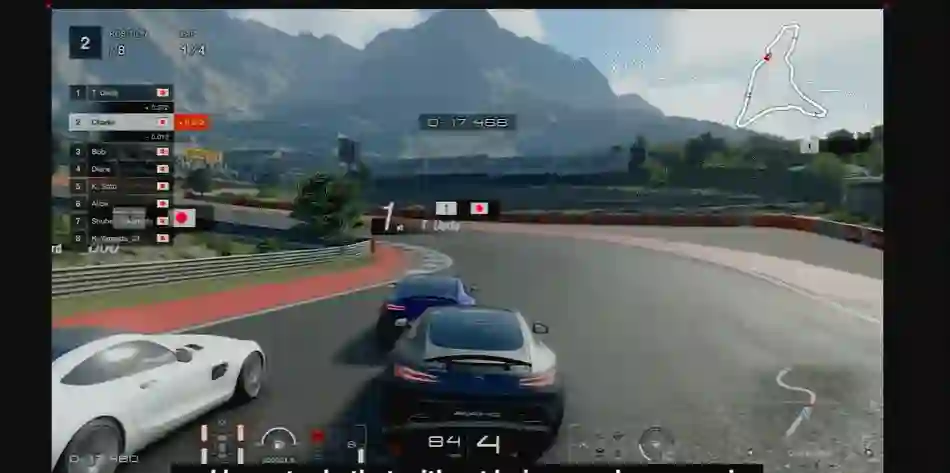
在《GT 赛车》中战胜数位全球顶级电子竞技赛车手,索尼 AI 开发了一个超强大的赛车 AI 智能体。
![]()
从国际象棋到围棋再到扑克,AI 智能体在许多游戏中都胜过人类。现在,这些智能体可以在《GT 赛车》(Gran Turismo)刷新最高分。
《GT 赛车》由 SCEJ 旗下的著名制作人山内一典领衔研发的一款赛车游戏。始创于 1997 年,此游戏是由 POLYPHONY DIGITAL 开发的赛车游戏。无论从游戏画面、操作驾驶时的赛道、赛车数量、真实感,系统都做到尽量完善。这款游戏收录了超过 50 条赛道,超过 1000 款车型,可谓汽车博物馆。
今日索尼宣布,其研究人员已经开发出一款名为「 GT Sophy」的 AI 驱动程序,其能够在 GT 赛车运动中连续几圈击败人类顶级电子竞技赛车手。相关论文登上 Nature 封面。
![]()
论文地址:https://www.nature.com/articles/s41586-021-04357-7
![]()
![]()
或许有人认为这是一个简单的挑战,毕竟,赛车不只是速度和反应时间的问题。但电子游戏赛车和 AI 领域的专家都表示,GT Sophy 是一项重大突破,这表现出智能体对战术和战略的掌握。
来自斯坦福大学研究自动驾驶的教授 Chris Gerdes 表示,「在赛车比赛中,如此熟练地超越顶级车手,是 AI 的标志性成就。」
GT Sophy 使用一种称为强化学习的方法进行训练:本质上是一种试错形式,其中 AI 智能体被扔到一个没有指令的环境中,并因达到某些目标而获得奖励。在 GT Sophy 的案例中,索尼的研究人员表示,他们必须非常谨慎地设计这种奖励:例如,微调碰撞惩罚,以塑造一种足够强悍的驾驶风格,从而赢得胜利,但这并不会导致 AI 粗暴地将其他赛车赶出道路。
使用强化学习,GT Sophy 只需几个小时的训练就能在赛道上行驶,并且在一两天的时间内就能超越训练数据集中 95% 的车手比赛。经过大约 45,000 小时的全部训练,GT Sophy 能够在三个赛道上取得超人的表现。
在测试 AI 智能体时,智能体具有许多天生的优势,例如它们可以完美的进行回放、反应时间也非常快。索尼的研究人员指出,与人类玩家相比,GT Sophy 确实具有一些优势,例如带有赛道边界坐标的精确路线地图和关于每个轮胎的负载、每个轮胎的侧偏角和其他车辆状态的精确信息。但是,索尼表示智能体占据了动作频率和反应时间这两个特别重要的因素。
GT Sophy 的输入被限制在 10Hz,而人类的理论最大输入是 60Hz。索尼表示这导致人类驾驶员在高速行驶时表现出更加流畅的动作。在反应时间方面,GT Sophy 能够在 23-30 毫秒内对比赛环境中的事件做出反应,这比职业运动员的 200-250 毫秒的最高反应时间要快得多。作为补偿,研究人员添加了人工延迟,以 100 毫秒、200 毫秒和 250 毫秒的反应时间训练 GT Sophy。但正如他们发现的那样:所有这三项测试都达到了超越人类水平的单圈时间。
GT Sophy 与三位顶级电子竞技车手进行了测试:Emily Jones、Valerio Gallo 和 Igor Fraga。尽管没有一位车手能够在计时赛中击败 AI,但比赛让他们发现了新的战术。
索尼表示目前他们正在努力将 GT Sophy 整合到未来的 Gran Turismo 游戏中,但还没有明确的时间点。
这个具有突破性的超越人类的赛车智能体是 Sony AI 联合 Polyphony Digital (PDI) 和 Sony Interactive Entertainment (SIE) 共同开发的。研究人员主要在以下几个方面做出了贡献:
超现实模拟器
新型强化学习技术
分布式训练平台
大规模训练基础设施
![]()
如上所述,《GT 赛车》(GT Sport)是由 Polyphony Digital 开发的 PlayStation 4 驾驶模拟器。《GT 赛车》尽可能逼真地再现了真实世界中的赛车环境,包括赛车、赛道甚至空气阻力和轮胎摩擦等物理现象。Polyphony Digital 提供了对必要 API 的访问,从而在这个终极模拟环境中训练 GT Sophy。
