一文详尽系列之逻辑回归
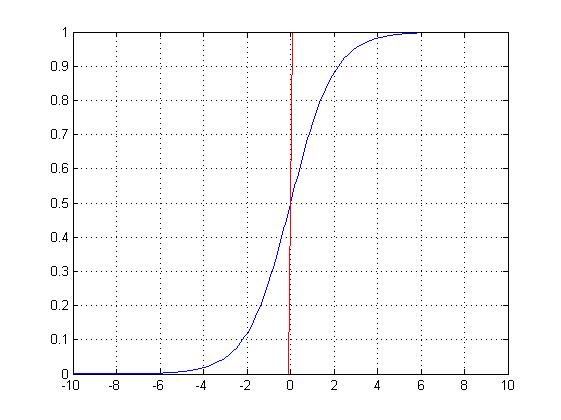
模型介绍
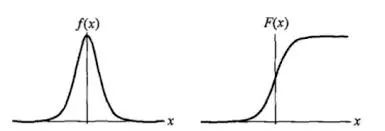
-
直接对分类的概率建模,无需实现假设数据分布,从而避免了假设分布不准确带来的问题; -
不仅可预测出类别,还能得到该预测的概率,这对一些利用概率辅助决策的任务很有用; -
对数几率函数是任意阶可导的凸函数,有许多数值优化算法都可以求出最优解。
-
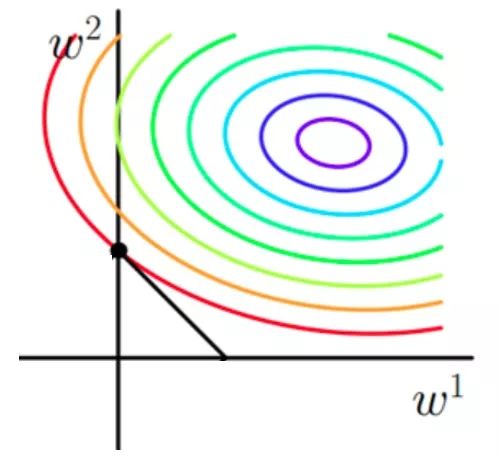
原函数曲线等高线(同颜色曲线上,每一组 带入后值都相同)
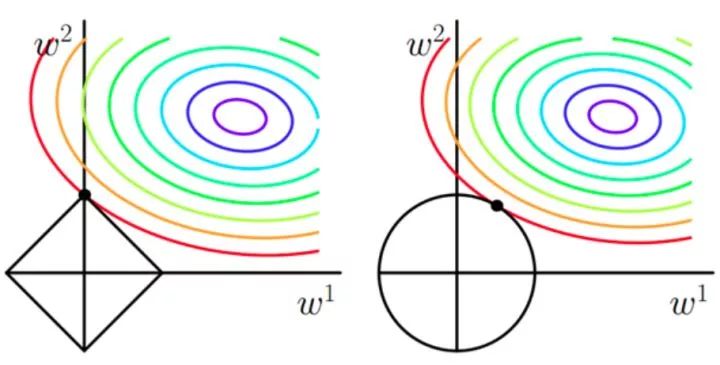
-
如果不加 和 正则化的时候,对于线性回归这种目标函数凸函数的话,我们最终的结果就是最里边的紫色的小圈圈等高线上的点。 -
当加入 正则化的时候,我们先画出 的图像,也就是一个菱形,代表这些曲线上的点算出来的 范数 都为 。 那我们现在的目标是不仅是原曲线算的值要小(越来越接近中心的紫色圈圈),还要使得这个菱形越小越好( 越小越好)。 那么还和原来一样的话,过中心紫色圈圈的那个菱形明显很大,因此我们要取到一个恰好的值。 那么如何求值呢?
