三味Capsule:矩阵Capsule与EM路由
作者丨苏剑林
单位丨广州火焰信息科技有限公司
研究方向丨NLP,神经网络
个人主页丨kexue.fm
事实上,在论文《Dynamic Routing Between Capsules》发布不久后,一篇新的 Capsule 论文《Matrix Capsules with EM Routing》就已经匿名公开了(在 ICLR2018 的匿名评审中),而如今作者已经公开,他们是 Geoffrey Hinton,Sara Sabour 和 Nicholas Frosst。
不出大家意料,作者果然有 Hinton。大家都知道,像 Hinton 这些“鼻祖级”的人物,一般发表出来的结果都是比较“重磅”的。那么,这篇新论文有什么特色呢?
在笔者的思考过程中,文章《Understanding Matrix capsules with EM Routing 》[1] 给了我颇多启示,以及知乎上各位大神的相关讨论也加速了我的阅读过程,在此表示感谢。
快速预览
让我们先来回忆一下上一篇介绍再来一顿贺岁宴 | 从K-Means到Capsule中的那个图:
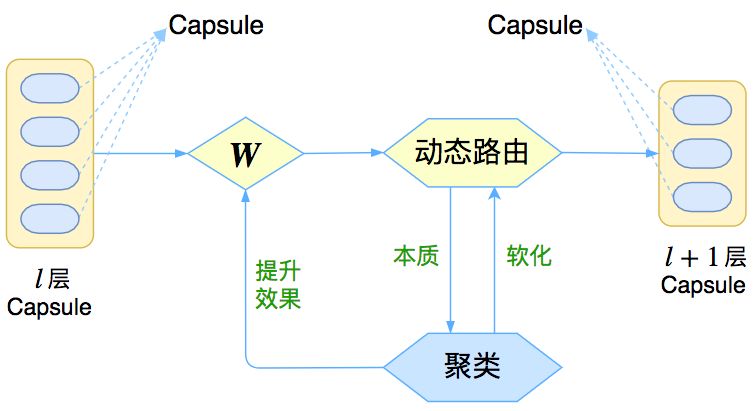
△ 图1:Capsule框架的简明示意图
上图表明,Capsule 事实上描述了一个建模的框架,这个框架中的东西很多都是可以自定义的,最明显的是聚类算法,可以说“有多少种聚类算法就有多少种动态路由”。
那么这次 Hinton 修改了什么呢?总的来说,这篇新论文有以下几点新东西:
原来用向量来表示一个 Capsule,现在用矩阵来表示
聚类算法换成了 GMM(高斯混合模型)
在实验部分,实现了 Capsule 版的卷积
一波疑问
事实上,看到笔者提出的这三点新东西,读者应该就会有很多想法和疑问了,比如:
向量 vs 矩阵
矩阵和向量有什么区别呢?矩阵不也可以展平为向量吗?
其实是有点区别的。比如一个 4×4 的矩阵,跟一个 16 维的向量,有什么差别呢?答案是矩阵的不同位置的元素重要性不一样,而向量的每个元素的重要性都是一样的。
熟悉线性代数的读者应该也可以感觉到,一个矩阵的对角线元素的地位“看起来”是比其他元素要重要一些的。
从计算的角度看,也能发现区别:要将一个 16 维的向量变换为另外一个 16 维的向量,我们需要一个 16×16 的变换矩阵;但如果将一个 4×4 的矩阵变换为另外一个 4×4 的矩阵,那么只需要一个 4×4 的变换矩阵,参数量减少了。
从这个角度看,也许将 Capsule 从向量变为矩阵的根本目的是降低计算量。
立方阵
以后的 Capsule 可能是“立方阵”甚至更高阶张量吗?
不大可能。因为更高阶张量的乘法本质上也是二阶矩阵的乘法。
GMM vs K-Means
GMM 聚类与你之前说的 K-Means 聚类差别大吗?
