机器之心 & ArXiv Weekly Radiostation
本周重要论文包括首尔大学与汉阳大学的研究团队开发出的仿变色龙软体机器人;SIGGRAPH 2021 最佳博士论文奖等。
Biomimetic chameleon soft robot with artificial crypsis and disruptive coloration skin
SofGAN: A Portrait Image Generator with Dynamic Styling
Robust and Accurate Simulation of Elastodynamics and Contact
SoundStream: An End-to-End Neural Audio Codec
ConvNets vs. Transformers: Whose Visual Representations are More Transferable?
Are Pre-trained Convolutions Better than Pre-trained Transformers?
CMT: Convolutional Neural Networks Meet Vision Transformers
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Biomimetic chameleon soft robot with artificial crypsis and disruptive coloration skin
摘要:
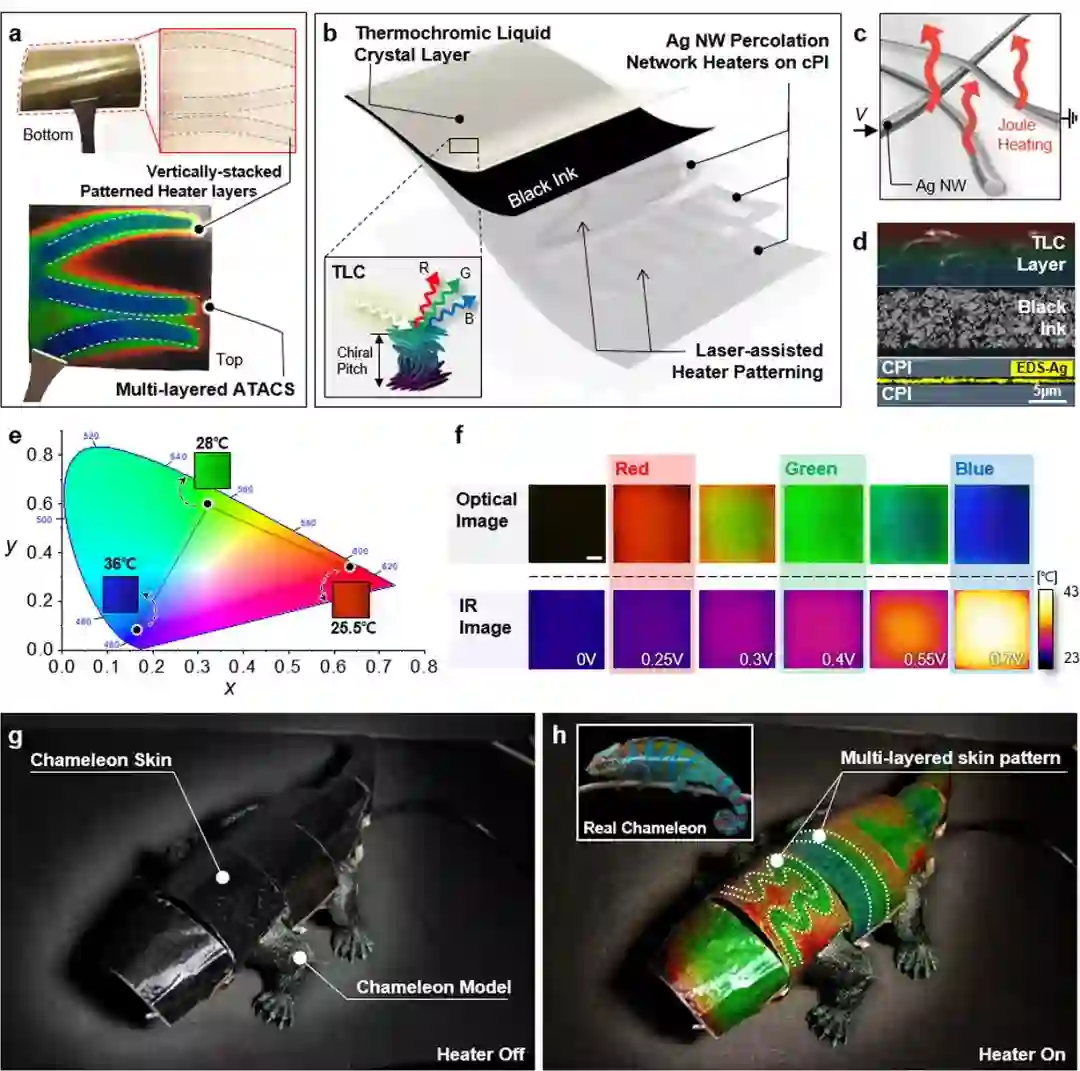
近日,科研界终于迎来了「机器版」变色龙。首尔大学与汉阳大学的研究团队开发出了一个仿变色龙软体机器人,它具备实时、自动融入背景环境的伪装能力。从各项参数上来看,这款软体机器人长约 38 厘米,宽约 15 厘米,重量仅为 0.9 公斤,其实现实时匹配背景颜色的关键在于背部覆盖的「人造变色龙皮肤 」。
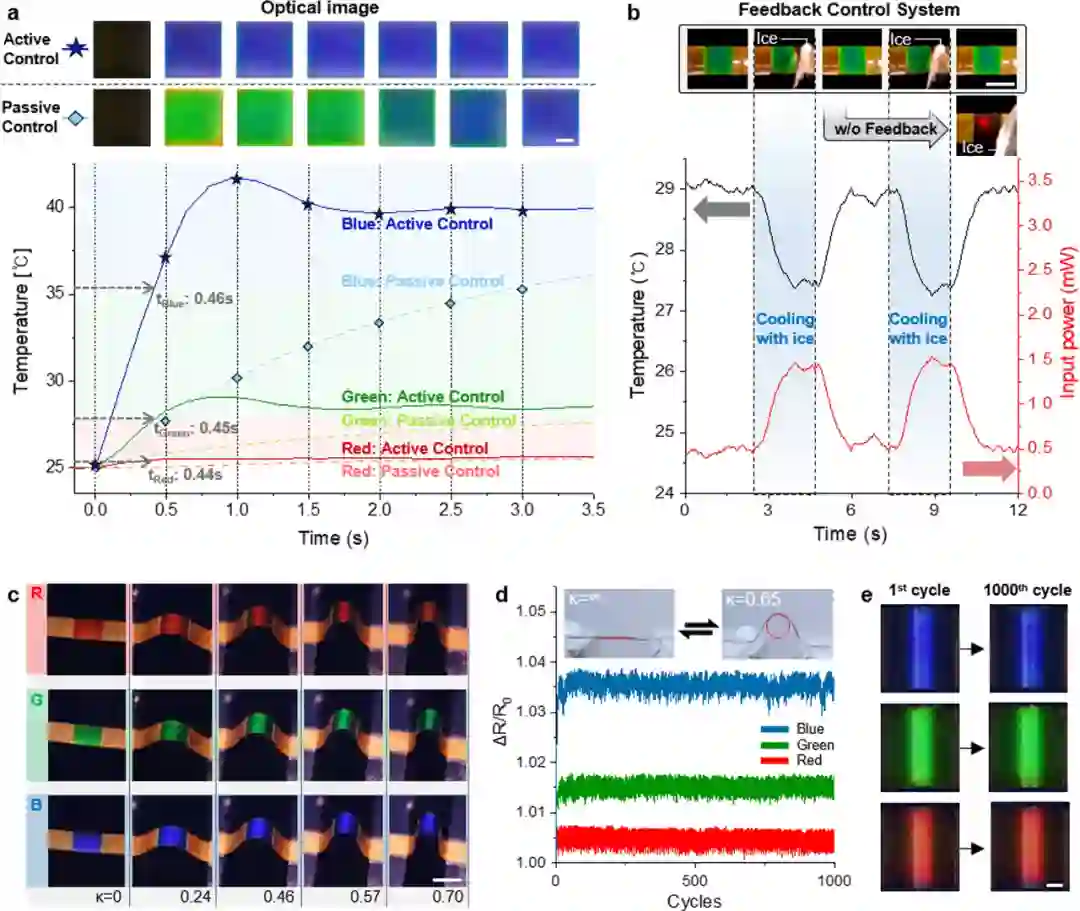
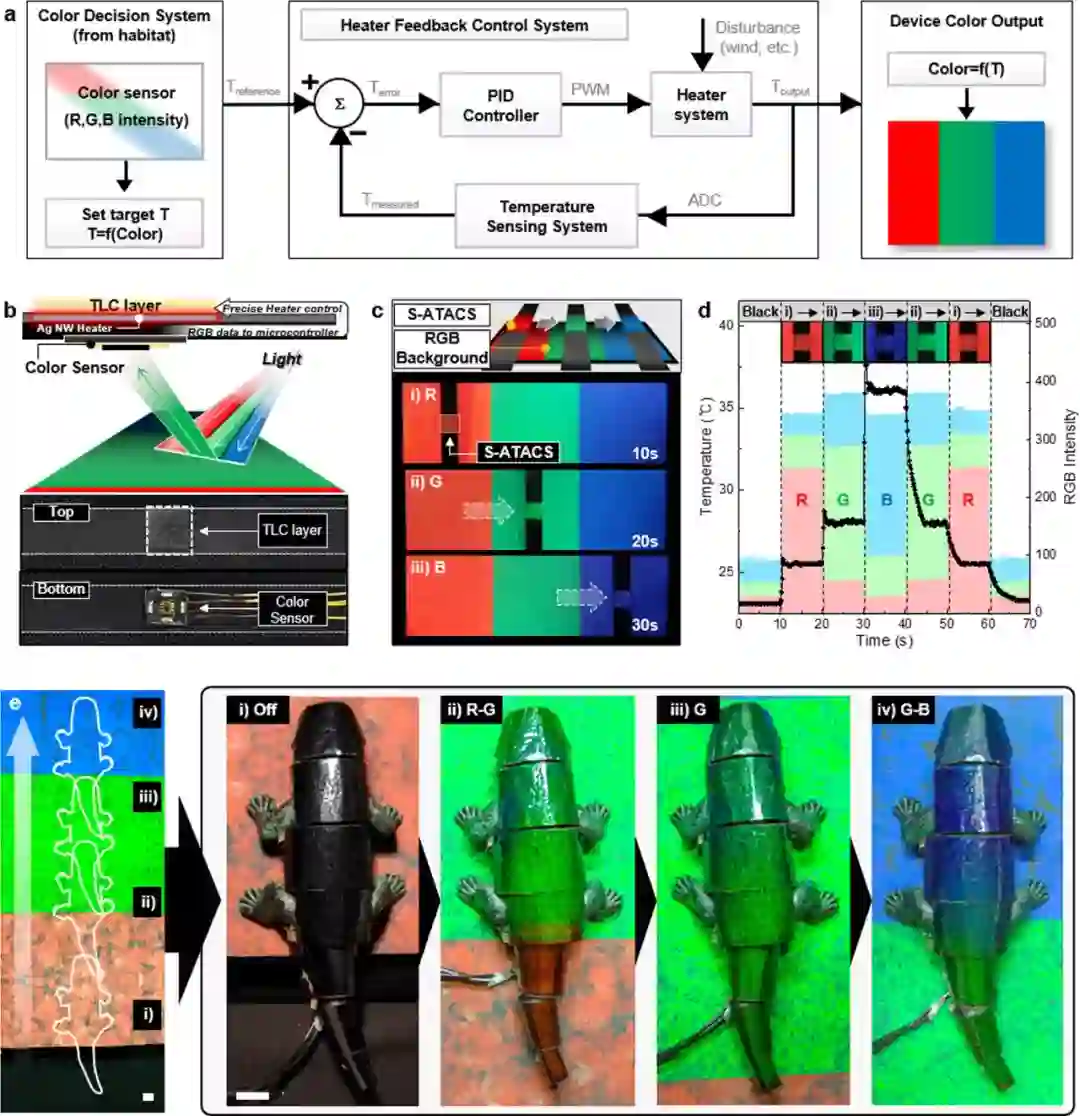
研究者采取了一种开发人造变色龙的全新策略,他们选择将热致变色液晶(thermochromic liquid crystal, TLC)层与纵向堆叠、有图案的多层银纳米线网络加热器集成在一起,制成了人造变色龙皮肤(英文缩写为 ATACS),从而通过加热器诱发的温度分布(temperature profiles)叠加克服传统横向像素化的局限。下图分别为热致变色液晶层、纵向堆叠有图案多层银纳米线加热器和多层人造变色龙皮肤的结构示意图,以及关闭和启动加热器时变色龙软体机器人的状态。
![]()
![]()
![]()
推荐:
仿变色龙软体机器人登上 Nature 子刊。
论文 2:SofGAN: A Portrait Image Generator with Dynamic Styling
摘要:
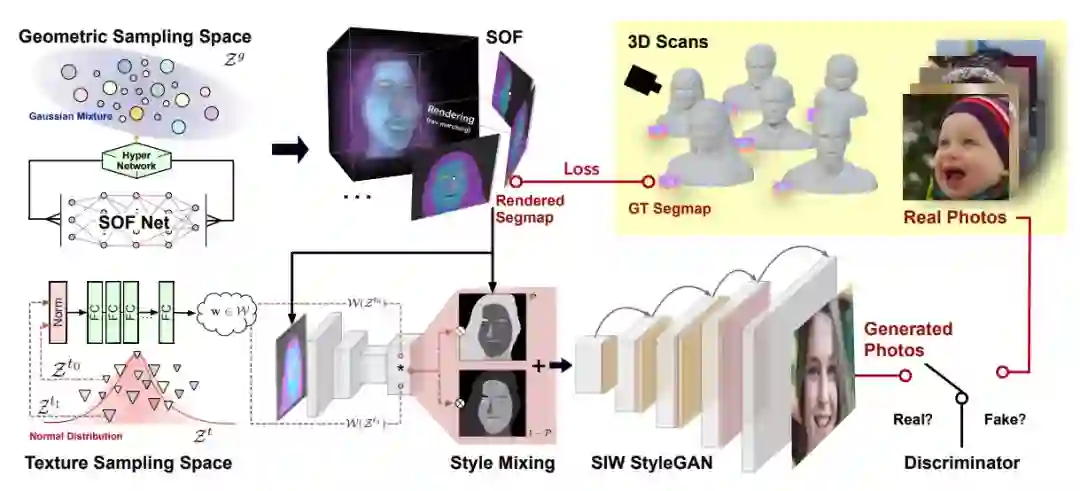
