维基百科联手谷歌翻译,结果“惨不忍睹”!

作者 | 琥珀
出品 | AI科技大本营
作为前沿科技新闻报道的一线工作者,我们经常会碰到各种陌生难懂、语言不通的词句。
这直接导致我们在引用和查找信息时,往往辅助以维基百科和谷歌翻译为代表的两大信息引擎,其重要性不言而喻。然而,维基百科的内容显然更偏向于英文内容,举个例子来讲,全球有大约 1200 万人使用祖鲁语,但祖鲁语的维基百科文章大约只有 1000 篇。作为维基百科的词条贡献者们而言,能够快捷方便地创建非英语乃至少数语言的词条基本上是相当迫切的需求。“我们的志愿者们正通过翻译英文的维基条目来弥补这个鸿沟。”
近日,据 VentureBeat 等多家外媒报道,为了解决这个问题,维基媒体基金会(Wikimedia Foundation,维基百科的运营方)表示,正与谷歌合作,将谷歌翻译(Google Translate)将免费集成到维基百科的内部翻译工具中,与开源翻译工具 Apertium 一同成为附加的功能。据称,Apertium 迄今为止已经为 40 万篇维基百科文章贡献了翻译。
两款软件都会先进行一遍机器翻译,然后再交由人类编辑进行手工审查和改进。相比起 Apertium,谷歌翻译新增了祖鲁语(Zulu)、豪萨语( Hausa)、库尔德语(Kurdish)和约鲁巴语(Yoruba)等 15 种语言,共计 121 种。
谷歌承诺,它不会存储和向第三方分享任何个人信息。
使用流程
目前维基百科正尝试开放的新功能包括 TemplateWizard、New wikitext mode、Visual differences、Two column edit conflict以及 Content translation。这简直是维基百科编辑工作者的又一大福利!为此,我们专门探寻了 Content translation 这一功能的使用特性:
