成为VIP会员查看完整内容
VIP会员码认证
首页
主题
会员
服务
注册
·
登录
0
这场比赛,让上百个AI智能体「卷起来了」
2022 年 8 月 18 日
机器之心
机器之心报道
作者:蛋酱
过去数年,随着神经网络、基于强化学习的自我博弈、多智能体学习和模仿学习等通用机器学习理论的突破,AI 智能体的决策能力实现了飞跃式发展。
可以看到,不管是谷歌、微软、IBM 等全球科技巨头,还是国内一众 AI 龙头企业,在学术研究和产业落地上,它们的关注焦点都在从智能感知向智能决策过渡。「决策 AI」成了领域内的必争之地。
今年 5 月,谷歌旗下的机构 DeepMind 发布 Gato,这款全新的 AI 智能体能够在「广泛的环境中」完成 604 项不同的任务。Gato 的诞生,再次刷新了单智能体的能力上限。当然,关于 AI 决策能力的探索不会仅限于此,如果让海量智能体在一个接近真实世界的开放决策环境中「狭路相逢」,它们会做出何种判断和选择,又会怎样分工合作、竞争呢?
近日,由超参数科技发起,麻省理工学院、清华大学深圳国际研究生院,以及知名数据科学挑战平台 AIcrowd 联合主办的「IJCAI 2022-Neural MMO 海量 AI 团队生存挑战赛」落幕。在这场比赛中,我们发现了一些进行新探索的可能性。
复杂环境中的多智能体博弈
近年来,多智能体环境已经成为深度强化学习的一个有效研究平台。目前,强化学习环境要么足够复杂,但限制条件太多,普适性不强;要么限制条件很少,但过于简单。这些问题限制了更高复杂度任务的创建,也很难激发出多智能体更高阶的决策能力。
2019 年,MIT 博士生 Joseph Suarez 在 OpenAI 实习期间开发了 Neural MMO,他借鉴大型多人在线游戏(MMO),模拟出一个庞大的生态系统,系统中包含数量不等的智能体,并让它们在持久、广阔的环境中竞争。行业人士普遍认为,「这个模拟相当有趣」。与过往着眼于技术水准的 AI 游戏对战环境不同,Neural MMO 涉及到了 AI 的长期判断和选择,更考验智能体的决策能力。
「IJCAI 2022-Neural MMO 海量 AI 团队生存挑战赛」使用的正是上述环境。主办方表示,选择 Neural MMO 主要基于两点:一是 Neural MMO 类似于开放世界生存游戏,本身有一个自运转系统,并且定义了采集、攻击、生存等基本机制,二是它支持海量 AI 共存、交互,并涌现策略。无论在学术界还是工业界,这种环境都不多见。