尽管生成对抗网络(GAN)已被广泛用于人像图像生成,但在 GAN 学习的潜在空间中,不同的属性,如姿态、形状和纹理风格,通常是纠缠在一起的,这使得对特定属性的显式控制变得困难。为了解决这个问题,该研究提出了一个名为 SofGAN 的图像生成器,将人像的潜在空间解耦为两个子空间:几何空间和纹理空间。从两个子空间采样的潜在代码分别馈送到两个网络分支,一个生成具有规范姿态的人像的 3D 几何图形,另一个生成纹理。对齐的 3D 几何图形还带有语义部分分割,编码为语义占用字段(semantic occupancy field,SOF)。SOF 能够在任意视图渲染一致的 2D 语义分割图,然后将其与生成的纹理图融合并使用语义 instance-wise(SIW)模块将其风格化为人像图像。该研究通过大量实验表明该系统可以生成具有独立可控几何和纹理属性的高质量人像图像。此外,该方法还可以很好地推广到各种应用中,例如外观一致的面部动画生成等。
在 StyleGAN 中,基于不同级别的输入潜在向量,图像的风格在每个卷积层上通过特征来控制。这种控制机制虽然有效,但并没有提供对单个属性的独立控制,很大程度上是由于各种属性的纠缠。为了解决这个问题,该研究将生成空间分解为两个子空间:几何空间和纹理空间,如下图左所示。
![]()
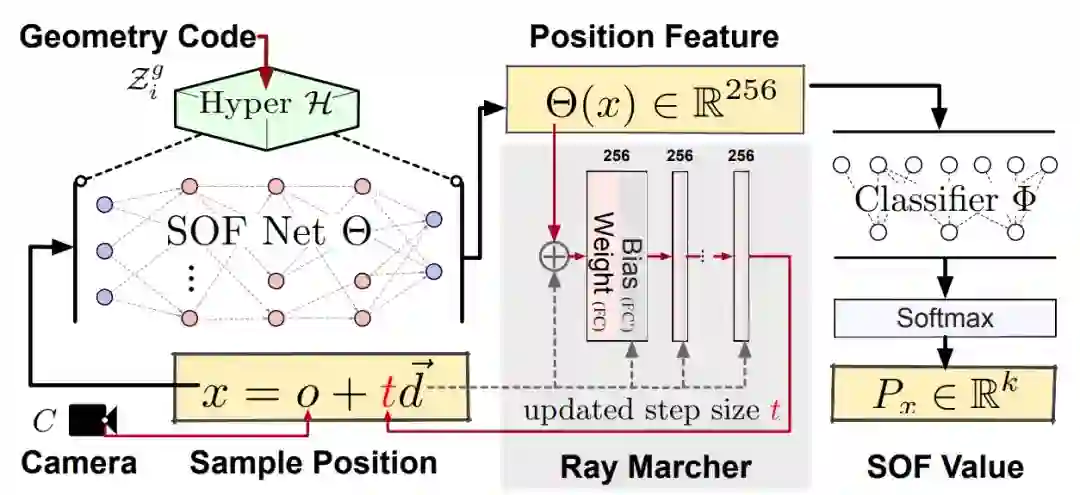
相比于先前已有的方法,该研究提出了一个更稳定的光线移动器,用于根据当前位置特征和光线方向预测步长,如下图所示。
![]()
推荐:
ACM Transactions on Graphics 2021 的研究。
