GPU高效通信算法-Ring Allreduce
点击蓝字关注这个神奇的公众号~
今天看了一个篇Research,觉得非常有意思,分享给大家,顺便普及下GPU并行化的一些思想。虽然最近文章点击量不是特别理想,但是我还是会继续坚持这样的风格,会继续输出有营养的文章,同时也是督促自己学习的动力~
今天介绍一种新的GPU多卡计算的通信优化算法—Ring Allreduce。先来讲一下常规的GPU多卡分布式计算的原理。
第一点:我们知道GPU在矩阵并行化计算方面非常有优势,所以适合深度学习的训练。
第二点:使用多个GPU卡训练同一个深度学习任务就是分布式计算。
第三点:在分布式计算过程中,需要对计算任务资源进行分片,通常的方式是将完整的网络结构放到每一个GPU上,然后将训练数据进行分片分发到不同的GPU卡上。
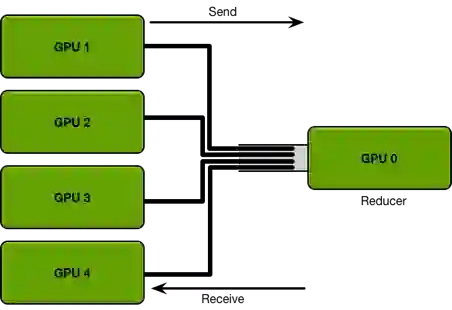
于是GPU分布式计算的具体形式就比较清晰了,以上图为例。GPU1~4卡负责网络参数的训练,每个卡上都布置了相同的深度学习网络,每个卡都分配到不同的数据的minibatch。每张卡训练结束后将网络参数同步到GPU0,也就是Reducer这张卡上,然后再求参数变换的平均下发到每张计算卡,整个流程有点像mapreduce的原理。
这里面就涉及到了两个个问题:
问题一,每一轮的训练迭代都需要所有卡都将数据同步完做一次Reduce才算结束。如果卡数比较少的情况下,其实影响不大,但是如果并行的卡很多的时候,就涉及到计算快的卡需要去等待计算慢的卡的情况,造成计算资源的浪费。
问题二,每次迭代所有的计算GPU卡多需要针对全部的模型参数跟Reduce卡进行通信,如果参数的数据量大的时候,那么这种通信开销也是非常庞大,而且这种开销会随着卡数的增加而线性增长。
为了解决这样的问题,就引入了一种通信算法Ring Allreduce,通过将GPU卡的通信模式拼接成一个环形,从而减少随着卡数增加而带来的资源消耗,如下图所示:
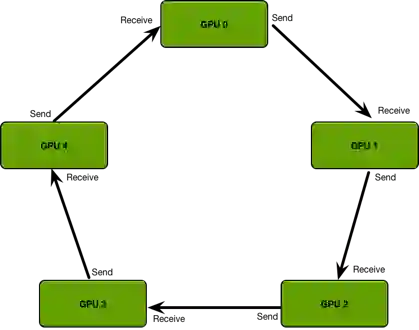
将GPU卡以环形通信之后,每张卡都有一个左手卡和右手卡,那么具体的模型参数是如何传递的呢,可以看下图:
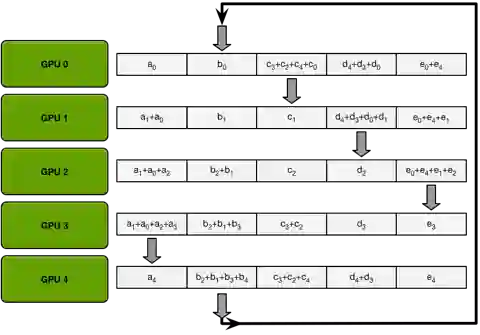
因为每张卡上面的网络结构是固定的,所以里面的参数结构相同。每次通信的过程中,只将参数send到右手边的卡,然后从左手边的卡receive数据。经过不断地迭代,就会实现整个参数的同步,也就是reduce。形成以下这张图的样式:
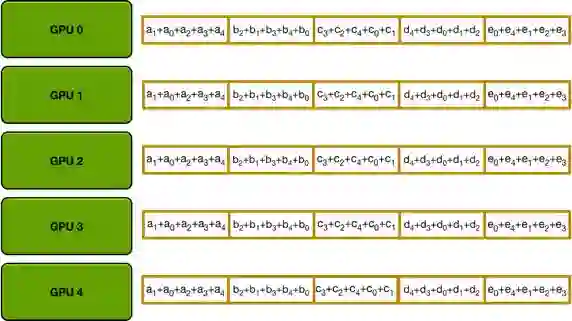
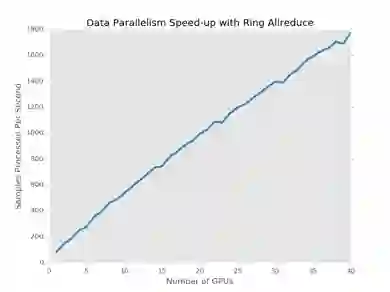
通过Ring Allreduce的方式,基本上可以实现当GPU并行卡数的增加,实现计算性能的线性增长。
参考:Bringing HPC Techniques to Deep Learning
http://research.baidu.com/bringing-hpc-techniques-deep-learning/
End

分享公众号名片到40人以上的大群并截图给小助手,小助手就会拉你入群
在这里你可以得到:
1.各种学术讨论
2.最新的资料分享
3.不定期的征文以及联谊活动!
小助手微信号:meiwznn

给我一分钟
送你一个学习的世界

微信号:凡人机器学习
长按二维码关注




