CCCF专栏 | 朱晨光:机器阅读理解:如何让计算机读懂文章
最近几年,阅读理解作为应用广泛而难度较大的课题,吸引了许多研究者的关注。深度学习在这一领域取得了长足进步,但离人类水平还有很大差距,真正的智能文本理解依然是一个巨大的挑战。


机器阅读理解任务
在2013年之前,自然语言处理(Natural Language Processing, NLP)研究中的主要任务集中在对词和句子的理解,例如词向量、句法分析、歧义消除等。而对于更复杂的结构,例如段落和文章,因其分析难度大而鲜有相关研究。近年来,深度学习在自然语言处理方面的突飞猛进,使针对句群和段落的语义分析成为可能。
基于人类的认知,判断阅读者是否理解一篇文章最直接的方式就是进行问答考核,即给定文章和与之相关的问题,评判阅读者给出的答案是否正确。因此,机器阅读理解多以问答形式来判断人工智能是否理解文章。机器阅读理解在工业界有着广泛的应用,例如:搜索引擎可以根据用户输入的查询来找到相关文档并精确给出答案;客服对话机器人可以根据用户的问题找到解决问题的文档并显示出具体的解决步骤等。
基于机器阅读理解的重要应用价值,在2013年微软发布McTest数据集[1]之后,有十多个大规模机器阅读理解任务的数据集产生。
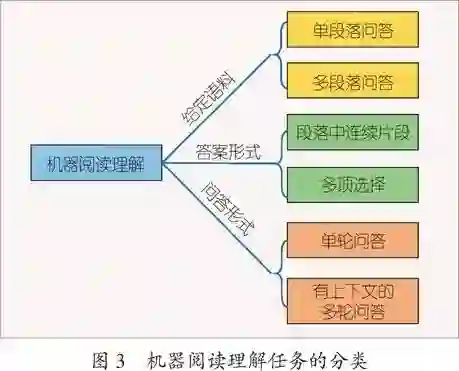
根据给定语料的范围,可以将机器阅读理解的任务分为两大类:单段落问答任务和多段落问答任务。单段落问答任务是给定一个段落,其长度通常在数十到数百词之间,对于一个和段落相关的问题,算法需要在段落中找到对应的答案。图1是“讯飞杯”中文机器阅读理解评测中的一个样例。这类的数据集有McTest[1]、SQuAD[2]、 CoQA[3]、RACE[4]等。多段落回答任务通常给定一个大的语料库,包含许多文章与段落。对于一个问题,算法需要利用检索定位到答案可能存在的段落,再进行回答,这使得对于模型准确度的要求大大增加。相关数据集有MS MARCO[5]、ARC[6]等。

根据答案的形式,机器阅读理解任务可分为段落中连续片段和多项选择两种。对于段落中连续片段任务,答案一定是段落中一段连续的文本,即模型只需要给出答案在给定段落中的起止位置,如图1。代表数据集有SQuAD[2]、CoQA[3]。对于此类阅读理解任务,评判的标准一般为正确答案与模型给出答案之间分词后的精确率、召回率和F1分数(如图2)。多项选择任务即给定若干备选项,算法需要选出一个或多个正确选项。代表数据集有McTest[1]、ARC[6]等。