论文 3:Robust and Accurate Simulation of Elastodynamics and Contact
摘要:
接触,包括摩擦接触,是许多科学领域的经典课题,如计算机图形学、机械工程、计算力学、制造设计和机器人技术等。随着时间的推移,目前研究者已经提出了相应的算法公式和时间离散化方法,这些方法在物理正确性和形状限制(例如平滑度或凸度)之间,以及在算法鲁棒性和计算效率之间提供了不同的权衡。但是在李旻辰博士的研究之前的数值方法要么计算效率高,要么是物理上正确,但不是两者兼而有之。
李旻辰研究描述了以 IPC(Incremental Potential Contact) 方法为中心的许多贡献,一种考虑摩擦接触的隐式 time-stepped 非线性弹性动力学变分解的新模型和算法。他的方法结合了碰撞间隙函数的几何精确公式,一种光滑的摩擦公式,可以将其转换为变分形式,并使用基于障碍的内点法进行优化。李旻辰的研究设计了一种可靠、统一的方法,适用于非常具有挑战性的条件,从而将可变形体模拟的稳定性、鲁棒性和表现力提升到前所未有的水平。这项研究提供了无条件的可行性和可微性,从而保持 intersection-free 和 inversion-free 轨迹,从而不受材料参数、时间步长、冲击速度、变形严重程度和边界条件的影响。
推荐:
SIGGRAPH 2021 最佳博士论文奖。
论文 4:SoundStream: An End-to-End Neural Audio Codec
作者:Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, Marco Tagliasacchi