![]()
强化学习(RL)是一种机器学习,用于训练 AI 智能体在环境中采取行动,并通过行动导致的结果进行奖励或惩罚。下图展示了智能体如何与环境交互。智能体采取行动,获得奖励或惩罚,并根据环境状态的变化来确定自身的下一步行动。
![]()
索尼 AI 的研究人员和工程师开发了一系列创新性强化学习技术,包括如下:
最近,深度强化学习(Deep RL)已成为街机游戏、国际象棋、将棋和围棋等复杂策略游戏以及其他实时多人策略游戏中所取得的 AI 里程碑的关键组成部分。RL 特别适合开发游戏 AI 智能体,因为 RL 智能体会考虑其行为的长期影响,并且可以在学习期间独立地收集自身数据,从而不再需要复杂的手动编码行为规则。
然而,处理像《GT 赛车》这类复杂的游戏需要开发同样复杂和微妙的算法、奖励和训练场景。
通过在 RL 技术方面的关键创新,索尼 AI 开发的 GT Sophy 掌握了赛车控制(Race Car Control)、赛车策略(Racing Tactics)和竞赛礼仪(Racing Etiquette)的技能。
新型算法 QR-SAC 能够准确地推理出 GT Sophy 高速驾驶行为所产生的各种可能性结果。并且,通过考虑驾驶行为的后果和其中的不确定性,GT Sophy 可以实现极限转弯。
![]()
GT Sophy 智能体能够没有任何接触地通过紧靠墙壁的赛道。
虽然 RL 智能体可以收集自己的数据,但训练滑流(slipstream passing)等特定技能需要赛车对手处于特定位置。为了解决这个问题,GT Sophy 进行了混合场景训练,使用到了可能在每条赛道上至关重要的手动制作比赛情况,以及帮助智能体学习这些技能的专业陪练对手。这些技能训练场景帮助 GT Sophy 获得了专业的赛车技术,包括处理拥挤的起步、防守动作等。
![]()
GT Sophy 智能体利用急转弯成功地超越了人类驾驶员。
为了帮助 GT Sophy 学习体育礼仪,索尼 AI 研究人员找到了将书面和不成文赛车规则编码成复杂奖励函数的方法。他们还发现,有必要赛车对手的数量,以确保 GT Sophy 进行有竞争力的练习赛,同时在与人类车手比赛时不会变得过于激进或胆怯。
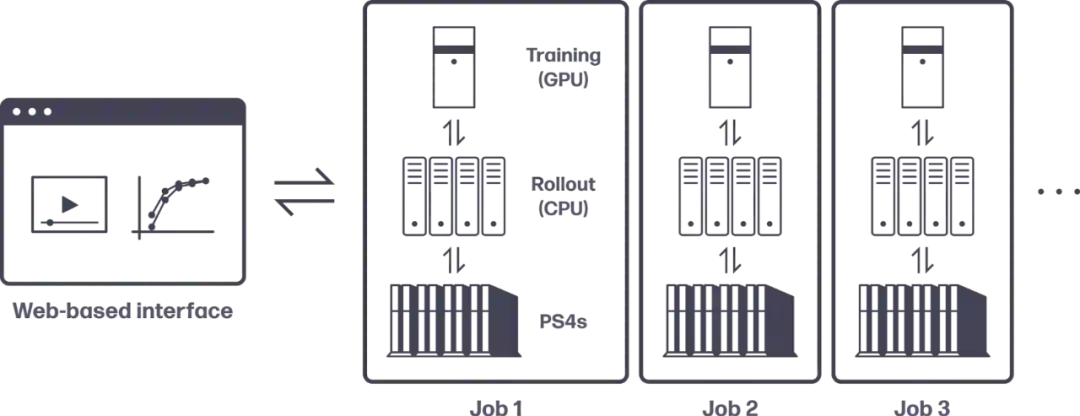
分布式、异步部署和训练 (DART) 是一个基于 Web 的定制平台,由 Sony AI 开发,使 Sony AI 的研究人员能够在 SIE 的云游戏平台中的 PlayStation 4 控制台上训练 GT Sophy。
DART 允许研究人员轻松指定实验,在云资源可用时自动运行,并收集可在浏览器中查看的数据。此外,它还管理 PlayStation 4 控制台、计算资源和用于跨数据中心训练的 GPU。该系统使索尼 AI 的研究团队能够无缝地同时运行数百个实验,同时探索将 GT Sophy 提升到新水平。
![]()
DART 平台可以访问 1,000 多个 PlayStation 4 (PS4) 控制台。每个都用于收集数据以训练 GT Sophy 或评估经过训练的版本。该平台由必要的计算组件(GPU、CPU)组成,可与大量 PS4 交互并支持长时间的大规模训练。
![]()
GT Sophy 虽然取得了重大的里程碑,但仍有进步空间。索尼 AI 将与 PDI 和 SIE 合作,继续升级 GT Sophy 的能力,并探索将智能体集成到 Gran Turismo 系列中的方式。并且,除了《GT 赛车》,索尼 AI 也渴望探索新的合作伙伴关系,通过 AI 提升玩家的游戏体验。
https://www.gran-turismo.com/us/gran-turismo-sophy/technology/
https://www.theverge.com/2022/2/9/22925420/sony-ai-gran-turismo-driving-gt-sophy-nature-paper
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com