DeepMind首个战胜星际2职业玩家的AI为何无敌?新视角揭秘AI里程碑

新智元2019新年寄语
2018年人工智能成为重塑世界格局的关键。谷歌BERT模型刷新多项自然语言处理纪录,DeepMind则用星际争霸II对局再次引爆机器智能无限可能。阿里与华为分别推出AI芯片,作为底层支撑的计算体系结构也将迈入黄金十年发展期。
新智元2018年实现全球超过50万核心产业用户互联。2019新春,中国人工智能将迎来全新的竞争挑战与生态建设契机,新智元邀你与全球人工智能学术、产业精英一起,以开放的胸怀和坚毅的决心,成就AI新世界!
——新智元创始人兼CEO 杨静

新智元报道
来源:arxiv 编辑:大明,文强
【新智元导读】深度强化学习、多智体强化学习以及博弈论,是DeepMind战胜职业星际II玩家的智能体AlphaStar的重要技术。伦敦帝国大学和NYU研究人员则从进化计算的角度指出,AlphaStar使用的竞争协同进化算法策略被远远低估。
DeepMind首次战胜星际II职业玩家的AI——AlphaStar,正如新智元创始人兼CEO杨静女士在《新智元2019年寄语》中所说的那样,引爆机器智能无限可能。
AlphaStar是一项壮举,是建立在DeepMind及其他研究人员多年的研究和工程基础之上,尤其是深度强化学习(DRL)、多智体强化学习(MARL)和博弈论。
虽然在官方博文中,DeepMind也提到了进化算法(Evolutionary Algorithm, EA),但这显然并非其重点。不过,伦敦帝国学院的Kai Arulkumaran等人,反过来从进化算法的角度来看AlphaStar,希望对深度强化学习领域和进化计算的研究者都带来启发。
进化计算和深度学习并非对立的两个阵营。
事实上,Arulkumaran等人最新在Arxiv上贴出的论文《从进化计算角度看AlphaStar》(AlphaStar: An Evolutionary Computation Perspective),也确实提出了很多新的问题。
例如,在DeepMind提出的快速调参算法PBT中,用Baldwinian进化算法代替拉马克(Lamarckian)进化,是否能得到元学习星际II智能体?
Arulkumaran本人也在Twitter表示,这篇文章是对一系列概念的高级概括,还需要进一步探索,他们在写作时有意识地省略了演化计算和博弈论之间重叠的部分。
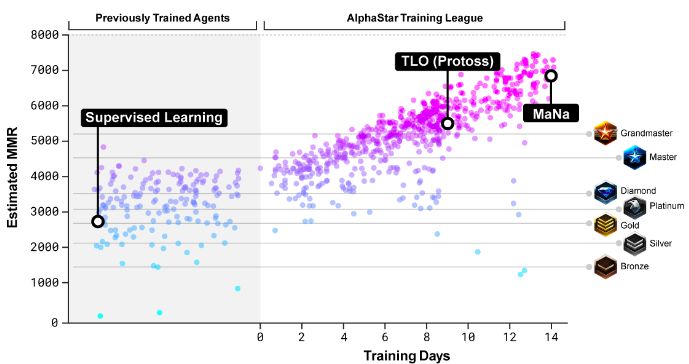
同时,他也指出,不能认为AlphaStar仅仅只是一个演化算法,AlphaStar的混合性质有些类似于AlphaGo atm。“DeepMind官方博文显示了从IL阶段MMR的提升,这一点看起来很重要,但哪些细节是最重要的,我们目前还不知道。”
以下是新智元对文章的编译。

2019年1月,DeepMind向世界展示了AlphaStar——第一个在星际争霸II游戏中击败职业玩家的人工智能(AI)系统,它代表了人工智能技术进步的一个里程碑。
AlphaStar涉及人工智能研究的许多领域,包括深度学习,强化学习,博弈论和进化计算等(EC)。