论文链接:https://arxiv.org/pdf/2107.03312.pdf
摘要:
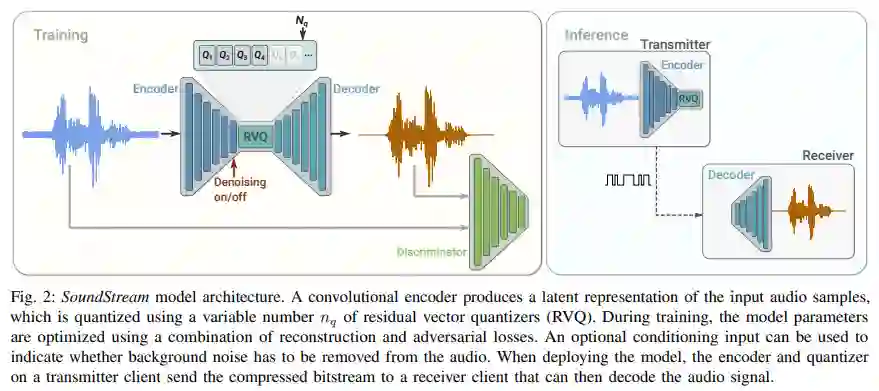
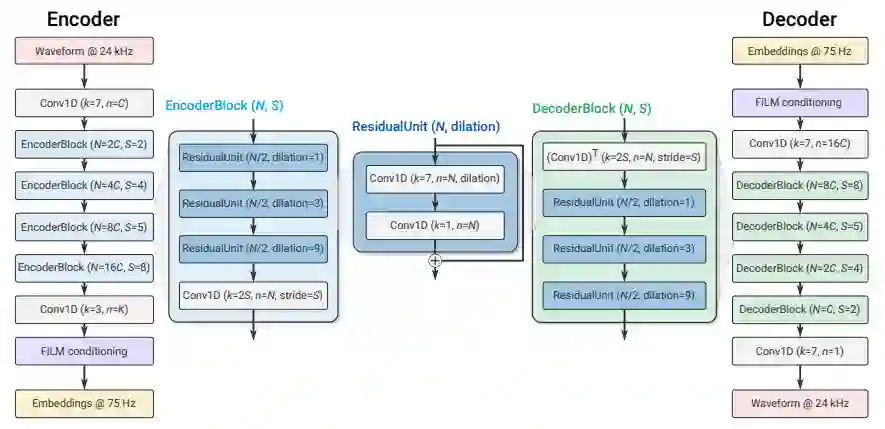
该研究介绍了 SoundStream,一种新型的神经音频编解码器,它可以有效地压缩语音、音乐和一般音频的比特率,而这种比特率通常是由语音定制编解码器设定的。SoundStream 依赖于一个模型架构,该架构由一个全卷积的编码器 / 解码器网络和一个残差矢量量化器组成,它们端到端联合训练。训练过程利用了文本转语音和语音增强方面的最新研究,结合对抗性和重建损失,允许从量化嵌入生成高质量的音频内容。通过将结构化 dropout 应用于量化器层进行训练,单个模型可以在 3 kbps 到 18 kbps 的可变比特率下运行,与以固定比特率训练的模型相比,质量损失可以忽略不计。此外,该模型适用于低延迟实现,支持流推理并可以在智能手机 CPU 上实时运行。在使用 24 kHz 采样率的音频进行评估时,3 kbps 的 SoundStream 优于 12 kbps 的 Opus,并且接近 9.6 kbps 的 EVS。此外,该研究能够在没有额外延迟的情况下在编码器或解码器端执行联合压缩和增强,并通过对语音的背景噪声抑制来证明这一点。
![]()
![]()
论文 5:ConvNets vs. Transformers: Whose Visual Representations are More Transferable?