这个得从两个角度看。一方面,GMM 可以看成是 K-Means 的升级版,而且它本身就是可导的,不需要之前的“软化”技巧,如果在 K-Means 中使用欧氏距离的话,那么 K-Means 就是 GMM 的一个极限版本。
但另一方面,K-Means 允许我们更灵活地使用其他相似的度量,而 GMM 中相当于只能用(加权的)欧氏距离,也就是把度量“写死”了,也是个缺点。总的来说,两者半斤八两吧。
Capsule 版的卷积
Capsule 版的卷积是怎么回事?
我们所说的动态路由,事实上就只相当于深度学习中的全连接层,而深度学习中的卷积层则是局部的全连接层。那么很显然,只需要弄个“局部动态路由”,那么就得到了 Capsule 版的卷积了。
这个东西事实上在 Hinton 上一篇论文就应该出现,因为它跟具体的路由算法并没有关系,但不知为何,Hinton 在这篇新论文才实现了它。
GMM 模型简介
既然这篇新论文用到了 GMM 来聚类,那么只要花点功夫来学习一下 GMM 了。理解 GMM 算法是一件非常有意思的事情,哪怕不是因为 Capsule——因为 GMM 模型能够大大加深我们对概率模型和机器学习理论(尤其是无监督学习理论)的理解。
当然,只想理解 Capsule 核心思想的读者,可以有选择地跳过比较理论化的部分。
本质
事实上,在我们脑海里最好不要将 GMM 视为一个聚类算法,而将它看作一个真正的无监督学习算法,它试图学习数据的分布。数据本身是个体,而分布则是一个整体,从研究数据本身到研究数据分布,是质的改变。
GMM,全称 Gaussian Mixed Model,即高斯混合模型;当然学界还有另一个 GMM——Generalized Method of Moments ,是用来估计参数的广义矩估计方法,但这里讨论的是前者。
具体来说,对于已有的向量 x1,…,xn,GMM希望找到它们所满足的分布 p(x)。当然,不能漫无目的地找,得整一个比较简单的形式出来。GMM 设想这批数据能分为几部分(类别),每部分单独研究,也就是:

其中 j 代表了类别,取值为 1,2,…,k,由于 p(j) 跟 x 没关系,因此可以认为它是个常数分布,记 p(j)=πj。然后 p(x|j) 就是这个类内的概率分布,GMM 的特性就是用概率分布来描述一个类。
那么它取什么好呢?我们取最简单的正态分布,注意这里 x 是个向量,因此我们要考虑多元的正态分布,一般形式为:
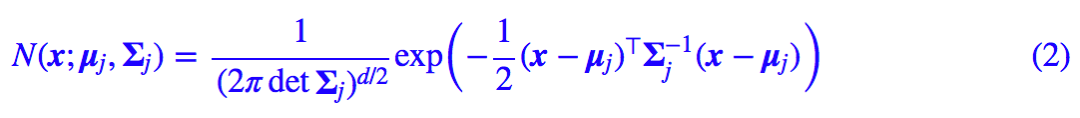
其中 d 是向量 x 的分量个数。现在我们得到模型的基本形式:
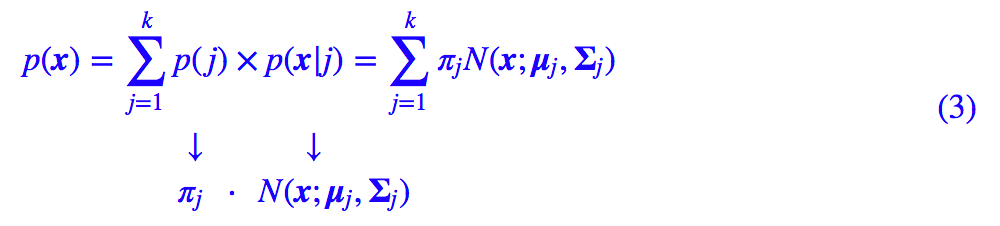
求解
现在模型有了,但是未知的参数有 πj,μj,Σj,怎么确定它们呢?
理想的方法是最大似然估计,然而它并没有解析解,因而需要转化为一个 EM 过程,但即使这样,求解过程也比较难理解(涉及到行列式的求导)。
这里给出一个比较简单明了的推导,它基于这样的一个事实——对于正态分布来说,最大似然估计跟前两阶矩的矩估计结果是一样的。
说白了,μj,Σj 不就是正态分布的均值(向量)和(协)方差(矩阵)嘛,我直接根据样本算出对应的均值和方差不就行了吗?