当前机器阅读理解任务的答案形式大多数为以上两种,形式均为限定的。其原因在于,判断自由形式的答案与正确答案是否语义一致本身是很困难的问题。
根据问答形式分类,可以将阅读理解任务分为单轮问答和有上下文的多轮问答两类。单轮问答中,不同轮的问题和答案之间没有相关性,可以独立求解。大部分阅读理解任务属于该类型。而从2018年开始,有上下文的多轮问答任务逐渐引起大家的关注。这类任务中,邻近轮的问题和答案之间存在相关性,即回答第N+1轮的问题有可能需要依据第N轮及之前的问题和答案。这种形式的阅读理解任务更符合人与人之间对话的过程。相关数据集有CoQA[3]、QuAC[7]等。
模型求解
随着深度学习的不断发展,现在的机器阅读理解算法大多数是端到端深度学习模型:输入为原始的段落和问题文本,中间是可以求导优化的网络模型,而输出即为答案。这种形式给模型的建立和优化带来了极大的便利。
机器阅读理解模型的核心是建立给定段落和问题之间的语义联系,除了需要分别对段落和问题进行语义分析,也需要在段落中寻找与问题相关的片段。因此机器阅读理解模型至少需要三个核心模块:(1)对段落/问题进行有上下文的语义分析;(2)在段落的不同片段和问题之间计算相关度,并更新语义分析结果;(3)根据相关度生成答案。
上下文语义分析
对于输入的原始文本,模型需要先经过分词,然后将每个词转化成固定长度的词向量进行分析。自然语言处理中比较通用的词向量表示有GloVe[8]、word2Vec[9]等。例如GloVe可以将任意一个词转化成为300维2的实数向量。
由于词向量表示是固定的,而一个词在不同的语境下可能有不一样的语义,因此必须根据其上下文计算出语境相关的语义表示。通用的方法是在词向量上采用循环神经网络(RNN),通过信息的流动获得每个词在上下文中的向量表示。
自2018年以来,用于计算上下文相关词向量的预训练语言模型,因其优秀的性能而引起了研究人员的广泛关注。这类语言模型通过在大规模语料库上的训练来获得网络结构的参数。这样的网络结构产生的上下文相关词向量,在许多自然语言处理任务中取得了非常不错的结果。这类预训练语言模型包括ELMo[10]和BERT模型[11]。BERT模型基于Google提出的Transformer编码器,通过在海量语料库中的无监督学习,获得的预训练上下文相关词向量编码网络在11种不同的自然语言处理测试中获得最佳成绩,尤其是在机器阅读理解任务SQuAD v1.0中,首次在所有指标上超越了人类。因此,最新的机器阅读理解模型在上下文语义分析模块中基本都使用了ELMo或BERT,然后使用循环神经网络获得词向量。
计算段落片段与问题相关度
由于问题与段落相关,对于段落的语义分析一定要基于对问题的理解。最基础的方法是,对于段落中的每个词,用一个比特位来表示它是否在问题中出现。而在深度学习中,使用注意力机制可以得到更好的效果。
给定文本A和文本B,注意力机制可以计算出基于对B的语义分析,A中每个词语的词向量表示。算法1给出了一种基于内积的注意力机制计算方法。在注意力机制中,文本A每个词语的词向量表示是文本B词向量的一种线性组合,该组合的系数来自A和B每个词对之间的匹配程度。

除此之外,自注意力机制可以生成一个文本基于自身词对之间匹配程度的词向量表示,即A=B。其意义在于,循环神经网络在长文本中会出现影响力递减的情况:长文本中相隔较远的词之间很难互通信息。而自注意力机制通过计算单词两两之间的匹配程度,打破距离的限制,从而获得更精确的文本理解。
答案生成
对于多项选择类型的答案,可以通过神经网络中的线性变换层生成每个选项的概率,并通过交叉熵求导优化。对于段落片段类型的答案,一般是计算段落中每个位置作为答案开始和结束的概率,并选择概率最大的区间输出。算法2给出了一个典型的段落片段类型答案的生成方法,其中u,Ws,We均为参数。