摘要:
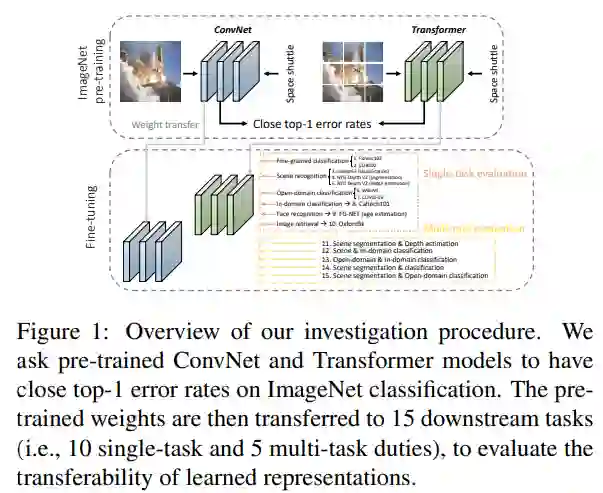
视觉 transformer 引起了计算机视觉研究人员的广泛关注,因为它们不受 ConvNet 的空间归纳偏差的限制。然而,尽管基于 Transformer 的主干在 ImageNet 分类方面取得了很大进展,但仍不清楚学习到的表示是否与 ConvNet 的特征一样具有可迁移性,甚至更具有可迁移性。为了解决这一点,该研究在 15 个单任务和多任务性能评估中系统地研究了 ConvNet 和视觉 transformer 的迁移学习能力。鉴于预训练模型的性能与迁移学习之间的强相关性,该研究包括 2 个残差 ConvNet(即 R-101×3 和 R-152×4)和 3 个基于 Transformer 的视觉主干(即 ViT-B、ViT-L 和 Swin-B) ,它们在 ImageNet 上有相近的错误率,这表明在下游数据集上有相似的迁移学习性能。
![]()
推荐:
ConvNet、Transformer 相比较。
论文 6:Are Pre-trained Convolutions Better than Pre-trained Transformers?