Neural MMO环境
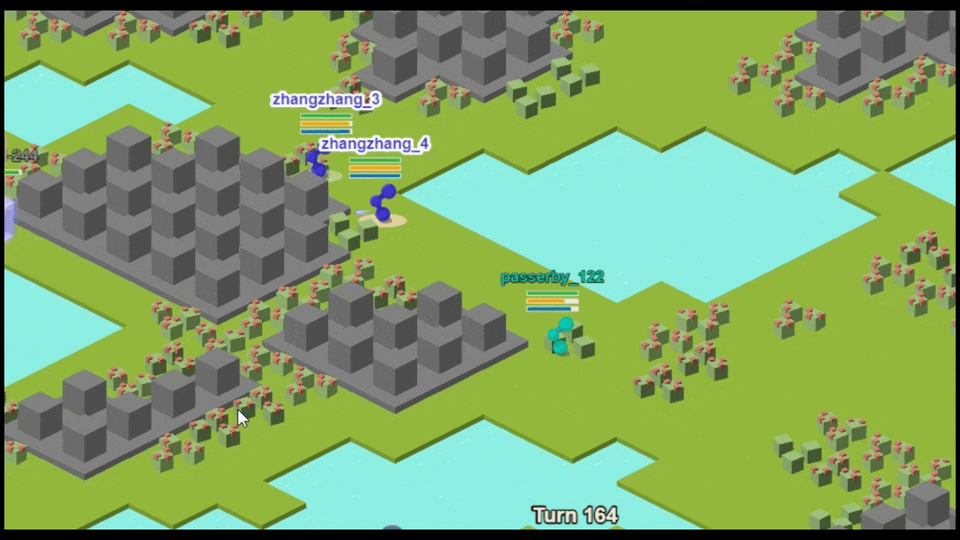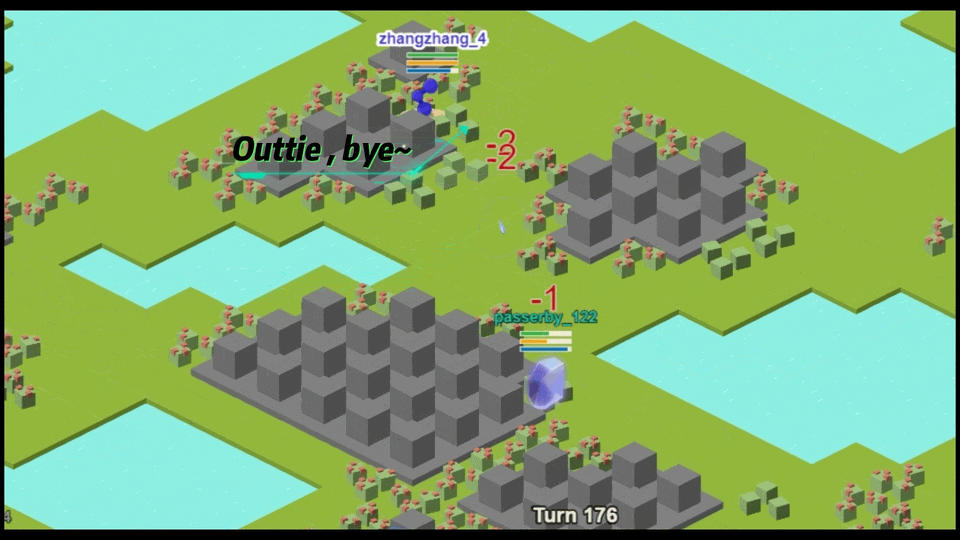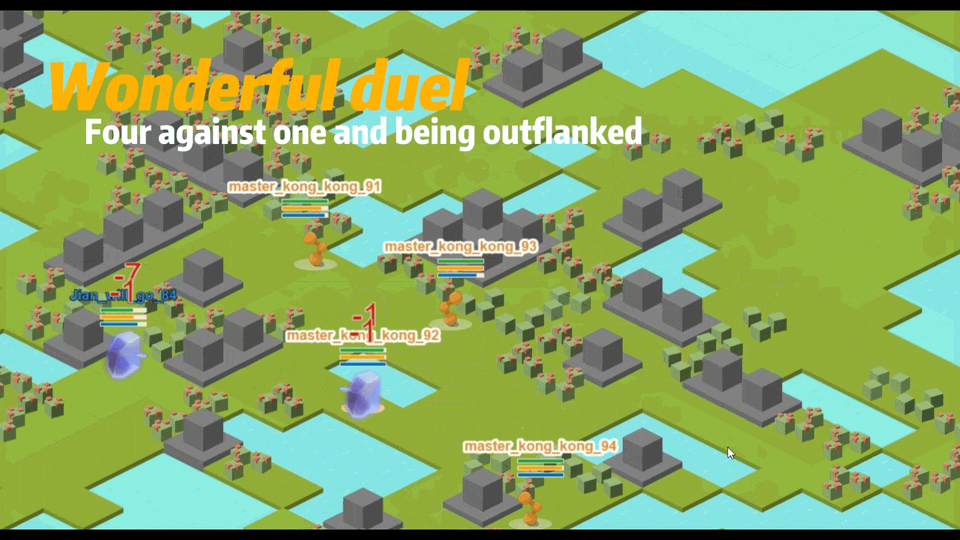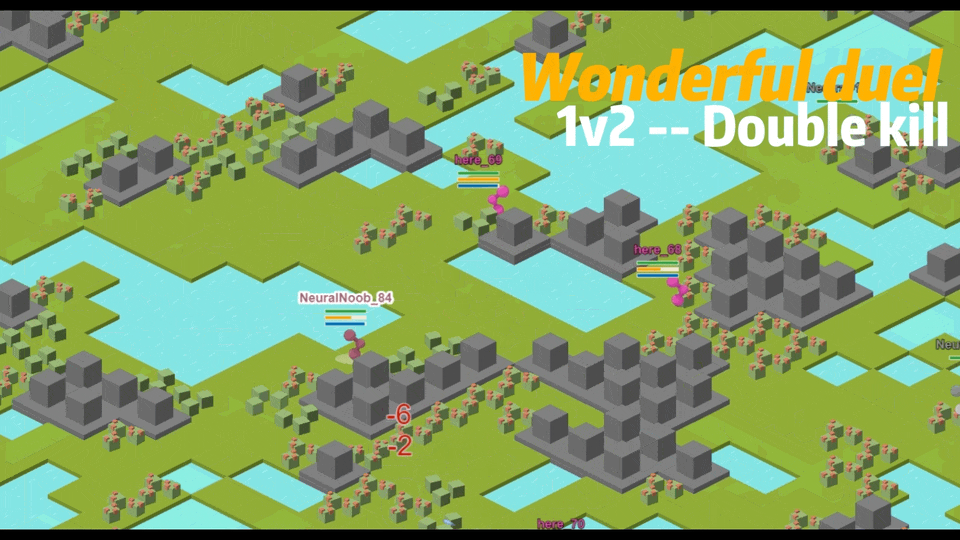
在这场比赛中,每局对战都包含 16 支队伍,每支队伍包含 8 个智能体,这些智能体小分队要在 128x128 的地图上进行自由对抗。根据主办方的设计,每个智能体小分队要达成觅食、探索、竞争、打怪四项成就。这意味着每个环境里有 128 个智能体同时决策,每支队伍里的 8 个智能体要为了不同的目标进行有效的合作分工。
在这种情况下,每个智能体都要发挥自己的强项,必要时,为了团队能够获得「最后的胜利」,一部分智能体还要学会「主动送人头」。鉴于环境里有多个智能体在同时学习,智能体们不仅需要考虑自己期望得到何种奖励,还要考虑对手可能会采取什么策略。再加上每一局对战都要完成四项任务,层层设置之下,每个智能体面临的「抉择」都有更高的决策复杂度。
让海量智能体「卷」起来
对一场学术性质的比赛来说,除了找到好问题,还要有足够多的好选手。为此,主办方从赛事规则、工具、赛事支持等方面对 Neural MMO 挑战赛进行了全面优化。
在工具层面,「IJCAI 2022-Neural MMO 海量 AI 团队生存挑战赛」升级了提交系统,让第一次成功提交到返回结果的时间从原来的两个多小时减少到十分钟;此外,挑战赛还提供了全新的 StarterKit 和 Baseline 。在 StarterKit 中,参赛者只需要跑一遍代码,就可以完成第一个提交;在 Baseline 中,用户只需要训练两天,就可以完成 Stage 1 0.5 的胜率,运行训练四天,就可以获得 Stage 1 0.8 的胜率。
这些设计帮助参赛者在初始阶段迅速地熟悉规则,并以此节省大量时间。利用省下来的时间,参赛者们可以将思考重点放在定义智能体在 Neural MMO 环境中的决策方式上,比如进行奖励信号的设计等。