没那么简单,因为我们所假设的是一个正态分布的混合模型,如果直接算它们,得到的也只是混合的均值和方差,没法得到每一类的正态分布 p(x|j) 的均值和方差。
不过我们可以用贝叶斯公式转化一下,首先我们有:
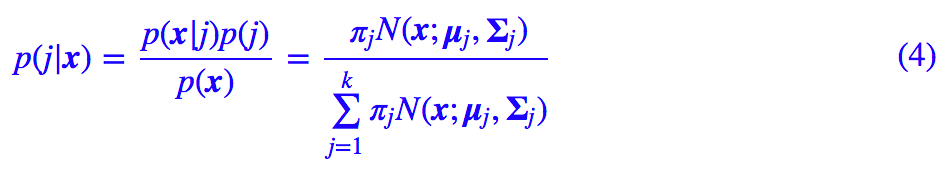
比如对于均值向量,我们有:
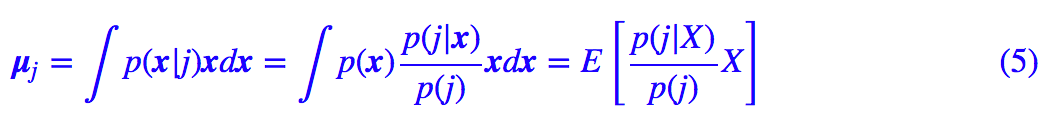
这里 E[] 的意思是对所有样本求均值,那么我们就可以得到:
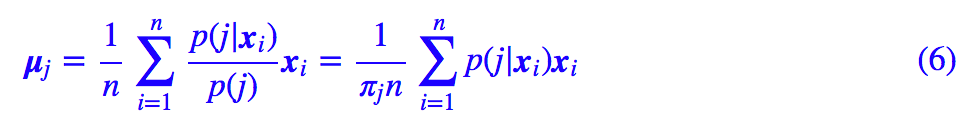
其中 p(j|x) 的表达式在 (4) 已经给出。类似地,对于协方差矩阵,我们有:
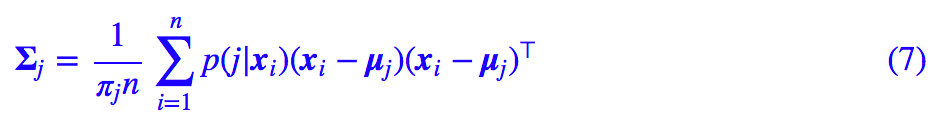
然后:
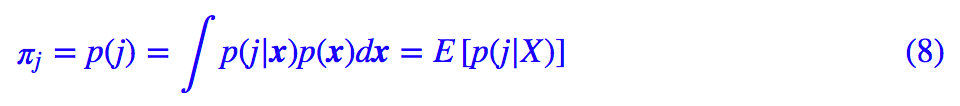
所以:

理论上,我们需要求解 (6),(7),(9) 构成的一个巨大的方程组,但这样是难以操作的,因此我们可以迭代求解,得到迭代算法:
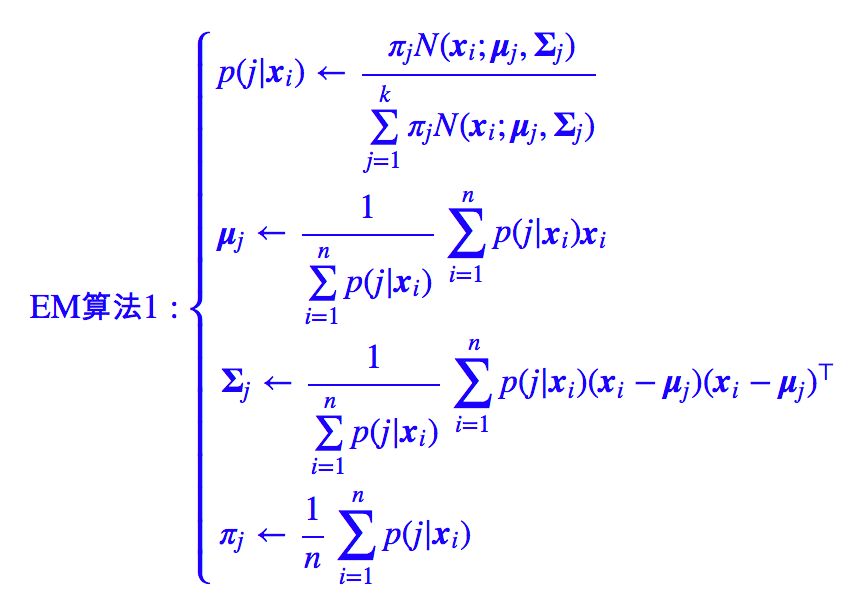
其中为了突出加权平均的特点,上述迭代过程先将 (9) 式作了恒等变换然后代入 (6),(7) 式。在上述迭代过程中,第一式称为 E 步,后三式称为 M 步,整个算法就叫做 EM 算法。
下面放一张网上搜索而来的动图来展示 GMM 的迭代过程,可以看到 GMM 的好处是能识别出一般的二次曲面形状的类簇,而 K-Means 只能识别出球状的。
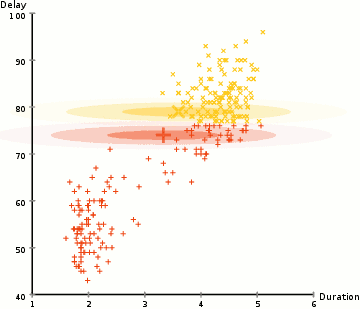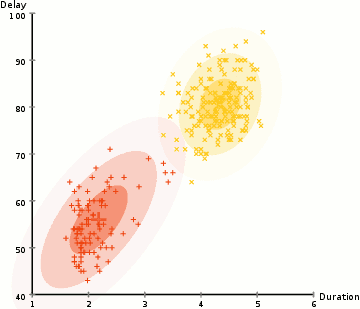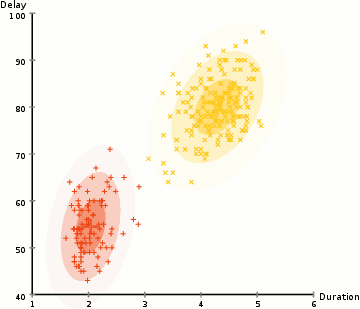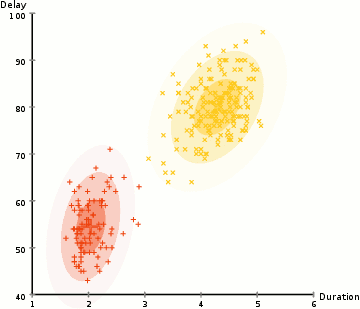
△ 图2:GMM 迭代过程展示
约简
在 Capsule 中实际上使用了一种更加简单的 GMM 形式,在前面的讨论中,我们使用了一般的正态分布,也就是 (2) 式,但这样要算逆矩阵和矩阵的行列式,计算量颇大。