摘要:
在这个预训练已成为惯用方法的现代,Transformer 架构与预训练语言模型之间似乎已经有了密不可分的联系。BERT、RoBERTa 和 T5 等模型的底层架构都是 Transformer。事实上,近来的预训练语言模型很少有不是基于 Transformer 的。
本文将展示一种预训练的序列到序列模型,即 Seq2Seq。卷积模型的训练使用了基于跨度的序列到序列去噪目标,其类似于 T5 模型使用的目标。研究者在原始范式(无预训练)和预训练 - 微调范式下对多种卷积变体模型进行了评估,比如扩张模型、轻量模型和动态模型。这些评估的目标是理解在预训练时代卷积架构的真正竞争力究竟如何。
实验结果表明,在毒性检测、情感分类、新闻分类、查询理解和语义解析 / 合成概括等一系列 NLP 任务上,预训练卷积能与预训练 Transformer 相媲美。此外,研究者发现在某些情况下,预训练的卷积模型在模型质量和训练速度方面可以胜过当前最佳的预训练 Transformer。而且为了平衡考虑,研究者也描述了预训练卷积并不更优或可能不适用的情况。
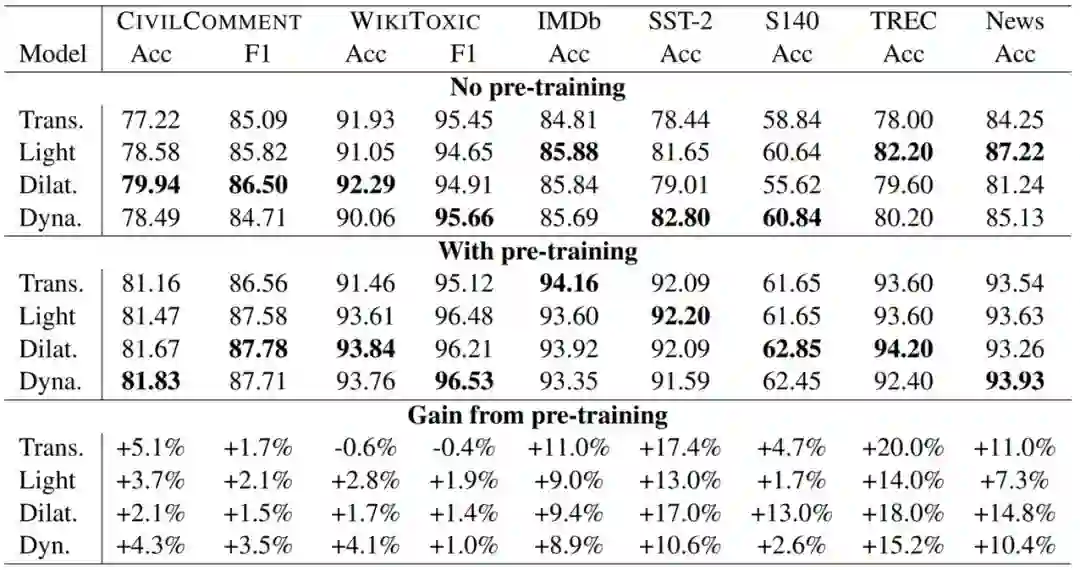
下表 2 是在毒性检测、情感分类、问题分类和新闻分类上,预训练卷积和预训练 Transformer 的表现比较。
![]()
实验发现,在多个领域的 7 项任务上,(1)相比于没使用预训练的 Transformer,没使用预训练的卷积是具有竞争力的,而且常常更优;(2)预训练卷积在 7 项任务中的 6 项上都优于预训练 Transformer。这是问题 RQ2 的答案。
推荐:
谷歌大规模研究发现预训练卷积模型往往更优。
论文 7:CMT: Convolutional Neural Networks Meet Vision Transformers
摘要:
视觉 transformer 已成功应用于图像识别任务,因为它们能够捕获图像中的远程依赖关系。然而,transformer 和现有的卷积神经网络 (CNN) 在性能和计算成本方面仍然存在差距。在本文中,该研究的目标是解决这个问题,并开发一个不仅可以胜过规范 transformer,还可以胜过高性能卷积模型的网络。该研究提出了一种新的基于 transformer 的混合网络,利用 transformer 来捕获远程依赖关系,并利用 CNN 来对局部特征进行建模。
此外,该研究对其进行扩展以获得一系列称为 CMT 的模型,与之前的基于卷积和 transformer 的模型相比,获得了更好的准确性和效率。特别是,该研究的 CMT-S 在 ImageNet 上实现了 83.5% 的 top-1 准确率,同时在 FLOP 上分别比现有的 DeiT 和 EfficientNet 小 14 倍和 2 倍。该研究提出的 CMT-S 还可以很好地泛化到 CIFAR10 (99.2%)、CIFAR100 (91.7%)、Flowers (98.7%) 和其他具有挑战性的视觉数据集,例如 COCO (44.3% mAP),并且计算成本要低得多。
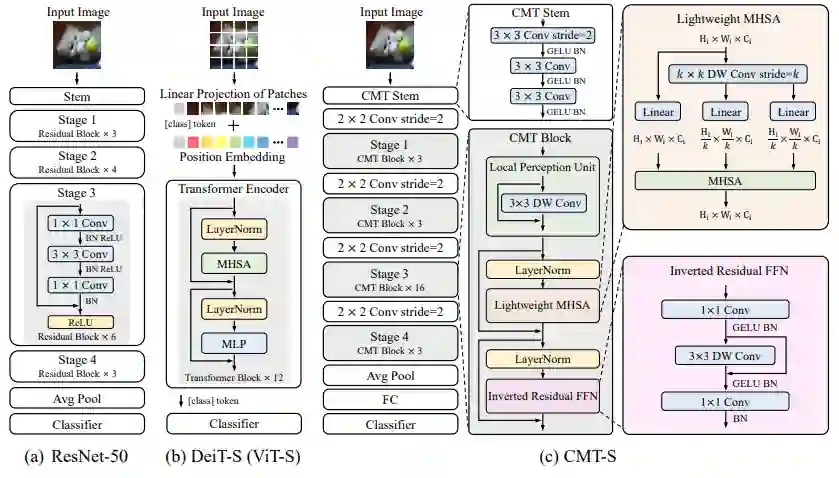
![]()
(a) 表示的是标准的 R50 模型;(b) 表示的是标准的 VIT 模型;(c) 表示的是本文所提出的模型框架 CMT,由 CMT-stem、 downsampling、cmt block 所组成,整体结构则是类似于 R50,所以可以很好的迁移到 dense 任务上去。
推荐:
Transformer+CNN 混合架构。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. Facebook AI WMT21 News Translation Task Submission. (from Philipp Koehn)
2. DEMix Layers: Disentangling Domains for Modular Language Modeling. (from Noah A. Smith)
3. SWSR: A Chinese Dataset and Lexicon for Online Sexism Detection. (from Yang Liu)
4. Controllable Summarization with Constrained Markov Decision Process. (from Irwin King)
5. Offensive Language and Hate Speech Detection with Deep Learning and Transfer Learning. (from Ajay Gupta)
6. LadRa-Net: Locally-Aware Dynamic Re-read Attention Net for Sentence Semantic Matching. (from Meng Wang)
7. What do Bias Measures Measure?. (from Kai-Wei Chang)
8. A Study of Social and Behavioral Determinants of Health in Lung Cancer Patients Using Transformers-based Natural Language Processing Models. (from Yonghui Wu)