在赛制上,这场 Neural MMO 挑战赛采取了 PvE 与 PvP 结合的方式。在 PvE 阶段,每个 Stage 的内置 AI 难度会逐渐增加,参赛者由此感受到「梯度」。Stage 1 的难度是最低的,包含了一些基于简单规则编写的开源脚本。之后,Stage 2 的难度会变得更高,主办方基于经典的 PPO 算法对内置 AI 进行训练,并加入自我博弈(Self-Play)的训练机制。到了 Stage 3,智能体的综合能力进一步升级,选手们面对的已经是高度团结的竞争对手队伍。
在 PvE 阶段获,成就分达到 25 的队伍即可晋级;但在 PvP 阶段,难度上升,对战对象从内置 AI 变为其它参赛选手队伍。
让 8 个智能体组团完成任务,是合作博弈中的一个经典问题。如果说在 PvE 阶段的前两个 Stage,依靠单打独斗还能取得一些成绩,那么随着环境内置 AI 不断变强,再到对手从环境内置 AI 变为真实世界中的参赛团队,出战的智能体小分队也需要随之完成脱胎换骨般的进化,以此去理解怎样达成「团队最优决策」。
基于上述改进,不同水平的参赛者都能在这场赛事中找到适合自己的参赛目标。但同时,要想获得顶尖名次,智能体的综合决策能力要能经受住考验,这就要求选手在智能体的算法设计上具备更深刻的思考。
RL 算法选手,后来者居上
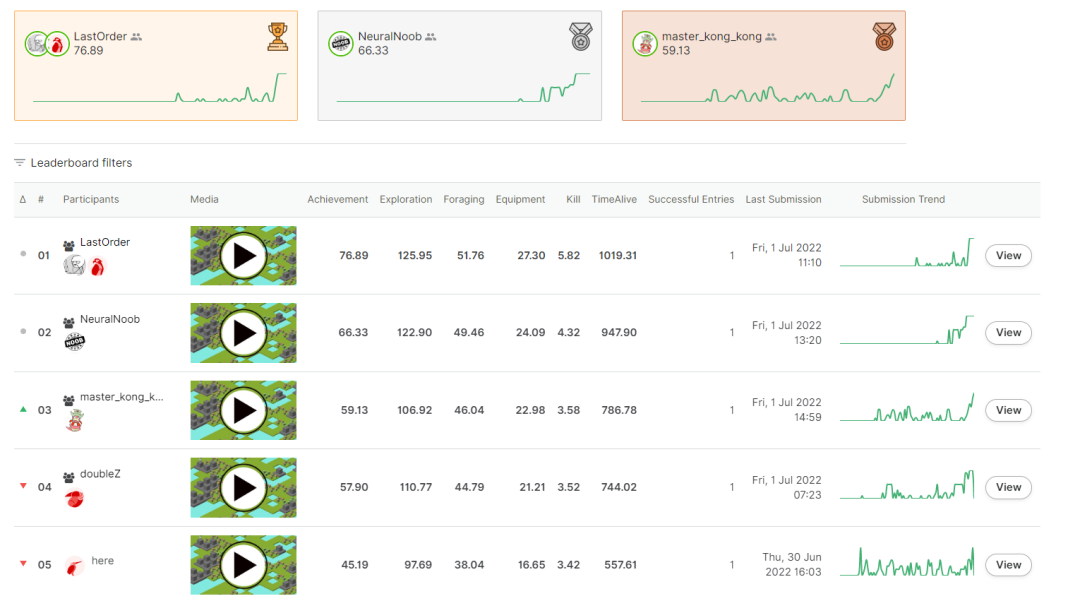
经过三个月的激烈角逐,两支来自业界的队伍脱颖而出,斩获了本届挑战赛的冠亚军。有趣的是,这两支队伍均采用强化学习算法,且都是在最后一个月才参赛。
冠军团队 LastOrder 提到,相较现有的其他多智能体环境,MMO 有更丰富的内容,例如生存、战斗、升级、团队 PK、随机地图等。与其他同类比赛不同的是,Neural MMO 挑战赛给参赛者的规则限制很少,这也为强化学习算法的应用提供了广阔的发挥空间。
NeuralNoob 是亚军获得者,他认为 Neural MMO 最明显的特点在于支持的海量智能体,本场比赛的设置为 128 个,但实际上可以增加到上千或者更多。「它是一个多任务的环境,每个智能体需要在必要的时候改变策略各司其职,具有更大的研究价值。」
在比赛过程中,LastOrder 设计了分布式强化学习训练框架 Newton,该框架具备高度灵活性及可扩展性。
他们采用奖励设计等方法间接鼓励智能体做出合理的行为。在设计合理的奖励、神经网络结构等之后,他们观察到,深度强化学习训练后的智能体自行涌现了相互配合的行为。
