CVPR 2019 | 腾讯AI Lab联合清华大学提出基于骨骼姿态估计的人体实例分割
机器之心发布
作者:清华、卡迪夫、腾讯AI Lab
目前主流实例分割方法都严重依赖于物体的边界框检测,很少有研究者在实例分割中考虑「人」这一个类别的特殊性。在这篇论文中,清华大学、腾讯AI Lab、卡迪夫大学等机构的研究者提出利用骨架检测来定位人体实例,从而构建更高效的实例分割方法。
目前主流的高精度实例物体分割框架都是基于很强的物体检测方法,如 Fast/Faster R-CNN, YOLO 等。虽然不同的方法设计了不同的结构,但是这些方法都遵循着一个基本的规则:首先从图像中生成大量的候选区域,然后用非极大值抑制(NMS)算法从这些数以千计的候选区域中剔除那些重复的候选区域。
但是当图像中有两个高度重叠物体时,NMS 会将其中一个的包围框认为成重复的候选区域然后删掉它。这就意味着几乎所有的基于物体检测的实例分割框架无法处理图像中物体具有高度重叠的情况。
然而在各种物体类别中,「人」是一个很特殊的类别。因为在目前的计算机视觉研究领域,「人体骨骼姿态」已经有了很完备的定义以及丰富的数据标注。相比于包围框,人体骨骼姿态由于包含更多更精准的定位信息,更适合用于区分图像中高度交叠的人体实例(如图 1 所示)。

图 1. 人体骨骼姿态比包围框具有更强的区分图像中严重交叠的人体实例的能力。
通常情况下,实例物体分割框架都会包含一个「对齐模块」,如 Mask R-CNN 中的 RoI-Align、Fast/Faster R-CNN 中的 RoI-Pooling 等。我们提出了一个基于人体骨骼姿态的对齐方法,叫做 Affine-Align。
与基于包围框的对齐算法(如 RoI-Align)不同的是,我们的 Affine-Align 不仅包含了缩放操作与平移操作,还包含了旋转操作和左右翻转操作。因此 Affine-Align 可以被认为是 RoI-Align 的一种更加通用的版本。
另外,Affine-Align 还有一个优点是可以将图中一些奇怪的姿势的人摆正,比如图 2 中所示的那个滑雪的人。正常的姿态朝向可以降低 CNNs 的学习难度,从而达到更高的准确度。