一个较为简单的模型是假设协方差矩阵是一个对角阵 Σj=diagσj,σj 是类别 j 的方差向量,其中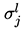
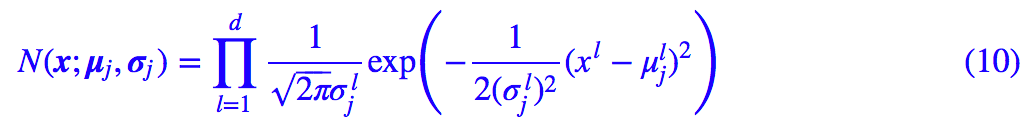
而迭代过程也有所简化:
更简单些
如果所有的
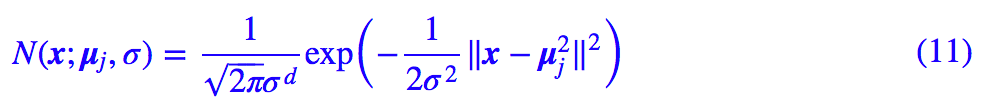
这样整个分布就更为简单了,有意思的是,在指数的括号内出现了欧氏距离。
更极端地,我们让 σ→0 呢?这时指数内的括号为无穷大,对于每个 xi,只有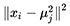
这表明任意一个点只属于距离它最近的那个聚类中心,这就跟使用欧氏距离的 K-Means 一致了,所以说,基于欧氏距离的 K-Means 可以看作是 GMM 的一个极限。
新版路由
言归正传,还是说回 Capsule。我们说《Matrix Capsules with EM Routing》中用 GMM 算法完成了聚类过程,现在就来详细看看是怎么做的。
矩阵->向量
不得不说,新论文里边的符号用得一塌糊涂,也许能够在一堆混乱的符号中看到真理才是真正的大牛吧。这里结合网上的一些科普资料以及作者自己的阅读,给出一些理解。
首先,我们用一个矩阵 Pi 来表示第 l 层的 Capsule,这一层共有 n 个 Capsule,也就是 i=1,…,n;用矩阵 Mj 来表示第 l+1 层的 Capsule,这一层共有 k 个 Capsule,也就是聚为 k 类,j=1,…,k。
论文中 Capsule 的矩阵是 4×4 的,称之为 Pose 矩阵。然后呢,就可以开始 GMM 的过程了,在做 GMM 的时候,又把矩阵当成向量了,所以在 EM 路由那里,Pi 就是向量,即 d=16 。整个过程用的是简化版的 GMM,也就是把协方差矩阵约定为一个对角阵。
所以根据前面的讨论,可以得到新的动态路由算法:

这里记了 pij=N(xi;μj,σj),Rij=p(j|xi),符号尽量跟原论文一致,方便大家对比原论文。这里的动态路由的思想跟《Dynamic Routing Between Capsules》的是一致的,都是将 l+1 层的 Capsule 作为 l 层 Capsule 的聚类中心,只是聚类的方法不一样而已。
激活值
在《Dynamic Routing Between Capsules》一文中,是通过向量的模长来表示该特征的显著程度,那么在这里还可以这样做吗?
答案是否定的。因为我们使用了 GMM 进行聚类,GMM 是基于加权的欧氏距离(本质上还是欧氏距离),用欧氏距离进行聚类的一个特点就是聚类中心向量是类内向量的(加权)平均(从上面MjMj的迭代公式就可以看出)。
既然是平均,就不能体现“小弟越多,势力越大”的特点,这我们在再来一顿贺岁宴 | 从K-Means到Capsule中就已经讨论过了。
既然 Capsule 的模长已经没法衡量特征的显著性了,那么就只好多加一个标量 a 来作为该 Capsule 的显著性。所以,这篇论文中的 Capsule,实际上是“一个矩阵 + 一个标量”,这个标量被论文称为“激活值”,如图:
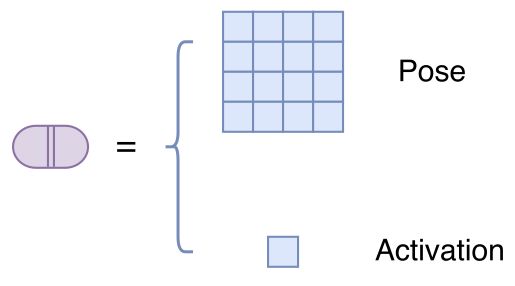
△ 图3:这个版本的Capsule是“矩阵+标量”
作为 Capsule 的显著程度,aj 最直接的选择应该就是 πj,因为 l+1 层的 Capsule 就是聚类中心而 πj 就代表着这个类的概率。
然而,我们却不能选择 πj,原因有两个:
1. πj 是归一化的,而我们希望得到的只不过是特征本身的显著程度,而不是跟其他特征相比后的相对显著程度(更通俗点,我们希望做多个二分类,而不是一个多分类,所以不需要整体归一化)。
2. πj 确实能反映该类内“小弟”的多少,但人多不一定力量大,还要团结才行。那么这个激活值应该怎么取呢?论文给出的公式是:
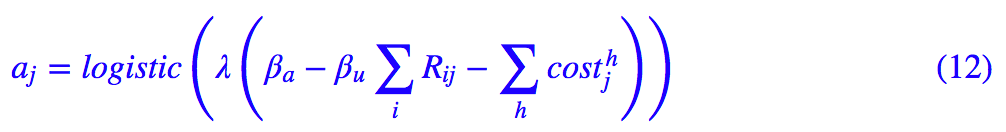
我相信很多读者看到这个公式和论文中的“推导”后,还是不知所云。事实上,这个公式有一个非常漂亮的来源——信息熵。
现在我们用 GMM 来聚类,结果就是得到一个概率分布 p(X|j) 来描述一个类,那么这个类的“不确定性程度”,也就可以衡量这个类的“团结程度”了。
说更直白一点,“不确定性”越大(意味着越接近均匀分布),说明这个类可能还处于动荡的、各自为政的年代,此时激活值应该越小;“不确定性”越小(意味着分布越集中),说明这个类已经团结一致步入现代化,此时激活值应该越大。
因此可以用不确定性来描述这个激活值,而我们知道,不确定性是用信息熵来度量的,所以我们写出:
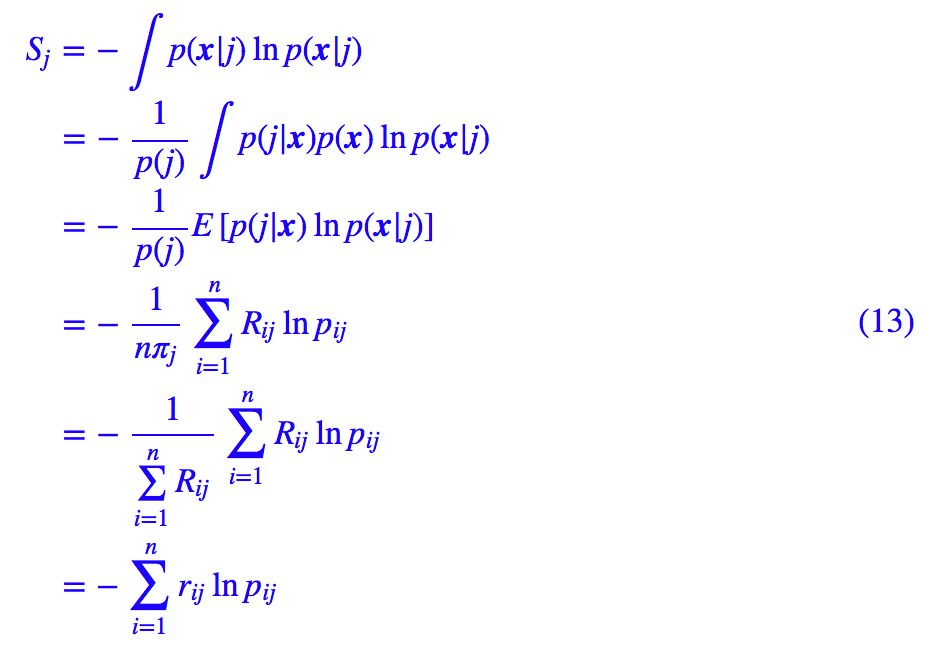
这就是论文中的那个
为什么不直接积分算出正态分布的熵,而是要这样迂回地算?因为直接积分算出来是理论结果,我们这里要根据这批数据本身算出一个关于这批数据的结果。
经过化简,结果是(原论文计算结果应该有误):
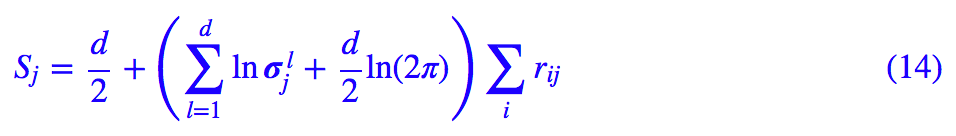
因为熵越小越显著,所以我们用 −Sj 来衡量特征的显著程度,但又想将它压缩为 0~1 之间。那么可以对它做一些简单的尺度变换后用 sigmoid 函数激活:
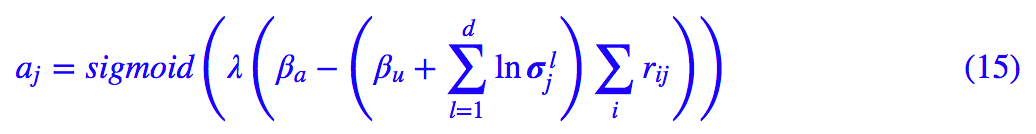
(15) 式和 (13) 式基本是等价的,上式相当于 −Sj 和 πj 的加权求和,也就是综合考虑了 −Sj(团结)和 πj(人多)。
其中 βa,βu 通过反向传播优化,而 λ 则随着训练过程慢慢增大(退火策略,这是论文的选择,我认为是不必要的)。
βa,βu 可能跟 j 有关,也就是可以为每个上层胶囊都分配一组训练参数 βa,βu。说“可能”是因为论文根本就没说清楚,或许读者可以按照自己的实验和需求调整。
有了 aj 的公式后,因为我们前面也说 aj 和 πj 有一定共同之处,它们都是类的某种权重,于是为了使得整个路由流程更紧凑,Hinton 干脆直接用 aj 替换掉 πj,这样替换虽然不能完全对应上原始的 GMM 的迭代过程,但也能收敛到类似的结果。
于是现在得到更正后的动态路由:

这应该就是最终的新的动态路由算法了,如果我没理解错的话,因为原论文实在太难看懂。
权重矩阵
最后,跟前一篇文章一样,给每对指标 (i,j) 配上一个权重矩阵 Wij(称为视觉不变矩阵),得到“投票矩阵”Vij=PiWij,然后再进行动态路由,得到最后的动态路由算法:

结语
评价
经过这样一番理解,应该可以感觉到这个新版的 Capsule 及其路由算法并不复杂。
新论文的要点是使用了 GMM 来完成聚类过程,GMM 是一个基于概率模型的聚类算法。