「启发式算法的优点是思路更加简明,反馈更加直接。相比之下,强化学习需要更长的训练时间,以进行网络结构和参数的调整。」LastOrder 表示,「但强化学习算法所能达到的能力上限更高,更具探索的价值。」
NeuralNoob 同样采用强化学习算法,整体方案是 ppo 算法加自我博弈 ( self-play) 训练机制,所有智能体的训练都将 8 个智能体作为一个团队来训练,value 部分则会用到整个团队的共享表征,并按照 CTDE 的方式训练。
在 LastOrder 看来,MMO 这个平台还存在更多想象空间:例如它可以引入更多游戏要素,甚至可以变成一个开放的线上游戏,促进 Human in the loop 等领域的相关研究。对此,NeuralNoob 持相似看法,他认为可以有更多样的装备供智能体选择,并设置一个安全区,智能体到达安全区后不能发动攻击,同时可以和敌方智能体进行装备交易。
在 NeuralNoob 的设想里,甚至可以让智能体临时和敌方智能体进行合作,联手击杀一些强大的内置 AI,而同敌方智能体的合作将会让 MMO 更符合真实世界中合作与竞争共存的关系。
NeuralNoob 认为,这些是强化学习目前比较难胜任的地方,强大如 openai five,也是通过手写规则来实现出装路线,因为设计到装备选择的训练样本占比势必会很小,但依赖链却很长。
智能决策的「今天」和「未来」
更长远地看,Neural MMO 环境提供了一个广阔、高自由度的学术框架,可以推动一些种群层面的行为研究,比如如何高效组队,它甚至能衍生出社会学、经济学方面的概念研究,这些都是现阶段相关领域内瓶颈仍存的研究方向。正因此,「IJCAI 2022-Neural MMO 海量 AI 团队生存挑战赛」 在学术研究层面的意义也更加凸显。
任何关于决策智能的学术研究,人们都希望它能在真实的产业场景中发挥价值,包括但不限于商业游戏、量化交易。在现实生活中,决策的代价可能会非常大,这是因为,一方面,决策会直接导致结果,所以决策水平的质量高低,跟结果带来的收益直接相关;另一方面,决策所设定的环境相当复杂,而想要在真实世界中做预演,成本也会非常高。
在学界、业界对智能决策的探索过程中,Neural MMO 无疑有希望成为一个很好的试验载体。但现实中的智能决策往往更加复杂,有着更长的决策链条。如何进一步仿真模拟,让 Neural MMO 更大程度上地接近现实决策环境,这需要整个行业进行长期探索。