图 2. 对比 Roi-Align 与我们的 Affine-Align
本质上,人体骨骼姿态和人体实例的分割掩模并不是毫不相关的。人体骨骼姿态可以被近似地认为是分割掩模的一种收缩模式。所以我们将人体姿态关键点转化为一种骨骼特征图,并将它与图像特征图拼接,送入分割模块。实验表明我们的人体姿态特征图能显著地帮助提高分割算法的准确度。
此外,我们还提出了一个新的数据集基准 OCHuman。这个数据集包含 4731 张图像,其中有 8110 个经过精心标注的人体实例。全部标注有包围框、人体姿态关节点、以及实例分割掩模。
数据集中的每个人体都有大概 70% 左右的面积被另一个或者多个人所遮挡。这样高度的人与人之间的纠缠与遮挡情况使这个数据集成为了目前与人有关的最有挑战性的数据集。
我们的主要贡献点可以总结为:
提出了一个全新的基于人体骨骼姿态的实例分割框架。这个框架可以比基于包围框的框架取得更好的效果,特别是对于那些严重遮挡的情况。
提出了一个基于人体姿态关节点的对齐算法,叫做 Affine-Align。这个算法可以将图像按照图中的人体关节点进行缩放和矫正对齐。
显示地设计了一种人体骨骼特征图,并用其指引分割模块进行图像分割,取得了更高的分割准确率。
提出了一个新的数据集基准 OCHuman。这个数据集专注于严重遮挡问题,并包含丰富完善的标注。
我们提出的方法
图 3 展示了我们的算法总览。算法的输入是一张图像和多人的人体姿态。我们的算法首先使用一个特征提取网络提取图像的特征,然后用 Affine-Align 将每个实例区域对齐到一个固定的尺度。并引入人体骨骼特征图(Skeleton Features)改善分割效果。下文中将仔细介绍整个系统的每个步骤。
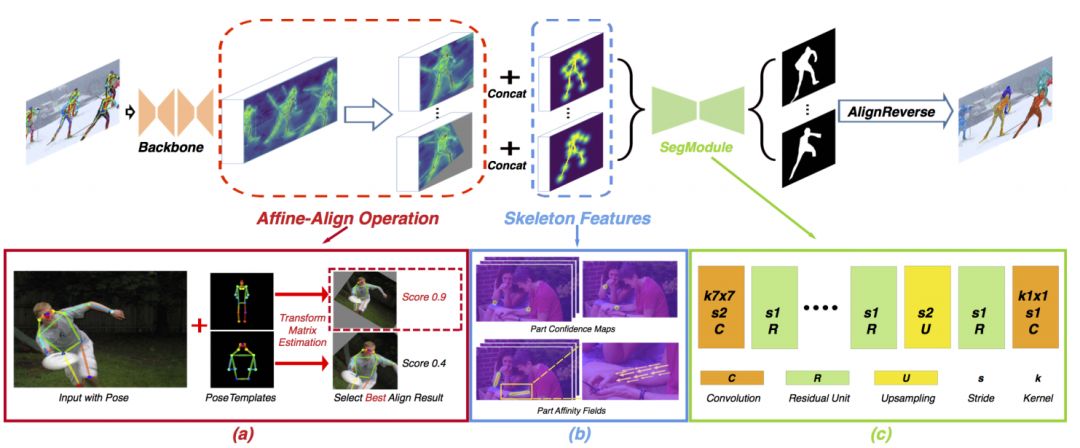
图 3. 我们的算法总览
基于人体姿态关节点的旋转对齐操作(AffineAlign)
如图 3 (a) 所示,算法首先用 K-means 优化下式对训练集中的所有人体姿态进行聚类,并取每个类的聚类中心作为姿态模版构成姿态模版库。
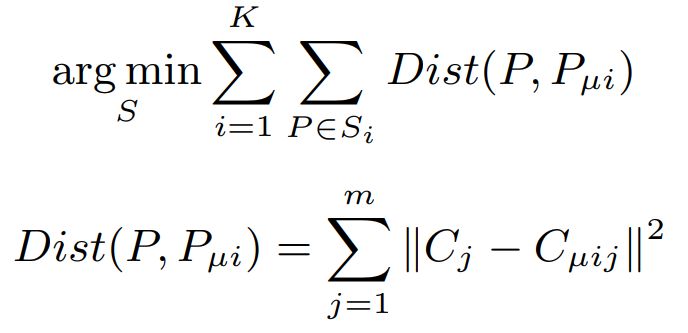
然后对于图像中的每个人体实例的姿态输入,通过求解下式优化问题估计姿态模版与输入姿态之间的仿射变换矩阵,并选择一个对齐误差最小(score 最大)的仿射矩阵 H 作为这个输入姿态的对齐矩阵。
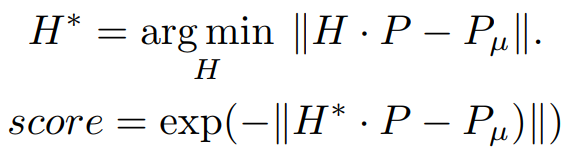
最后,我们用这个矩阵 H 结合仿射变换来对齐特征区域。
骨骼姿态特征图(Skeleton Features)
如图 3 (b) 所示,我们采用 OpenPose 提出的骨骼漂移场(PAFs)来表示人体姿态中不同关节点之间的连接,也就是骨骼。对于每一对关节点,PAFs 是一个 2 通道的特征图,分别表示这对关节点漂移向量在 (x, y) 方向上的分量。
此外,为了强化部位关节点的局部区域,我们还对每个部位关节点生成了一个高斯核热力图,作为骨骼姿态特征图的一部分。人体的骨骼姿态和人体的分割掩模是有高度的语义相关性的——前者可以看作是后者的中心线。
实验证明我们的骨骼姿态特征图的引入可以为分割预测提供先验知识,从而改善分割的效果。
新的数据集基准 OCHuman
OCHuman 数据集由 4731 张图像组成,其中包含 8110 个人体实例。为了量化地衡量图中的人被其他人遮挡的严重程度,我们定义 MaxIoU 为这个人的包围框与图中所有其他人包围框的最大交并比(IoU)。
OCHuman 数据集中包含的人体实例的 MaxIoU 全部都在 0.5 以上,整个数据集平均 MaxIoU 达到了 0.67,意味着平均每个人都有 67% 的面积区域被其他人所遮挡。这使 OCHuman 成为与人有关的最有挑战性的数据集。图 4 展示了这个数据集的一些样例。

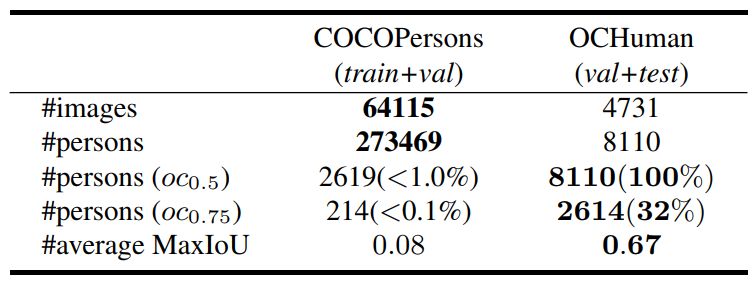
如表 1 所示,我们将 OCHuman 与 COCOPersons 做了对比。COCOPersons 是目前为止既包含人体分割掩模标注,又包含人体姿态关键点标注的最大的数据集。虽然 COCOPersons 有丰富的标注,但是其包含的具有严重遮挡问题的人体实例数量微乎其微。
相比之下,OCHuman 既包含丰富的标注可以支持物体检测算法、人体姿态估计算法和实例分割算法,又包含大量的具有高度挑战性的严重遮挡问题实例。
实验结果

