清华、上交等联合发表Nature子刊:「分片线性神经网络」最新综述!
![]()
新智元报道

新智元报道
【新智元导读】一篇论文带你读完「连续分片线性函数」的发展。
连续分片线性函数是一类具备局部线性特性和全局非线性特性的连续函数。具有特定表示模型的连续分片线性函数能够对紧集上的任意连续函数进行全局逼近。
其本质是利用有限数量的线性函数对复杂的非线性系统进行精确建模,即在保持局部线性特性的同时,使整体建模表现出非线性特性。
分片线性神经网络(PieceWise Linear Neural Networks,PWLNN)是利用连续分片线性函数对非线性系统建模的主要方法之一。
当合理配置神经网络网络结构及神经元中的激活函数(如ReLU等分片线性映射函数),可以得到一类PWLNN,并以此为基础,灵活利用常见的神经网络模型参数优化算法和各类成熟的计算平台,实现对复杂非线性系统或数据集进行黑箱建模。
在过去的几十年里,PWLNN已经从浅层架构发展到深层架构,并在不同领域取得了广泛的应用成果,包括电路分析、动态系统识别、数学规划等。近年来,深度PWLNN在大规模数据处理方面取得的巨大成功尤为瞩目。
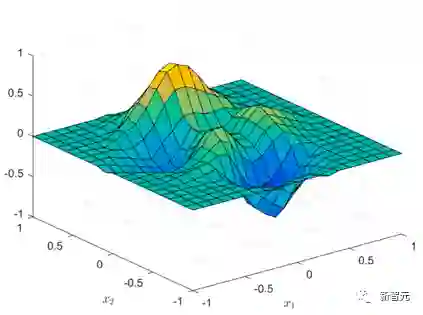
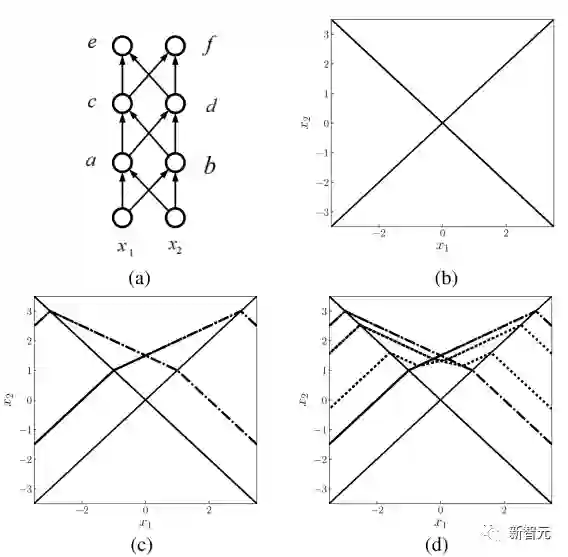
图1 二维连续分片线性函数示例[2]
最近由清华大学自动化系、比利时荷语鲁汶大学电子系、上海交通大学自动化系以及之江实验室的研究人员共同完成的一篇发表在《自然-综述》系列期刊上的综述论文,系统地介绍了分片线性神经网络表示模型(包括浅层及深度网络)、优化算法、理论分析以及应用。