据了解,超参数科技将依托 2022 NeurlPS 会议举办新一轮 NMMO 挑战赛。相较于「IJCAI 2022-Neural MMO 海量 AI 团队生存挑战赛」,新赛事增加了交易系统,丰富了装备品类、多职业分工以及毒圈机制,这使得它本就开放的环境变得更加贴合现实决策环境。同时,持续丰富的智能体之间合作及竞争的交互方式也大大增加了决策多样性、策略深度以及合作竞争的可能性。
在Neural NMMO系列挑战赛中,智能体与环境中的内置AI、敌方智能体,以及队友之间产生了大量交互,形成实时反馈,在动态的决策环境中达成最优决策,研究结果推动智能决策技术的发展。不远的将来,智能决策技术将成为数字化转型的加速器,推进能源、物流、工业等产业领域的研究落地和成果转化,为更多「不确定」的真实决策场景提供相对「确定」的答案。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
点赞并收藏
0
暂时没有读者
0
权益说明
本文档仅做收录索引使用,若发现您的权益受到侵害,请立即联系客服(微信: zhuanzhi02,邮箱:bd@zhuanzhi.ai),我们会尽快为您处理
相关内容
智能体
关注
60
智能体,顾名思义,就是具有智能的实体,英文名是Agent。
面向多智能体博弈对抗的对手建模框架
专知会员服务
161+阅读 · 2022年9月28日
德国陆军概念和能力发展中心、空客《从游戏地图到战场——使用 DeepMind 高级 AlphaStar 技术来支持军事决策》
专知会员服务
57+阅读 · 2022年4月10日
【AI+军事】附论文+PPT《用于战术分析、训练和优化的深度自优化人工智能》,瑞士联邦国防采购办科技部、卢加诺人工智能研究所 (IDSIA)
专知会员服务
110+阅读 · 2022年4月7日
【多智能体学习】DeepMind教程,231页PPT
专知会员服务
128+阅读 · 2022年3月25日
牛津大学、谷歌等十余位学者《自动强化学习》撰文综述
专知会员服务
57+阅读 · 2022年2月11日
WAIC开发者日Workshop预告:超参数科技如何探索海量AI决策课题
机器之心
0+阅读 · 2022年8月30日
让AI小队混战跑毒经商,还设“坦克奖”,NeurIPS这比赛真不是打游戏?