-
以同一条原曲线目标等高线来说,现在以最外圈的红色等高线为例,我们看到,对于红色曲线上的每个点都可做一个菱形,根据上图可知,当这个菱形与某条等高线相切(仅有一个交点)的时候,这个菱形最小,上图相割对比较大的两个菱形对应的 范数更大。 用公式说这个时候能使得在相同的 ,由于相切的时候的 $ C||w||_ 1} N} \sum_{i = 1}^N{(y_i -w^T x_i)^2 }+ C $ 更小; -
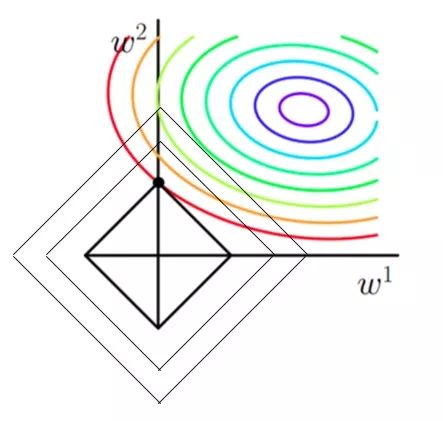
有了第一条的说明我们可以看出,最终加入 范数得到的解一定是某个菱形和某条原函数等高线的切点。 现在有个比较重要的结论来了,我们经过观察可以看到,几乎对于很多原函数等高曲线,和某个菱形相交的时候及其容易相交在坐标轴(比如上图),也就是说最终的结果,解的某些维度及其容易是 0,比如上图最终解是 ,这也就是我们所说的 更容易得到稀疏解(解向量中 0 比较多)的原因; -
当然光看着图说, 的菱形更容易和等高线相交在坐标轴一点都没说服力,只是个感性的认识,我们接下来从更严谨的方式来证明,简而言之就是假设现在我们是一维的情况下 ,其中 是目标函数, 是没加 正则化项前的目标函数, 是 正则项,要使得 0 点成为最值可能的点,虽然在 0 点不可导,但是我们只需要让 0 点左右的导数异号,即
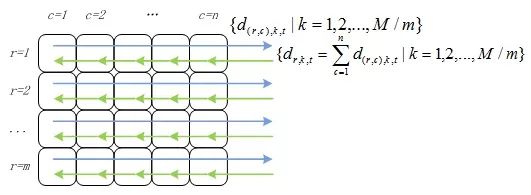
这个过程如下图所示:
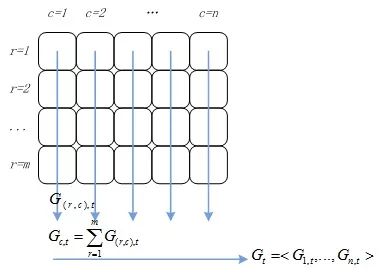
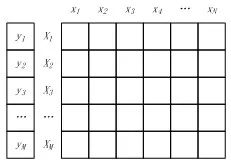
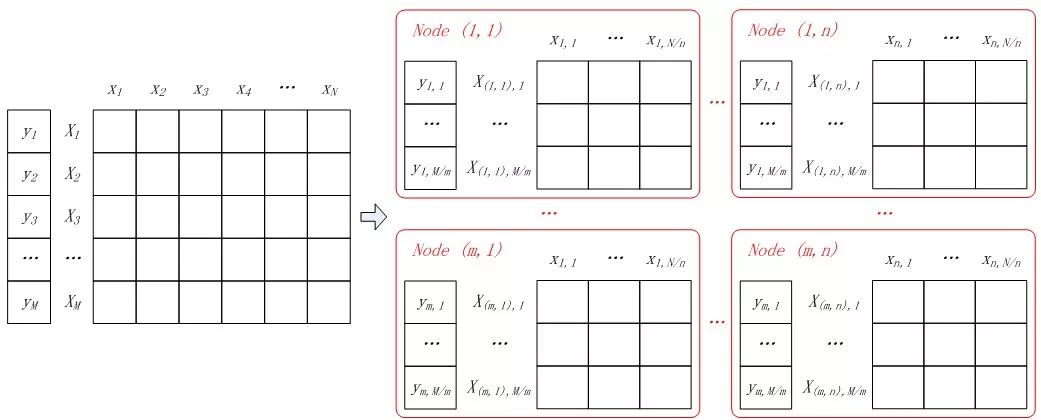
所以并行计算 LR 的流程如下所示。
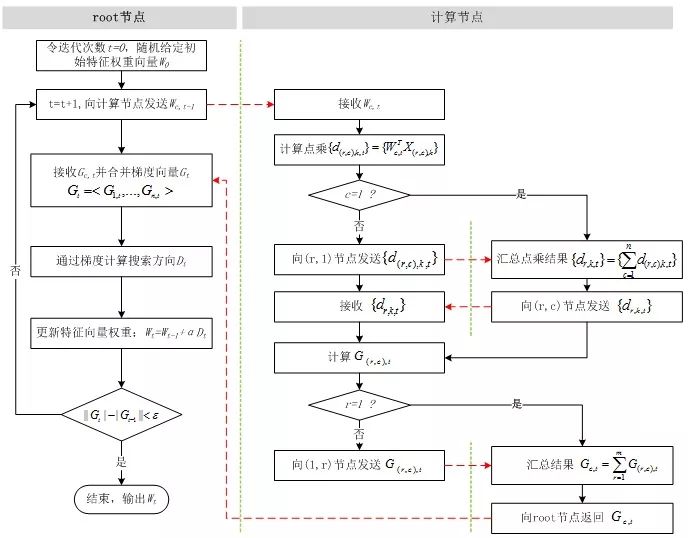
所以并行 LR 实际上就是在求解损失函数最优解的过程中,针对寻找损失函数下降方向中的梯度方向计算作了并行化处理,而在利用梯度确定下降方向的过程中也可以采用并行化。
与其他模型的对比
模型细节
引用
推荐阅读
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。