeffrey Ling, Tom Kwiatkowski. Matching the Blanks: Distributional Similarity for Relation Learning. The 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019).
[25] Tianyu Gao, Xu Han, Hao Zhu, Zhiyuan Liu, Peng Li, Maosong Sun, Jie Zhou. FewRel 2.0: Towards More Challenging Few-Shot Relation Classification. 2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP 2019).
[26] Chris Quirk, Hoifung Poon. Distant Supervision for Relation Extraction beyond the Sentence Boundary. The 15th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2017).
[27] Nanyun Peng, Hoifung Poon, Chris Quirk, Kristina Toutanova, Wen-tau Yih. Cross-Sentence N-ary Relation Extraction with Graph LSTMs. Transactions of the Association for Computational Linguistics (TACL 2017).
[28] Chih-Hsuan Wei, Yifan Peng, Robert Leaman, Allan Peter Davis, Carolyn J. Mattingly, Jiao Li, Thomas C. Wiegers, Zhiyong Lu. Overview of the BioCreative V Chemical Disease Relation (CDR) Task. The 5th BioCreative Challenge Evaluation Workshop (BioC 2015).
[29] Omer Levy, Minjoon Seo, Eunsol Choi, Luke Zettlemoyer. Zero-Shot Relation Extraction via Reading Comprehension. The 21st Conference on Computational Natural Language Learning (CoNLL 2017).
[30] Yuan Yao, Deming Ye, Peng Li, Xu Han, Yankai Lin, Zhenghao Liu, Zhiyuan Liu, Lixin Huang, Jie Zhou, Maosong Sun. DocRED: A Large-Scale Document-Level Relation Extraction Dataset. The 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019).
[31] Ruidong Wu, Yuan Yao, Xu Han, Ruobing Xie, Zhiyuan Liu, Fen Lin, Leyu Lin, Maosong Sun. Open Relation Extraction: Relational Knowledge Transfer from Supervised Data to Unsupervised Data. 2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP 2019).
[32] Tianyu Gao, Xu Han, Ruobing Xie, Zhiyuan Liu, Fen Lin, Leyu Lin, Maosong Sun. Neural Snowball for Few-Shot Relation Learning. The 34th AAAI Conference on Artificial Intelligence (AAAI 2020).
[33] Xu Han, Tianyu Gao, Yuan Yao, Deming Ye, Zhiyuan Liu, Maosong Sun. OpenNRE: An Open and Extensible Toolkit for Neural Relation Extraction. The Conference on Empirical Methods in Natural Language Processing (EMNLP 2019).
本文转载于刘知远老师知乎专栏:
原文链接:
https://zhuanlan.zhihu.com/p/91762831

https://www.zhihu.com/people/zibuyu9
附注:更多知识图谱资料请上,专知网站查看,
https://www.zhuanzhi.ai/topic/2001005380553956