在本文中,我们主要通过进化计算的角度来分析AlphaStar,为审视该系统提供一个新的视角,并将其与AI领域的许多概念关联起来。我们重点介绍其中一些最有趣的方面:拉马克进化、协同竞争进化和质量多样性。希望通过本文,在更广泛的进化计算社区与新诞生的这个重要的AI系统之间架起一座桥梁。
在1997年”深蓝“击败国际象棋世界冠军后,人工智能与人类博弈的下一个重要里程碑是出现在2016年,围棋世界冠军李世乭被AlphaGo击败。国际象棋和围棋此前都被认为是AI取得进展最困难的领域,可以说,与之相比难度相当的考验之一就是击败星际争霸(SC)游戏中的大师级玩家。
星际争霸是一款即时战略(RTS)游戏。《星际1》及其续作《星际II》都具有几个特点,使得它甚至比围棋的挑战更大。比如只能观察到战场的一部分、没有单一的主导策略、复杂的游戏规则、快速建模的难度更大,动作空间极大,且复杂多变等。可以说,想实现征服《星际争霸》的目标,一点也不比围棋上的突破来得容易。
想实现征服《星际争霸》的目标,一点也不比围棋上的突破来得容易。图片来源:Jesus Rodriguez, The Science Behind AlphaStar
最近,DeepMind推出的AlphaStar向着实现这个目标迈出了重要一步,AlphaStar是一个基于神经网络的AI系统,在2018年12月击败了专业的SC II玩家。
该系统与其前身AlphaGo一样,最初使用模仿学习来模仿人类的游戏行为,然后通过强化学习(RL)和自我对弈的组合方式进行改进。
算法在这里发生了分歧,因为AlphaStar利用基于人口的训练(PBT)来明确地保持一群相互训练的智能体。这部分训练过程建立在多智能体强化学习和博弈论视角之上,但人口的概念是进化计算的核心,因此我们也可以通过这个视角来考察AlphaStar。
目前,训练神经网络参数的最流行的方法是反向传播(BP)。但是,有许多方法可以调整其超参数,包括进化算法。
其中一种方法是使用模因算法(MA),这个算法中,进化作为外部优化算法运行,并且各个解决方案可以通过内环中的其他方式(例如反向传播)来进行优化。在这种特定情况下,模因算法可以将进化算法的探索和全局搜索属性与反向传播算法的高效本地搜索的优势结合起来。
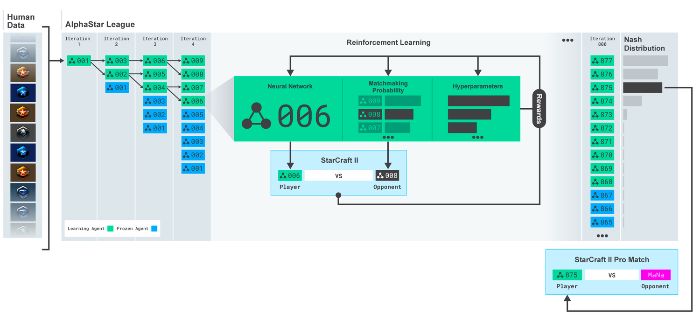
AlphaStar的基本架构。来源:DeepMind
在AlphaStar中,用于训练智能体的基于人口的训练策略(PBT)是使用拉马克进化(LE)的模因算法:在内环中,使用反向传播连续训练神经网络,而在外环中,使用几种选择方法中的一种来选择网络(比如淘汰制锦标赛选择),用胜者的参数覆盖败者的参数,败者也会收到胜者超参数的“变异”副本。
PBT策略最初是通过一系列监督学习和强化学习任务展示的,调整和提升神经网络的性能。对于具有高度非平稳损耗表面的问题,例如深度强化学习问题,这种策略可能是最有效的,因为它可以在运行过程中改变超参数。
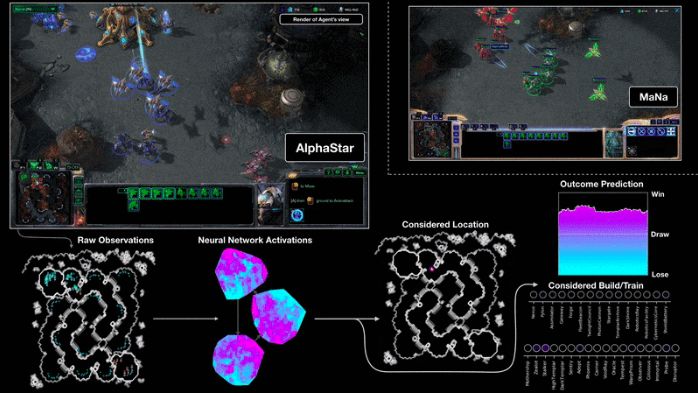
AlphaStar vs MaNa,神经网络如何将观察到的结果转换为行动。来源:DeepMind