量子位
0+阅读 · 2022年8月19日
在游戏世界组建一支AI团队、赢取2万美元,超参数的多智能体「大乱斗」开赛
机器之心
0+阅读 · 2022年4月14日
这款产品发布之后,每款游戏都能有高智商的AI
机器之心
0+阅读 · 2022年1月4日
首届AI球球大作战:Go-Bigger多智能体决策智能挑战赛火热开赛
机器之心
0+阅读 · 2021年12月7日
针对大规模环境下复杂任务的策略搜索强化学习方法研究
国家自然科学基金
41+阅读 · 2015年12月31日
应用数学暑期学校(2015)
国家自然科学基金
5+阅读 · 2015年7月12日
复杂网络上基于演化博弈理论的疾病动力学建模研究
国家自然科学基金
0+阅读 · 2013年12月31日
双齿围沙蚕对硫化物胁迫的生理应对策略
国家自然科学基金
0+阅读 · 2013年12月31日
基于机器学习的围棋人机对弈算法的研究
国家自然科学基金
0+阅读 · 2011年12月31日
Explainable and Safe Reinforcement Learning for Autonomous Air Mobility
Arxiv
0+阅读 · 2022年11月24日
A Survey of Uncertainty in Deep Neural Networks
Arxiv
30+阅读 · 2021年7月7日
MetaCURE: Meta Reinforcement Learning with Empowerment-Driven Exploration
Arxiv
12+阅读 · 2021年2月7日
Efficient Transformers: A Survey
Arxiv
23+阅读 · 2020年9月16日
Embedding Uncertain Knowledge Graphs
Arxiv
12+阅读 · 2019年2月26日
VIP会员
自助开通(推荐)
客服开通
详情
相关主题
智能体
多智能体
AI
博弈
IJCAI 2022
强化学习
相关VIP内容
面向多智能体博弈对抗的对手建模框架
专知会员服务
161+阅读 · 2022年9月28日
德国陆军概念和能力发展中心、空客《从游戏地图到战场——使用 DeepMind 高级 AlphaStar 技术来支持军事决策》
专知会员服务
57+阅读 · 2022年4月10日
【AI+军事】附论文+PPT《用于战术分析、训练和优化的深度自优化人工智能》,瑞士联邦国防采购办科技部、卢加诺人工智能研究所 (IDSIA)
专知会员服务
110+阅读 · 2022年4月7日
【多智能体学习】DeepMind教程,231页PPT
专知会员服务
128+阅读 · 2022年3月25日
牛津大学、谷歌等十余位学者《自动强化学习》撰文综述
专知会员服务
57+阅读 · 2022年2月11日
热门VIP内容
开通专知VIP会员 享更多权益服务
【博士论文】面向真实世界音视联合语音识别的可扩展框架
《通过仿真与开源数据提升战略决策:机遇与局限》最新报告
【AAAI2026】善始则事半功倍:基于前缀优化的大语言模型推理强化学习
评估大语言模型在科学发现中的作用
相关资讯
WAIC开发者日Workshop预告:超参数科技如何探索海量AI决策课题
机器之心
0+阅读 · 2022年8月30日
让AI小队混战跑毒经商,还设“坦克奖”,NeurIPS这比赛真不是打游戏?
量子位
0+阅读 · 2022年8月19日
在游戏世界组建一支AI团队、赢取2万美元,超参数的多智能体「大乱斗」开赛
机器之心
0+阅读 · 2022年4月14日
这款产品发布之后,每款游戏都能有高智商的AI
机器之心
0+阅读 · 2022年1月4日
首届AI球球大作战:Go-Bigger多智能体决策智能挑战赛火热开赛
机器之心
0+阅读 · 2021年12月7日
相关基金
针对大规模环境下复杂任务的策略搜索强化学习方法研究
国家自然科学基金
41+阅读 · 2015年12月31日
应用数学暑期学校(2015)
国家自然科学基金
5+阅读 · 2015年7月12日
复杂网络上基于演化博弈理论的疾病动力学建模研究
国家自然科学基金
0+阅读 · 2013年12月31日
双齿围沙蚕对硫化物胁迫的生理应对策略
国家自然科学基金
0+阅读 · 2013年12月31日
基于机器学习的围棋人机对弈算法的研究
国家自然科学基金
0+阅读 · 2011年12月31日
相关论文
Explainable and Safe Reinforcement Learning for Autonomous Air Mobility
Arxiv
0+阅读 · 2022年11月24日
A Survey of Uncertainty in Deep Neural Networks
Arxiv
30+阅读 · 2021年7月7日
MetaCURE: Meta Reinforcement Learning with Empowerment-Driven Exploration
Arxiv
12+阅读 · 2021年2月7日
Efficient Transformers: A Survey
Arxiv
23+阅读 · 2020年9月16日
Embedding Uncertain Knowledge Graphs
Arxiv
12+阅读 · 2019年2月26日
大家都在搜
Palantir
朱克爱德华兹家族
大型语言模型
多域作战
未来战争
突防
机场
反恐
蓝牙安全攻防
模型压缩 | 知识蒸馏经典解读
Top
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top