如视频所示,通过一些科学的手段,我们终于登录上了维基百科的编写界面。
操作流程如下:
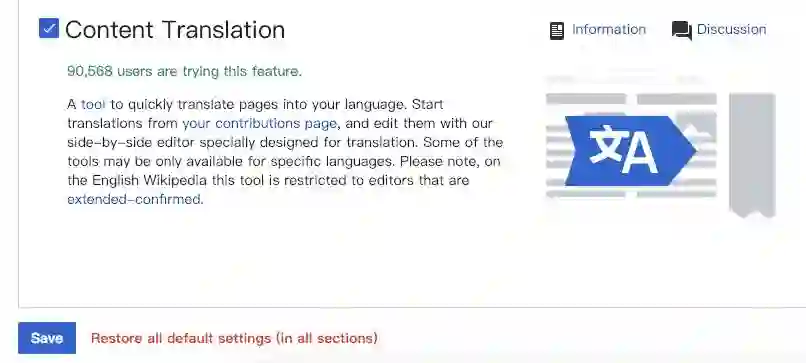
步骤一:点击右上角Beta界面,下拉至 Content Translation,然后点击对勾,并保存。
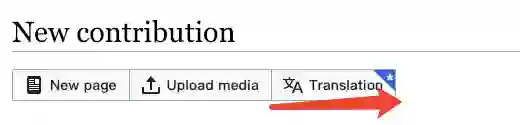
步骤二:点击右上角Contribution,进入编写界面,这时会弹出Translation一栏,点击确认。
步骤三:当我们进入Translation后,会看到页面中主要有四个功能键:
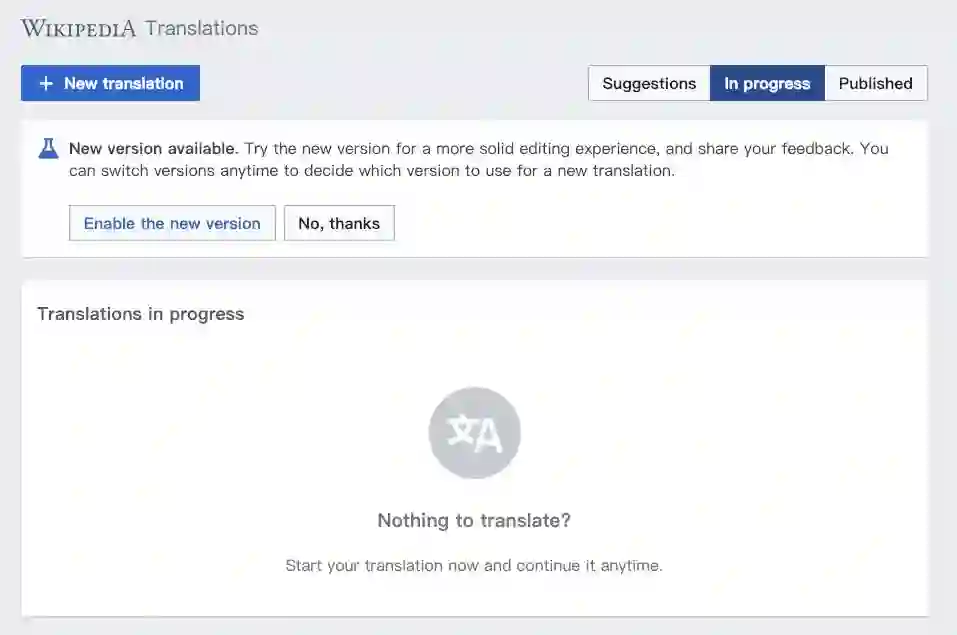
+New translation,可自行创建新的关键词句;
Suggestion,推荐的可以修改或编辑的关键词句;
In Progress,已保存或正在编辑的所有文档;
Published,已发布的文档。
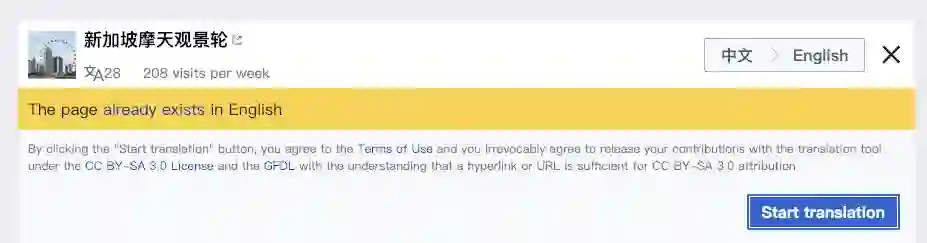
步骤四,输入一组词条后,屏幕界面左侧显示原文、译文,右侧显示翻译辅助的工具,如表格、特殊字符、模板等。
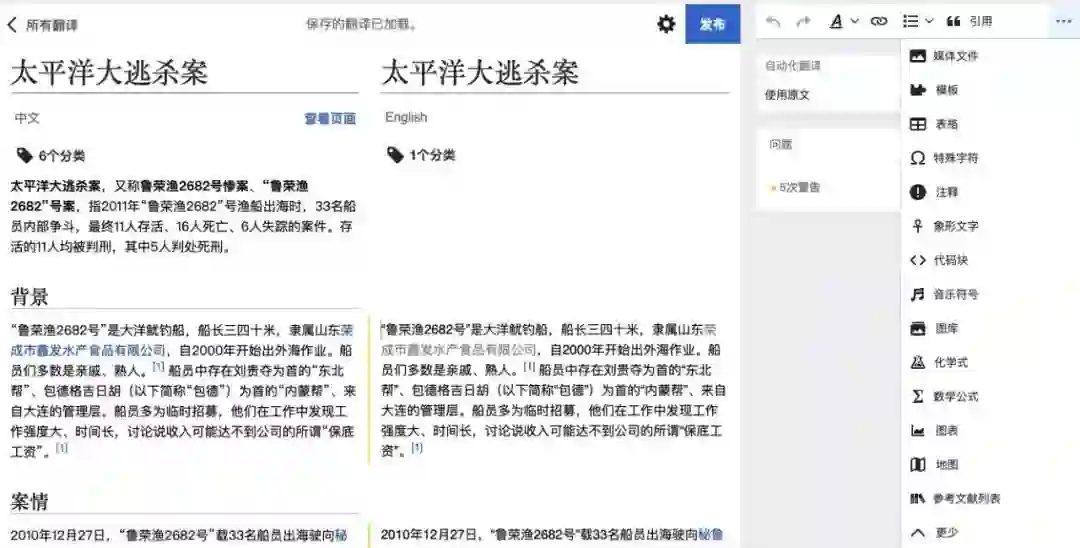
脆弱的机器翻译
不过,可能正是因为目前处于测试版,我们在接下来尝试用谷歌翻译编写/完善维基百科词条时,出现了各式各样不尽如人意的问题。
比方说,当你输入“ Andrew Ng ”的词条后,满眼可见的是机器翻译后的“硬伤”:

“安德鲁严德Ng”、“谷歌脑”……是什么鬼?