由于单个网络可能需要高达数G的内存,或需要训练长达几个小时,因此可扩展性是PBT的关键。因此,PBT既是异步的,又是分布式的。与使用静态超参数运行许多实验不同,使用相同数量的硬件,利用PBT只需要很少的开销——外部循环可以重用内部循环的解决方案进行评估,而且数据通信量也比较低。如果考虑非平稳超参数因素和对较弱解决方案的优先抢占的影响,PBT方案能够节省的成本更多。
这些要求的另一个结果是PBT是稳定状态,这一点与分代进化算法不同。由于对异步进化算法和拉马克进化的自然适应性,稳态进化算法可以允许各个解决方案的优化和评估不间断地进行,从而实现资源效率最大化。
最适合的解决方案能够存活更长时间,自然地提供了一种精英主义/名人堂模式,但并非最优的前代方案也可以保留下来,保持解决方案多样性。
在对AlphaStar一类游戏智能体进行优化时,智能体可以使用自对战来提升水平。
竞争性协同进化算法(CCEA)可以被视为自我对弈的超集(superset),并非只保留当前解决方案及其前身,而是保持和评估整个解决方案的群体。
与自我对弈一样,CEA形成了一个自然的教学过程,但也提供了额外的稳健性,因为产生的解决方案是基于各种其他解决方案进行评估的。
AlphaStar的训练过程。来源:DeepMind
通过在CCEA环境中使用PBT策略,利用基于反向传播的深度强化学习,再加上进化版的奖励函数,能够训练智能体从像素级入手,开始学习玩第一人称游戏。
CEA的设计包括很多方面,这种方法的特征可能导致许多潜在的变体。
在《星际争霸》中,没有所谓“最好的策略”。因此,最终的AlphaStar智能体由纳什分布的人口组成,构成一组互补的、最不可利用的策略。
为了改进训练方式,增加最终解决方案的多样性,明确鼓励多样性是有意义的。
AlphaStar也可以归为质量多样性(QD)算法。尤其是,智能体可以具有游戏特定的属性,例如构建特定类型的额外单位,以及击败某个其他智能体的标准,击败一组其他智能体的标准,甚至是上述这些要素的混合。
此外,这些特定标准也可以在线调整,这对于QD算法而言属于全新的特性——除了POET以外。这使得智能体可以做到更多的事情:可以从人类数据中提取有用的信息,甚至进行无监督学习。
考虑到一系列不同的策略,下一步将自然而然地推断哪种策略可能最适合对付给定的对手,从而实现在线适应。
虽然AlphaStar是一个复杂的系统,涉及人工智能研究的许多领域,但我们认为,迄今为止被低估的一点是竞争性协同进化算法策略。它结合了拉马克进化,共同进化和质量多样性,达到了惊人的效果。
希望本文能够让进化计算和深度强化学习社区更好地欣赏和构建这个重要的AI系统。
论文链接:
https://arxiv.org/pdf/1902.01724.pdf
加入社群
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信 aiera2015_1 入群;通过审核后我们将邀请进群,加入社群后请修改群备注(姓名-公司-职位;专业群审核较严,敬请谅解)
加入新智元社群,成就AI新世界!

