发布 BLEURT,用于评估自然语言生成模型

文 / 软件工程师 Thibault Sellam 和研究员 Ankur P. Parikh
Google Research
近几年来,关于自然语言生成 (Natural Language Generation, NLG) 的研究取得了巨大进展。NLG 模型采用日益成熟的方法,以更高的准确率完成翻译文本、文章总结、进行对话以及图片注释等任务。目前,评估这些 NLG 系统的方法有两种:人工评估和自动化指标评估。人工评估会进行大规模的质量调查,让注释人员对每个新版模型打分,但这种方法非常耗费人力。而如果使用目前非常热门的自动化指标评估(如 BLEU),这些指标往往不如人工解释和判断可靠。随着 NLG 的飞速发展,现有的评估方法越来越难以满足需求,因此一些评估 NLG 系统质量和成功率的新方法应运而生。
在“BLEURT:学习稳健的文本生成指标”(BLEURT: Learning Robust Metrics for Text Generation)(已于 ACL 2020 期间公布)一文中,我们提出了一种可以评分的全新自动化指标,该方法不仅可靠,还可达到出色的质量水平,其评估结果更接近人工标注的效果。BLEURT (Bilingual Evaluation Understudy with Representations from Transformers) 基于迁移学习的近期研究成果之上构建,可以捕获句子转述等广泛使用的语言特征。您可以在 Github 上获取该指标的实现代码细节。
Github
https://github.com/google-research/bleurt
评估 NLG 系统
如果采用人工评估,则需向标注人员提供一段生成文本,以便他们基于文本流畅性及意义来评估内容质量。这类文本通常会与人工的文本或从网络中截取的参考文本并排显示。
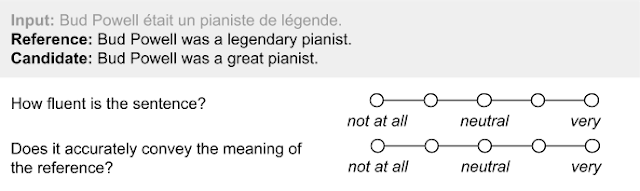
对机器翻译进行人工评估的调查问卷示例
此方法的优势在于其准确性,毕竟在评估一段文本的质量时,人工操作的准确性依旧无可比拟。但是,如果只对几千个样本使用这种评估方法,则很可能需要几十个人花费数天的时间,而这样会导致模型开发工作流中断。
相较于人工质量评估,采用自动化指标的方法成本更低、效率更高。自动化指标通常会将参评语句和参考语句同时输入系统,然后根据词汇重叠情况进行评分,以表明前者与后者的相似程度。其中一个热门指标就是 BLEU,该指标可统计词汇序列同时出现在参评语句和参考语句中的次数(BLEU 得分与精度非常相似)。
自动化指标与人工评估的优势和劣势正好相反。自动化指标方便易用,可在整个训练过程(例如使用 TensorBoard 绘图)中进行实时计算。但是,自动化指标侧重于表面相似性,不能捕获人类语言的多样性,因此这种方法通常不太准确。在人类语言中,常常有许多蕴含实际意义的句子可表达相同的含义。基于重叠情况的评估指标仅依据词汇匹配程度评分,与参考语句表面相似的参评语句即使不能准确表达意义也能得高分,而其他语句则会被罚分。

三个参评语句的 BLEU 得分:参评语句 2 的语义更接近参考语句,但其得分却低于参评语句 3
NLG 的评估方法最好应兼顾人工评估和自动化指标的优势。评估计算既应相对便宜,又应足够灵活,以便应对语言的多元性。
BLEURT 简介
BLEURT 是基于机器学习的全新自动化指标,可以捕获句子之间重要的语义相似性。此模型会根据公开的评分集合(WMT 指标共享任务数据集)以及用户额外提供的评分进行训练。