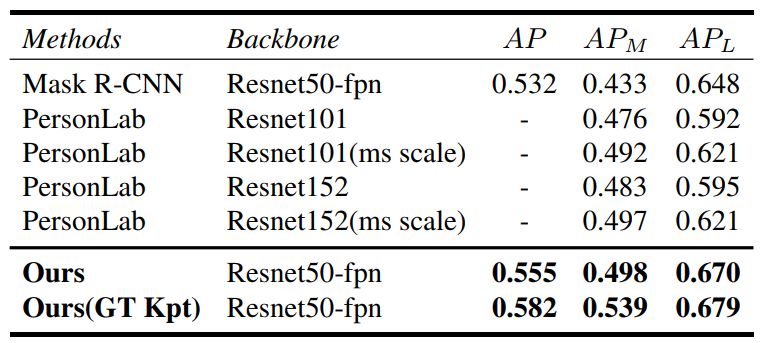
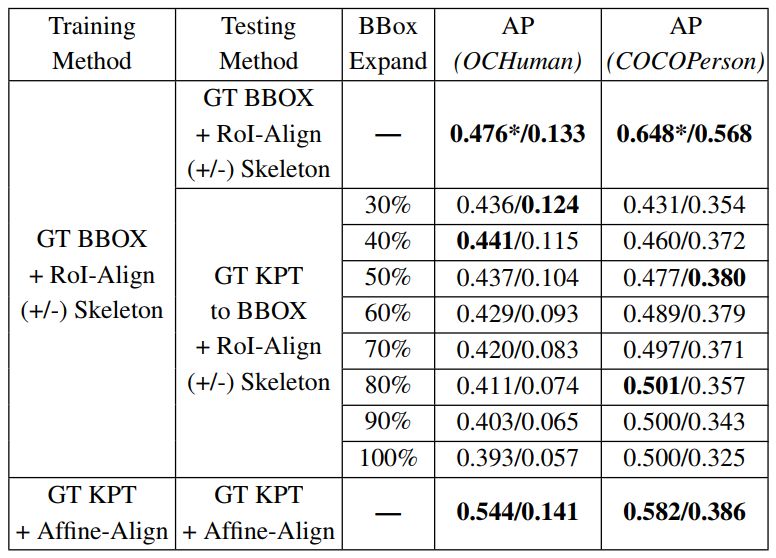
表 4. 研究不同的对齐策略以及人体姿态骨骼特征的对比试验。实验结果分别来自于 OCHuman 验证集与 COCOPersons 验证集。实验的输入为标注的(GT)包围盒信息(BBOX)和人体姿态关节点信息(KPT)。「GT KPT to BBOX」代表从这些关节点坐标位置中找到最大和最小值来确定一个包围框,并将这个包围框向周围扩展一定的程度。标*的数值表示该结果依赖于 BBOX 和 KPT 两种输入信息,其他的结果仅依赖于其中一种。

图 5. 我们的方法与 Mask R-CNN 在具有严重遮挡问题的图片上的效果比较。为了方便可视化,我们额外地用实例分割结果生成了包围盒展示在图中。

论文:Pose2Seg:不依赖于包围框检测的人体实例分割框架(Pose2Seg: Detection Free Human Instance Segmentation)

论文地址:https://arxiv.org/abs/1803.10683
主页地址:http://www.liruilong.cn/projects/pose2seg/index.html
代码地址:https://github.com/liruilong940607/Pose2Seg
数据集地址:https://github.com/liruilong940607/OCHumanApi
目前主流实例物体分割方法的思路都是首先检测图像中物体的包围框,然后利用包围框区分图像中的不同物体并定位,最后用一个分割模块从这个包围框区域中分割出物体实例。
近年来也有一些方法将上述过程合二为一,形成了一个并行的实例物体分割框架,例如 Mask R-CNN。但是这些方法都严重依赖于物体的包围框检测算法。并且,很少有研究者在实例物体分割这个问题中考虑到「人」这一个类别的特殊性——不同于其他类别的物体,「人」有完备的人体骨架的定义。
对于「人」这个特殊的类别来说,利用骨架检测来定位人体实例显然比包围框有更丰富的定位信息,从而有潜力更准确地定位人体。同时,图像中人体骨架由于比包围框有更大的区分度,基于骨架检测来定位人体实例可以有效改善严重遮挡情况下的不同人体实例的区分。
本文将介绍一种全新的基于人体姿态的实例分割框架。本文中的实验表明这个方法可以比基于包围框的实例分割方法达到更高的准确度,同时可以更好地解决基于包围框的方法无法解决的严重遮挡问题。

本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