9. CLSEBERT: Contrastive Learning for Syntax Enhanced Code Pre-Trained Model. (from Hao Wu)
10. Generation Challenges: Results of the Accuracy Evaluation Shared Task. (from Ehud Reiter)
本周 10 篇 CV 精选论文是:
1. PASS: Protected Attribute Suppression System for Mitigating Bias in Face Recognition. (from Rama Chellappa)
2. Enhancing MR Image Segmentation with Realistic Adversarial Data Augmentation. (from Liang Chen)
3. Neighborhood Consensus Contrastive Learning for Backward-Compatible Representation. (from Liang Chen)
4. NI-UDA: Graph Adversarial Domain Adaptation from Non-shared-and-Imbalanced Big Data to Small Imbalanced Applications. (from Huan Liu)
5. MicroNet: Improving Image Recognition with Extremely Low FLOPs. (from Zicheng Liu, Lei Zhang, Nuno Vasconcelos)
6. One-Shot Object Affordance Detection in the Wild. (from Dacheng Tao)
7. Learning Visual Affordance Grounding from Demonstration Videos. (from Dacheng Tao)
8. DnD: Dense Depth Estimation in Crowded Dynamic Indoor Scenes. (from Dinesh Manocha)
9. Learning Canonical 3D Object Representation for Fine-Grained Recognition. (from Ig-Jae Kim)
10. Multi-Modal MRI Reconstruction with Spatial Alignment Network. (from Dinggang Shen)
本周 10 篇 ML 精选论文是:
1. Jointly Attacking Graph Neural Network and its Explanations. (from Jiliang Tang, Charu Aggarwal)
2. Meta-repository of screening mammography classifiers. (from Kyunghyun Cho)
3. A Look at the Evaluation Setup of the M5 Forecasting Competition. (from Rob J Hyndman)
4. Skill Preferences: Learning to Extract and Execute Robotic Skills from Human Feedback. (from Pieter Abbeel)
5. Edge-augmented Graph Transformers: Global Self-attention is Enough for Graphs. (from Mohammed J. Zaki)
6. Mixture of Linear Models Co-supervised by Deep Neural Networks. (from Jia Li)
7. Learning Bias-Invariant Representation by Cross-Sample Mutual Information Minimization. (from Jiebo Luo)
8. Label-informed Graph Structure Learning for Node Classification. (from Liang Wang)
9. Explaining Algorithmic Fairness Through Fairness-Aware Causal Path Decomposition. (from Changshui Zhang, Fei Wang)
10. The Benefits of Implicit Regularization from SGD in Least Squares Problems. (from Sham M. Kakade)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com