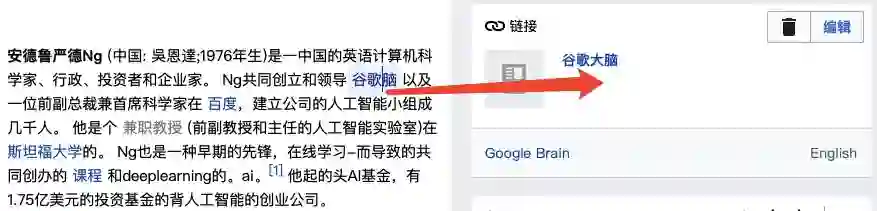
不过,如果鼠标点击附有超链接的专有名词“Google Brain”,右侧提示栏仍会显示正确的翻译。
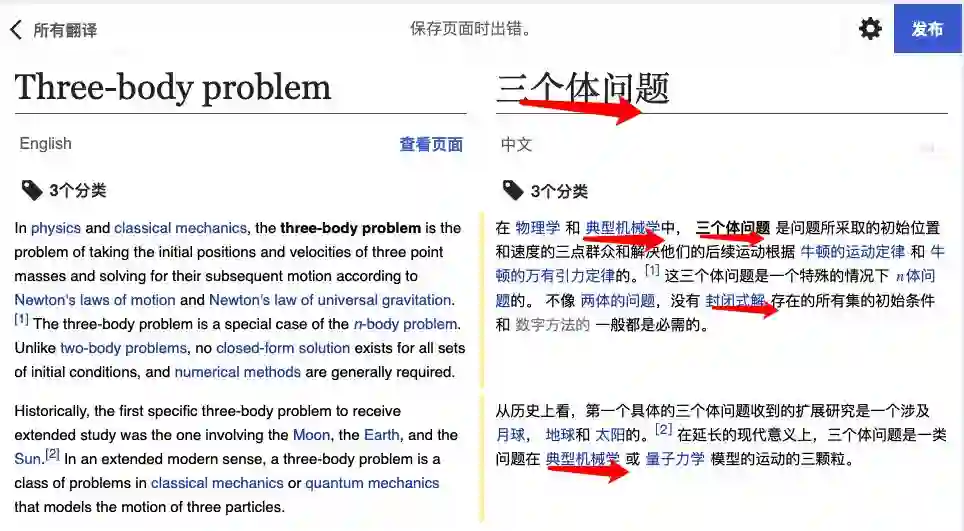
请问什么是“三个体问题”、“延长的现代意义”、“封闭式解”、“典型机械学”?
