ICML 2018 | 再生神经网络:利用知识蒸馏收敛到更优的模型
选自arxiv
作者:Tommaso Furlanello等
机器之心编译
参与:王淑婷、思源
知识蒸馏将知识从一个复杂的机器学习模型迁移到另一个紧凑的机器学习模型,而一般紧凑的模型在性能上会有一些降低。本文探讨了同等复杂度模型之间的知识迁移,并发现知识蒸馏中的学生模型在性能上要比教师模型更强大。
在一篇关于算法建模的著名论文(Breiman 等,2001)中,Leo Breiman 指出,不同的随机算法过程(Hansen & Salamon,1990;Liaw 等,2002 年;Chen & Guestrinn,2016)可以产生具有相似验证性能的不同模型。此外,他还指出,我们可以将这些模型组成一个集成算法,从而获得优于单个模型的预测能力。有趣的是,给定这样一个强大的算法集成,人们往往可以找到一个更简单的模型(至少不比集成模型更复杂)来仿效此集成并实现其性能。
在《再生树(Born Again Trees)》(Breiman & Shang,1996)一书中,Breiman 率先提出了这一想法,学习单棵决策树能达到多棵树预测的性能。这些再生树近似集成方法的决策,且提供了决策树的可解释性。随后一系列论文重新讨论了再生模型的概念。在神经网络社区,类似的想法也出现在压缩模型(Bucilua 等,2006)和知识蒸馏(Hinton 等,2015)概念中。在这两种情况下,这种想法通常是把能力强大、表现出色的教师模型的知识迁移给更紧凑的学生模型(Ba & Caruana,2014;Urban 等,2016;Rusu 等,2015)。虽然在以监督方式直接训练学生模型(student)时,其能力不能与教师模型(teacher)相匹配,但经过知识蒸馏,学生模型的预测能力会更接近教师模型的预测能力。
我们建议重新审视知识蒸馏,但侧重点不同以往。我们的目的不再是压缩模型,而是将知识从教师模型迁移给具有相同能力的学生模型。在这样做的过程中,我们惊奇地发现,学生模型成了大师,明显超过教师模型。联想到明斯基的自我教学序列(Minsky』s Sequence of Teaching Selves)(明斯基,1991),我们开发了一个简单的再训练过程:在教师模型收敛之后,我们对一个新学生模型进行初始化,并且设定正确预测标签和匹配教师模型输出分布这个双重目标,进而对其进行训练。
通过这种方式,预先训练的教师模型可以偏离从环境中求得的梯度,并有可能引导学生模型走向一个更好的局部极小值。我们称这些学生模型为「再生网络」(BAN),并表明当应用于 DenseNet、ResNet 和基于 LSTM 的序列模型时,再生网络的验证误差始终低于其教师模型。对于 DenseNet,我们的研究表明,尽管收益递减,这个过程仍可应用于多个步骤中。
我们观察到,由知识蒸馏引起的梯度可以分解为两项:含有错误输出信息的暗知识(DK)项和标注真值项,后者对应使用真实标签获得原始梯度的简单尺度缩放。我们将第二个术语解释为基于教师模型对重要样本的最大置信度,使用每个样本的重要性权重和对应的真实标签进行训练。这说明了 KD 如何在没有暗知识的情况下改进学生模型。
此外,我们还探讨了 Densenet 教师模型提出的目标函数能否用于改进 ResNet 这种更简单的架构,使其更接近最优准确度。我们构建了复杂性与教师模型相当的 Wide-ResNet(Zagoruyko & Komodakis,2016b)和 Bottleneck-ResNet(He 等,2016 b)两个学生模型,并证明了这些 BAN-ResNet 性能超过了其 DenseNet 教师模型。类似地,我们从 Wide-ResNet 教师模型中训练 DenseNet 学生模型,前者大大优于标准的 ResNet。因此,我们证明了较弱的教师模型仍然可以提升学生模型的性能,KD 无需与强大的教师模型一起使用。
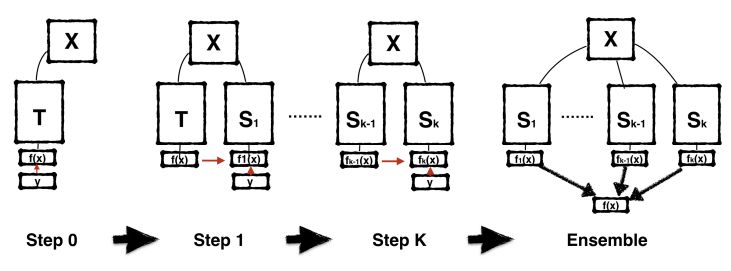
图 1:BAN 训练过程的图形表示:第一步,从标签 Y 训练教师模型 T。然后,在每个连续的步骤中,从不同的随机种子初始化有相同架构的新模型,并且在前一学生模型的监督下训练这些模型。在该过程结束时,通过多代学生模型的集成可获得额外的性能提升。
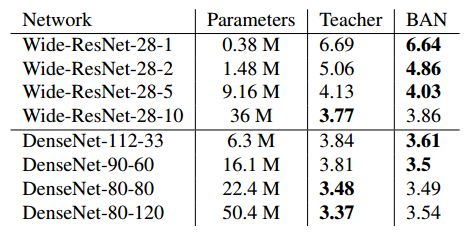
表 1:不同深度和宽度的 Wide-ResNet 与不同深度和增长因子的 DenseNet,在 CIFAR10 数据集上的测试误差。