我们使用 BLEURT 对三个参评语句进行了评分。相较于参评语句 3,虽然参评语句 2 包含的非参考语句词汇更多,但 BLEURT 捕获的结果显示该语句与参考语句的相似性更高
创建基于机器学习的指标时,我们需攻克一个基本挑战,即使这类指标适用于各类任务和领域,并长期保持稳定。然而,训练数据的数量十分有限。事实上,公开数据的确不多。WMT 指标任务数据集是目前最大的人工评分集合,但其中仅包含约 26 万项新闻领域的人工评分。这对于训练适合未来 NLG 系统的评估指标远远不够。
为解决此问题,我们采用了迁移学习方法。首先,我们使用了 BERT 的上下文词表征。BERT 是先进的无监督语言理解表征学习方法,现已成功纳入 NLG 指标(例如 YiSi 或 BERT 得分)。
其次,我们引入了新的预训练方案来提高 BLEURT 的稳健性。实验表明,基于可用的公开人工评分直接训练回归模型并不稳妥,因为我们无法限定应用指标的领域和时间段。如果 领域 发生改变,即用于训练的文本对来自于不同的领域 (domain) 时,准确率可能会降低。如果 质量 发生改变,即在预测的得分高于训练中的得分(此特征通常是好消息,因为这表示 ML 研究正在取得进展)时,准确性也可能会降低。
BLEURT 取得成功的关键在于,我们先使用数百万合成句对来预热模型,再对人工评分进行微调。我们通过随机打乱维基百科中的句子来生成训练数据。我们没有收集人工评分,而是使用文献(包括 BLEU)中的指标和模型集合。这样可以增加训练样本的数量,还能控制成本。

在 BLEURT 的数据生成过程中,随机打乱语序并使用已有的指标和模型进行评分
实验表明,预训练可以显著提高 BLEURT 的准确率,当测试数据为分布外数据时更是如此。
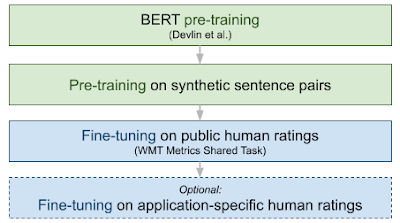
我们对 BLEURT 进行了两次预训练,第一次使用的是语言模型目标(如 原 BERT 论文中所述),第二次使用的是 NLG 评估目标集合。然后,我们根据 WMT 指标数据集和/或用户提供的评分集合对模型精选了微调。下图举例说明了 BLEURT 的端到端训练流程。
结果
我们通过不同的竞争性途径对 BLEURT 进行了基准测试。结果表明,BLEURT 在 WMT 指标共享任务(机器翻译)和 WebNLG 挑战(数据到文本)中与人工评分的相关性最高,显示出了优异的性能。例如,在 2019 年的 WMT 指标共享任务中,BLEURT 比 BLEU 的准确率高出近 48%。我们还证实了预训练可帮助 BLEURT 应对质量改变问题。

在 2019 年的 WMT 指标共享任务中,不同指标与人工评分之间的相关性
结论
随着 NLG 模型越来越完善,评估指标成为了该领域的重大研究瓶颈。基于重叠情况的指标如此受欢迎当然有充分的理由:此类指标简单易用,可保持一致性,并且不需要使用任何训练数据。如果能为参评语句提供多个参考语句,此类指标的准确率会非常高。虽然此类指标在基础架构中发挥着重要作用,但仍不够先进,其无法反映出 NLG 系统的整体性能。我们认为,ML 工程师应该开发更灵活的语义级指标来完善其评估工具包。
BLEURT 并不限于表面重叠范畴,我们试图借助此模型来体现 NLG 的质量。由于采用了 BERT 的表征和新型预训练方案,我们的指标才能基于两种学术基准达到出色性能。我们现在正在研究该模型如何在改善 Google 产品方面发挥作用。未来的研究应以多语性和多模态性研究为目标。
致谢
感谢 Dipanjan Das 为本项目提供的宝贵意见。感谢 Slav Petrov、Eunsol Choi、Nicholas FitzGerald、Jacob Devlin、Madhavan Kidambi、Ming-Wei Chang 及 Google Research 语言团队的所有成员。
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇