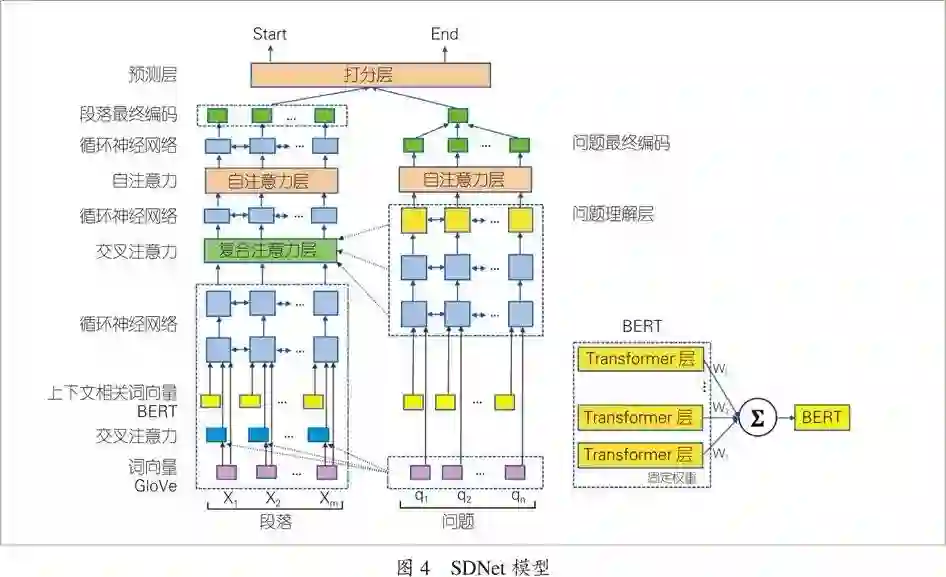
在实际模型中,以上三个核心模块均会有不同变种,例如更多的循环神经网络层数、注意力机制的反复使用等。图4展示了最近在机器阅读理解多轮问答数据集CoQA上获得第一名的SDNet模型[12]。该模型使用了BERT输出层的线性组合以及复合注意力层的模块,获得了很好效果。
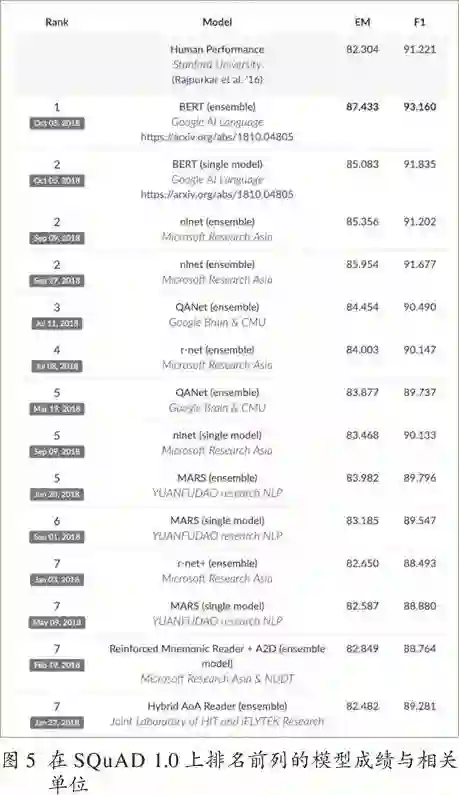
值得一提的是,在影响力很大的机器阅读理解竞赛SQuAD中,微软亚洲研究院、国防科技大学、哈尔滨工业大学与讯飞联合实验室等中国团队排在前列3(见图5)。
挑战
2018年初,在斯坦福大学推出的机器阅读理解数据集SQuAD上,来自微软和阿里巴巴的研究团队均在精确匹配程度指标上超越了人类,相关媒体也发出了“人工智能已经在阅读理解任务上战胜了人类”的口号。但是,相关研究表明,现在的机器阅读理解模型很大程度上依赖于简单的文本匹配。一旦给段落加入干扰信号,模型表现会大幅下降。在文献[13]中,关于SQuAD数据集上表现最好的16个机器阅读理解模型的实验表明,在段落中加入一个干扰句(干扰句和正确答案所在句的文本匹配度高,但关键词不一样)会使得所有模型的F1指标均下降20%~40%,而人类实验者的指标只下降3%。该结果表明,现有的机器学习模型仍远没有达到人类理解文本的精确程度。如何加强模型的深度理解能力是这一领域的重要课题之一。
无监督学习 现有的阅读理解数据集规模与大规模语料库相比依然很小,如何使阅读理解模型不完全依赖于标注数据是一个很有意义的方向。
推理能力 当前的大多数数据集不需要多层推理便可获得正确答案,即事实型问答。人类特有的推理归纳能力还没有在机器阅读理解中得到体现。实现推理能力是文本理解中的重要课题。
文本表示 自然语言处理中关于词向量和句向量已有大量研究。而对于段落和长文本,一直以来没有很好的向量表示方法。由于机器阅读理解任务与段落相关,利用其问答数据建立有效的文本表示将有助于其他任务的处理。
最近几年,阅读理解作为应用广泛而难度较大的课题,吸引了许多研究者的关注。相应的数据集和竞赛层出不穷,带动了更新更通用的深度学习模块的研究(例如预训练语言模型ELMo和BERT)。深度学习在这一领域取得了长足进步,但离人类水平还有很大差距,真正的智能文本理解依然是一个巨大的挑战。
作者介绍
|
朱晨光 
•美国微软公司研究员,斯坦福大学计算机博士。 •主要研究方向为自然语言处理,包括机器阅读理解、人机对话及词嵌入。 |