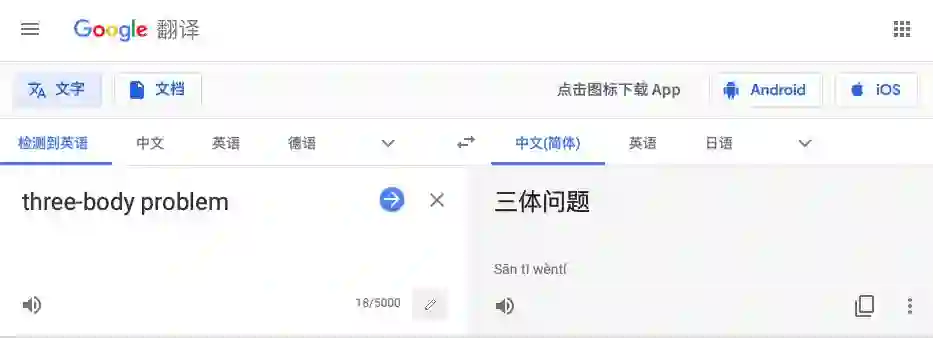
正常情况下的谷歌翻译
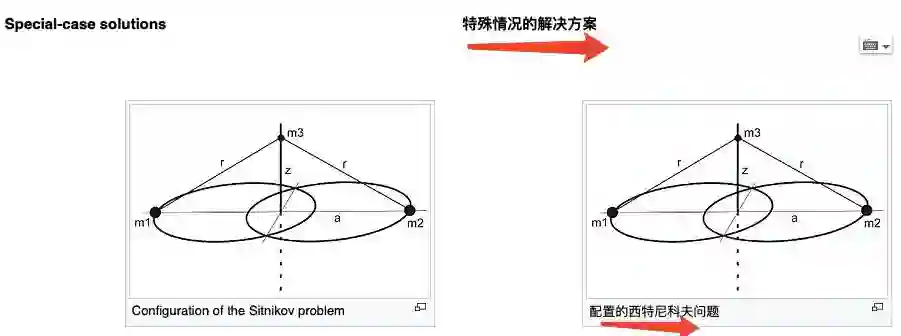
在对包含文字的图片进行翻译时,机器的理解能力更是令人堪忧……
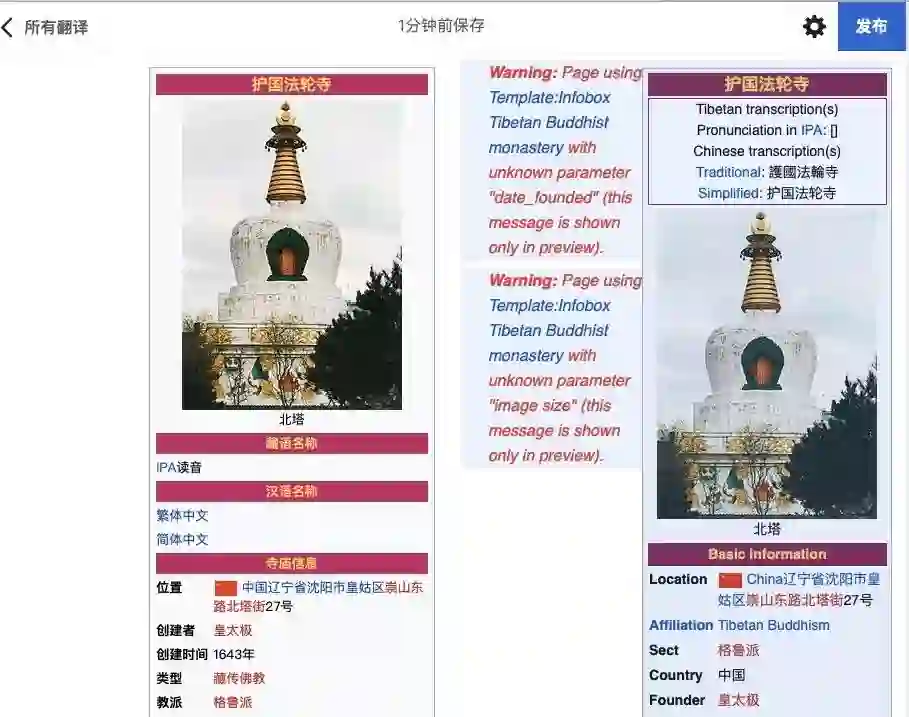
目前我们仅测试出了英翻汉的机器转译能力,而汉翻英的功能一直未能测试成功。如上图右侧显示,汉翻英的界面里仍显示了“汉语”。
值得一提的是,如果长期停留在翻译页面不尝试任何动作的话,你还会遇到404 的提示。不知道这种问题否仅出现在了营长的电脑上。
以及各种各样的操作提示……




反正,直到最后,营长表示:累觉不爱。
谷歌翻译,地表最强机器翻译?
