用DensePose,教照片里的人学跳舞,系群体鬼畜 | ECCV 2018
栗子 发自 凹非寺
量子位 出品 | 公众号 QbitAI

怎样让一个面朝镜头、静止不动的妹子,跳起你为她选的舞蹈,把360度身姿全面呈现?
Facebook团队,把负责感知的多人姿势识别模型DensePose,与负责生成的深度生成网络结合起来。
不管是谁的感人姿势,都能附体到妹子身上,把她单一的静态,变成丰富的动态。

这项研究成果,入选了ECCV 2018。
当然不能只有DensePose
团队把SMPL多人姿态模型,跟DensePose结合到一起。这样一来,就可以用一个成熟的表面模型来理解一张图片。
这项研究,是用基于表面的神经合成,是在闭环里渲染一张图像,生成各种新姿势。

△左为源图像,中为源图姿势,右为目标姿势
照片中人需要学习的舞姿,来自另一个人的照片,或者视频截图。
DensePose系统,负责把两张照片关联起来。具体方法是,在一个公共表面UV坐标系 (common surface coordinates) 里,给两者之间做个映射。
但如果单纯基于几何来生成,又会因为DensePose采集数据不够准确,还有图像里的自我遮挡 (比如身体被手臂挡住) ,而显得不那么真实。

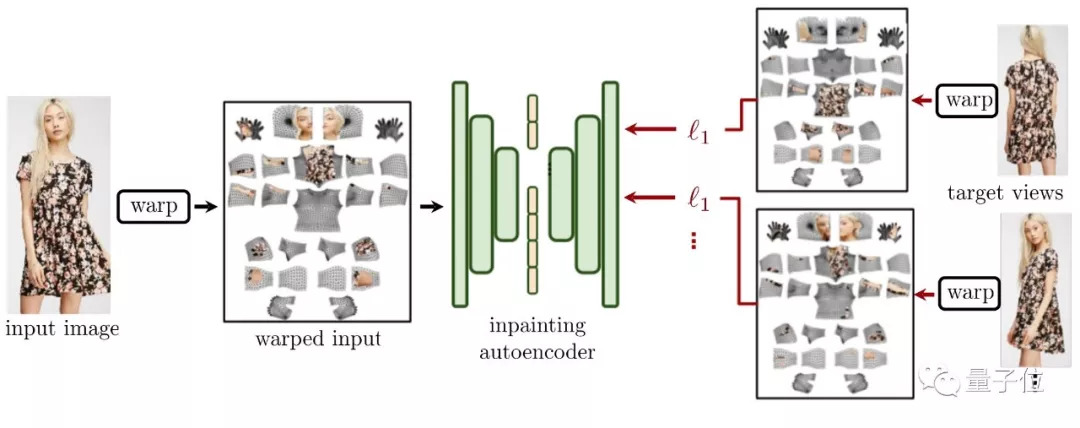
△DensePose提取的质地 (左) vs 修复后的质地 (右)
那么,团队处理遮挡的方法是,在表面坐标系里,引入一个图像修复 (Impainting) 网络。把这个网络的预测结果,和一个更传统的前馈条件和成模型预测结合起来。
这些预测是各自独立进行的,然后再用一个细化模块来优化预测结果。把重构损失、对抗损失和感知损失结合起来,优势互补,得出最终的生成效果。
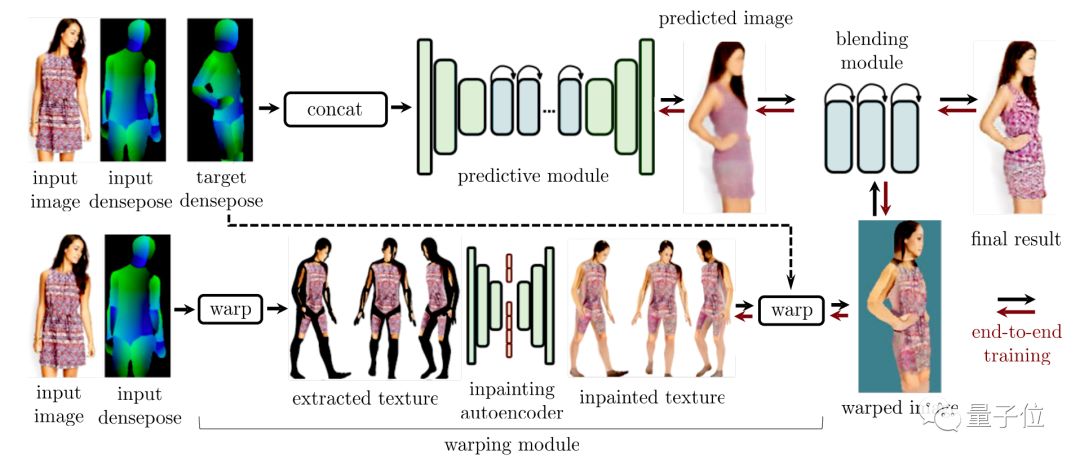
完整的网络结构,就如上图这般。
监督学习一下
模型的监督学习过程,是这样的:
从输入的源图像开始,先把它的每个像素对应到UV坐标系里。这一步是DensePose驱动的迁移网络完成的。
然后,负责修复图像的自编码器,就来预测照片中人的不同角度会是什么样子。这步预测,也是在扭曲的坐标系里完成的。
从右边开始,就是生成目标,同样要整合到UV坐标系中。再用损失函数 来处理 (上图红字部分) 把结果输入自编码器,帮助模型学习。
用同一人物 (同样装扮) 的多个静态姿势来作监督,替代了360度旋转的人体。
训练成果如何
先来看一下,新加入的图像修复步骤,生成的效果:

把DensePose的质地纹路,修复一下,还是有明显效果的。
再来看一下多人视频什么样子:

虽然,脸部好像烧焦的样子,但已经很鬼畜了。在下不由得想起:

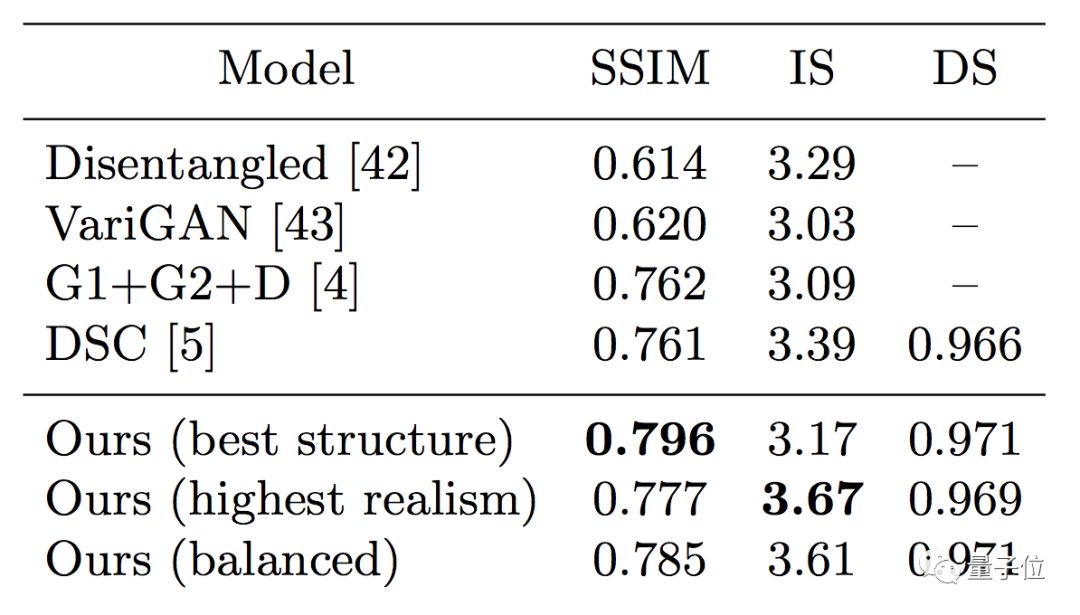
另外团队用DeepFashion数据集,对比了一下自家算法和其他同行。
结果是,结构相似度 (Structural Similarity) ,以假乱真度 (Inception Score) 以及检测分 (Detection Score) 这三项指标,Facebook家的算法表现都超过了前辈。
各位请持续期待,DensePose更多鬼畜的应用吧。
论文传送门:
https://arxiv.org/pdf/1809.01995.pdf
顺便一提,教人学跳舞的算法真的不少。
比如,伯克利舞痴变舞王,优点是逼真,缺点是无法实现多人共舞:

vs

— 完 —
活动推荐

华为云•普惠AI,让开发充满AI!
爱上你的代码,爱做 “改变世界”的行动派!
大会将首次发布AI开发框架,从AI模型训练到AI模型部署的全套开发一站式完成!让AI开发触手可及!

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态