|
脚注
1 来源:http://world.people.com.cn/n/2014/0101/c1002-23995935.html。
2 模型通过训练将词映射成k维实数向量,k一般为模型中的超参数。
3 来源:https://rajpurkar.github.io/SQuAD-explorer/。
参考文献
[1] Richardson M, BurgesC J, Renshaw E. Mctest: A challenge dataset for the open-domainmachine comprehension of text[C]// Proceedings of the 2013 Conference onEmpirical Methods in Natural Language Processing. 2013: 193-203.
[2] Rajpurkar P, Zhang J,Lopyrev K, et al. Squad: 100,000+ questions for machine comprehension oftext[OL]. arXiv preprint arXiv:1606.05250.2016.
[3] Reddy S, Chen D,Manning C D. CoQA: A conversational question answering challenge[OL]. arXivpreprint arXiv:1808.07042.2018.
[4] Lai G, Xie Q, Liu H,et al. Race: Large-scale reading comprehension dataset from examinations[OL].arXiv preprint arXiv:1704.04683.2017.
[5] Nguyen T, RosenbergM, Song X, et al. MS MARCO: A human generated machine reading comprehensiondataset[OL]. arXiv preprint arXiv:1611.09268.2016.
[6] Clark P, Cowhey I,Etzioni O, et al. Think you have Solved Question Answering? Try ARC, the AI2Reasoning Challenge[OL]. arXiv preprint arXiv:1803.05457.2018.
[7] Choi E, He H, IyyerM, et al. QuAC: Question answering in context[OL]. arXiv preprintarXiv:1808.07036. 2018.
[8] Pennington J, SocherR, Manning C. Glove: Global vectors for word representation[C]// Proceedings ofthe 2014 conference on empirical methods in natural language processing (EMNLP).2017: 1532-1543.
[9] Mikolov T, SutskeverI, Chen K, et al. Distributed representations of words and phrases and theircompositionality[J]. Advances in neural information processing systems .2013:3111-3119.
[10] Peters M E, NeumannM, Iyyer M, et al. Deep contextualized word representations[J]. arXiv preprintarXiv:1802.05365. 2018.
[11] Devlin J, Chang M W,Lee K, et al. Bert: Pre-training of deep bidirectional transformers forlanguage understanding[J]. arXiv preprint arXiv:1810.04805. 2018.
[12] Zhu C, Zeng M, HuangX. SDNet: Contextualized Attention-based Deep Network for ConversationalQuestion Answering[J]. arXiv preprint arXiv:1812.03593.2018.
[13] Jia R, Liang P.Adversarial examples for evaluating reading comprehension systems[J]. arXivpreprint arXiv:1707.07328.2017.
中国计算机学会

长按识别二维码关注我们
CCF推荐
【精品文章】
点击“阅读原文”,查看详情。