2016 年下半年,“神经机器翻译系统(GNMT,Google Neural Machine Translation system)”的面世,将谷歌翻译带入了神经网络和深度学习等人工智能算法驱动的时代。
简言之,GNMT,即用机器学习的方法来训练机器,不告诉机器需要怎样的语言法则,怎样用词造句,而是扔给它一堆素材,让它自我学习自我提高。据官方解释,输入的每个文字都会有一个关于重要性的权重,每个字都和产出的词汇有一定的关系。系统会自己判断,根据权重等信息,抉择翻译出来的下一个词是什么词。
在此之前,多数翻译软件使用的PBMT(Phrase-Based Machine Translation),即将一句话拆成一个个词组(Phrase),然后针对每个词组去寻找合适的翻译词汇。
据当时的报道称,该系统不再将句子分解为词与短语独立翻译,而是翻译完整的句子,将误差降低了 58%~85% 以上。
后来,包括百度翻译、网易有道、搜狗翻译都相继(声称)推出了基于GNMT 的机器翻译翻译工具。
目前机器翻译需要的不单单是定义语法规则的知识,更需要一点常识。对比当前主流的几款翻译引擎在机器翻译上的进步是值得肯定的,同等语料库下,短语类能在更少工程量的基础上实现相同的效果,但纯粹将输入的句子作为一个序列,不考虑句子本身作为语言的特性,生成的内容依然会难以理解。
而实际上,维基百科也意识到了当前机器翻译仍存在着的极大局限性。因而,在制定翻译步骤时,也明确指出:“把这个英文条目翻译成其他语言。你可以在你自己的文字编辑器中进行翻译工作,但请不要只用机器翻译(如 Google)进行翻译。”
详细内容如下:
请避免翻译不熟悉的内容。一方面您很可能无法准确地表达原文含义(甚至改变原文含义),另一方面您可能会因为不熟悉相关主题而把原文的错误内容带到译文之中。
请勿使用机器翻译翻译条目,无论使用哪种机器翻译软件或网站,条目的质量通常都会差到让人难以理解。我们强烈不建议在机器翻译基础上进行编辑。任何人都可以移除条目中拙劣的机器翻译内容;如果条目通篇由拙劣机器翻译组成,那么将可能被提请快速删除。
建议在翻译时每到一个阶段就至少通读一遍译文,修饰文法,使文章内容通顺而且匹配中文语法。
请避免翻译腔。
那么,你认为机器翻译何时才能不需要这些条条框框?
参考链接:
https://www.mediawiki.org/wiki/Content_translation/Machine_Translation/Google_Translate
https://www.mediawiki.org/wiki/Content_translation
https://wikimediafoundation.org/2019/01/09/you-can-now-use-google-translate-to-translate-articles-on-wikipedia/
(*本文为AI科技大本营原创文章,转载请联系微信1092722531)
公开课预告
◆
全双工语音
◆
本期课程中,微软小冰全球首席架构师及研发总监周力博士将介绍微软小冰在全双工语音对话方面的最新成果,及其在智能硬件上的应用和未来将面临的更多技术产品挑战。

推荐阅读