论文链接:https://www.nature.com/articles/s43586-022-00125-7
清华大学自动化系李力教授及王书宁教授指导的博士毕业生陶清华(现任比利时荷语鲁汶大学博士后)、黄晓霖(现任上海交通大学副教授)为论文的通讯作者,其中陶清华博士为论文第一作者,其他共同作者包括王书宁教授、比利时荷语鲁汶大学Johan A.K. Suykens教授及王书宁教授指导的博士毕业生袭向明(现任之江实验室助理研究员)。
清华大学自动化系王书宁教授团队近二十年来在分片线性神经网络方向开展了系统的研究,取得了一些重要成果,显著推进了该领域的发展。
目前,团队成员遍布于国内外的研究机构,继续从事分片线性神经网络及其相关科研工作,共同促进相关理论的发展和成果转化。
Nature Reviews Methods Primers于2021年1月创刊,致力于加强跨学科的协作,出版多领域前沿方法或技术的综述文章,旨在为处于不同职业阶段或具有不同研究背景/不同知识储备的跨学科研究者和实践者提供了解、评估和应用前沿方法和技术的信息交流平台。
基本背景及发展历程
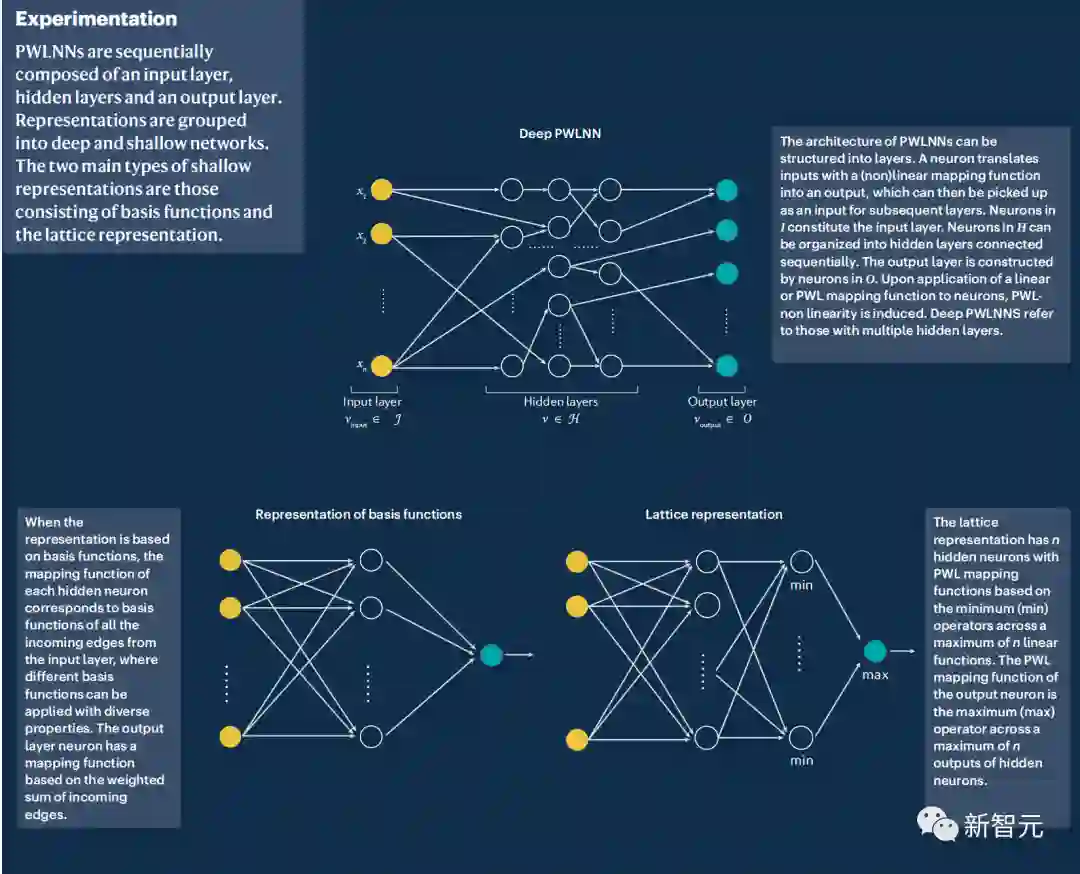 图3. 模型部分概况[1]
图3. 模型部分概况[1]
PWLNN表示模型及其学习方法
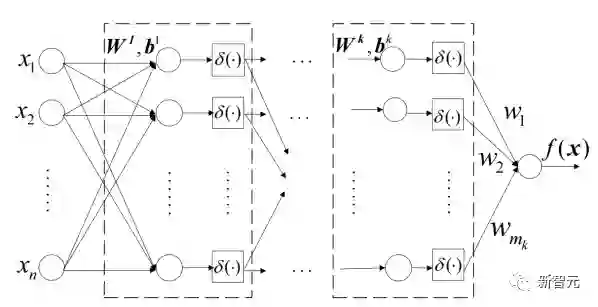

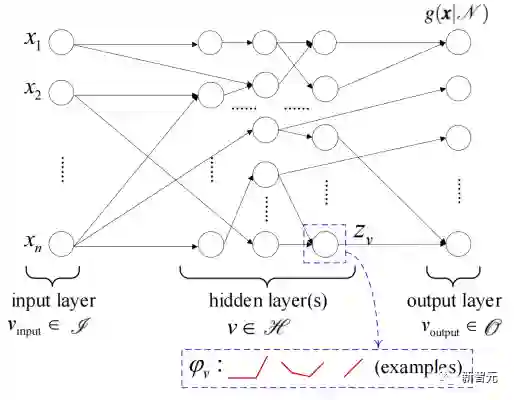
学习算法
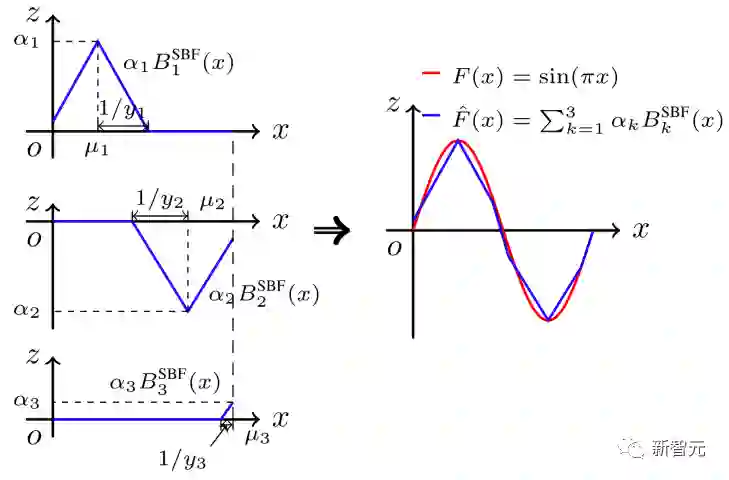
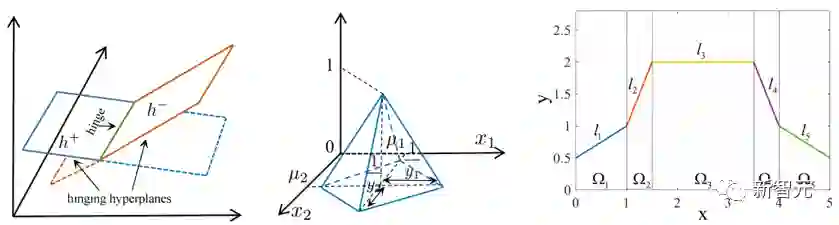
分片线性特性