表 4:Densenet 在修正 CIFAR100 数据集上的测试误差:Densenet-90-60 用作教师模型,与学生模型每次空间转换后的隐藏状态大小相同,但深度和压缩率不同。
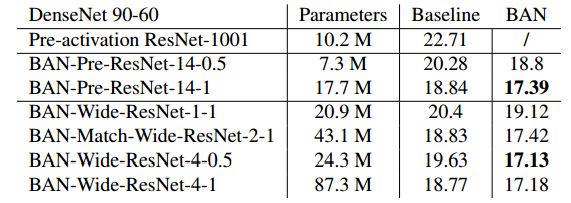
表 5:Densenet 到 ResNet:BAN-ResNet 在 CIFAR100 上的测试误差,后者由具有不同 Dense Block 数和压缩因子的 DenseNet 90-60 教师模型训练而成。在所有 BAN 架构中,首先需要指明每一个卷积模块的单元数量,然后还有关于 DenseNet 90-60 卷积块的输入和输出通道比。所有 BAN 体系结构都与固定后的教师模型共享第一层(conv1)和最后一层(fc-output),每个密集块都被残差块有效地替换。

表 6:不同 BAN-LSTM 语言模型在 PTB 数据集上的验证/测试复杂度
论文:再生神经网络(Born Again Neural Networks)

论文地址:https://arxiv.org/abs/1805.04770
知识蒸馏(KD)包括将知识从一个机器学习模型(教师模型)迁移到另一个机器学习模型(学生模型)。一般来说,教师模型具有强大的能力和出色的表现,而学生模型则更为紧凑。通过知识迁移,人们希望从学生模型的紧凑性中受益,而我们需要一个性能接近教师模型的紧凑模型。本论文从一个新的角度研究知识蒸馏:我们训练学生模型,使其参数和教师模型一样,而不是压缩模型。令人惊讶的是,再生神经网络(BAN)在计算机视觉和语言建模任务上明显优于其教师模型。基于 DenseNet 的再生神经网络实验在 CIFAR-10 和 CIFAR-100 数据集上展示了当前最优性能,验证误差分别为 3.5% 和 15.5%。进一步的实验探索了两个蒸馏目标:(i)由 Max 教师模型加权的置信度(CWTM)和(ii)具有置换预测的暗知识(DKPP)。这两种方法都阐明了知识蒸馏的基本组成部分,说明了教师模型输出在预测和非预测类中的作用。
我们以不同能力的学生模型为实验对象,重点研究未被充分探究的学生模型超过教师模型的案例。我们的实验表明,DenseNet 和 ResNet 之间的双向知识迁移具有显著优势。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com