紧抓住“概率模型”这一特性,寻找概率相关的量,就不难理解 aj 表达式的来源,这应该是理解整篇论文最困难的一点;而用矩阵代替向量,应该只是一种降低计算量和参数量的方案,并无本质变化。
只不过新论文传承了旧论文的晦涩难懂的表达方式,加上混乱的符号使用,使得我们的理解难度大大增加,再次诟病作者们的文笔。
感想
到现在,终于算是把《Matrix Capsules with EM Routing》梳理清楚了,至于代码就不写了,因为事实上我个人并不是特别喜欢这个新的 Capsule 和动态路由,不想再造轮子了。
这是我的关于 Capsule 理解的第三篇文章。相对于笔者的其他文章而言,这三篇文章的篇幅算得上是“巨大”,它们承载了我对 Capsule 的思考和理解。每一篇文章的撰写都要花上好几天的时候,试图尽可能理论和通俗文字相结合,尽可能把前因后果都梳理清楚。
希望这些文字能帮助读者更快速地理解 Capsule。当然,作者水平有限,如果有什么误导之处,欢迎留言批评。
当然,更希望 Capsule 的作者们能用更直观、更具启发性的语言来介绍他们的新理论,这就省下了我们这些科普者的不少功夫了。
毕竟 Capsule 有可能真的是深度学习的未来,怎可如此模糊呢?
相关链接
[1] Understanding Matrix capsules with EM Routing
https://jhui.github.io/2017/11/14/Matrix-Capsules-with-EM-routing-Capsule-Network/

点击以下标题查看相关内容:


2017年度最值得读的AI论文 | NLP篇 · 评选结果公布
2017年度最值得读的AI论文 | CV篇 · 评选结果公布
我是彩蛋
解锁新功能:热门职位推荐!
PaperWeekly小程序升级啦
今日arXiv√猜你喜欢√热门职位√
找全职找实习都不是问题
解锁方式
1. 识别下方二维码打开小程序
2. 用PaperWeekly社区账号进行登陆
3. 登陆后即可解锁所有功能
职位发布
请添加小助手微信(pwbot01)进行咨询
长按识别二维码,使用小程序
*点击阅读原文即可注册

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 进入作者博客


