谷歌将AutoML应用于Transformer架构,翻译结果飙升,已开源!

新智元报道
新智元报道
来源:googleblog
编辑:张佳
【新智元导读】为了探索AutoML在序列域中的应用是否能够取得的成功,谷歌的研究团队在进行基于进化的神经架构搜索(NAS)之后,使用了翻译作为一般的序列任务的代理,并找到了Evolved Transformer这一新的Transformer架构。Evolved Transformer不仅实现了最先进的翻译结果,与原始的Transformer相比,它还展示了语言建模的改进性能。
自几年前推出以来,Google的Transformer架构已经应用于从制作奇幻小说到编写音乐和声的各种挑战。重要的是,Transformer的高性能已经证明,当应用于序列任务(例如语言建模和翻译)时,前馈神经网络可以与递归神经网络一样有效。虽然用于序列问题的Transformer和其他前馈模型越来越受欢迎,但它们的架构几乎完全是手动设计的,与计算机视觉领域形成鲜明对比。AutoML方法已经找到了最先进的模型,其性能优于手工设计的模型。当然,我们想知道AutoML在序列域中的应用是否同样成功。
在进行基于进化的神经架构搜索(NAS)之后,我们使用翻译作为一般的序列任务的代理,我们找到了Evolved Transformer,这是一种新的Transformer架构,它展示了对各种自然语言处理(NLP)任务的有希望的改进。Evolved Transformer不仅实现了最先进的翻译结果,而且与原始的Transformer相比,它还展示了语言建模的改进性能。我们是将此新模型作为Tensor2Tensor的部分发布,它可用于任何序列问题。
开发技术
要开始进化NAS,我们有必要开发新技术,因为用于评估每个架构的“适应性”的任务——WMT'14英语-德语翻译——计算量很大。这使得搜索比在视觉领域中执行的类似搜索更加昂贵,这可以利用较小的数据集,如CIFAR-10。
这些技术中的第一种是温启动——在初始进化种群中播种Transformer架构而不是随机模型。这有助于在我们熟悉的搜索空间区域中进行搜索,从而使其能够更快地找到更好的模型。
第二种技术是我们开发的一种称为渐进动态障碍(PDH)(Progressive Dynamic Hurdles )的新方法,这种算法增强了进化搜索,以便为最强的候选者分配更多的资源,这与先前的工作相反,其中NAS的每个候选模型被分配相同的评估时的资源量。如果模型明显不好,PDH允许我们提前终止对模型的评估,从而使有前途的架构获得更多资源。
Evolved Transformer简介
使用这些方法,我们在翻译任务上进行了大规模的NAS,并发现了Evolved Transformer(ET)。与大多数序列到序列(seq2seq)神经网络体系结构一样,它有一个编码器,将输入序列编码为嵌入,解码器使用这些嵌入构造输出序列;在翻译的情况下,输入序列是要翻译的句子,输出序列是翻译。
演化变压器最有趣的特征是其编码器和解码器模块底部的卷积层,在两个地方都以类似的分支模式添加(即输入在加到一起之前通过两个单独的卷积层)。
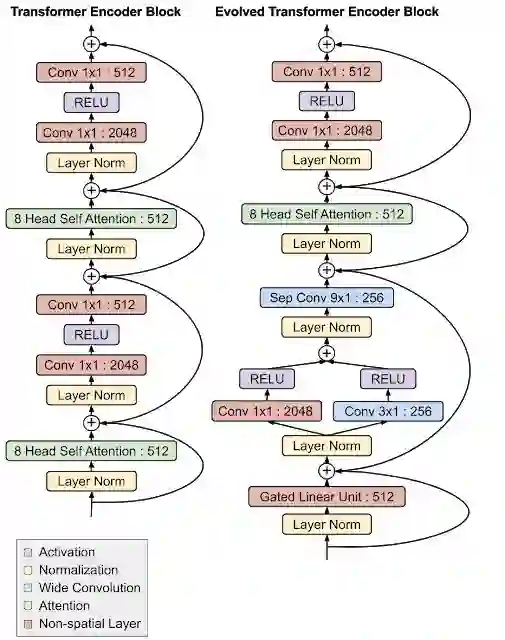
Evolved Transformer与原始Transformer编码器架构的比较。注意模块底部的分支卷积结构,它独立地在编码器和解码器中形成。
这一点特别有趣,因为在NAS期间编码器和解码器架构不共享,因此独立发现该架构对编码器和解码器都很有用,这说明了该设计的优势。虽然最初的Transformer完全依赖于自我关注,但Evolved Transformer是一种混合体,利用了自我关注和广泛卷积的优势。
对Evolved Transformer的评估
为了测试这种新架构的有效性,我们首先将它与我们在搜索期间使用的英语-德语翻译任务的原始Transformer进行了比较。我们发现在所有参数尺寸下,Evolved Transformer具有更好的BLEU和 perplexity performance,拥有最大增益与移动设备兼容(约700万个参数),证明了参数的有效使用。在更大的尺寸上,Evolved Transformer在WMT'14 En-De上达到了最先进的性能,BLEU得分为29.8,SacreBLEU得分为29.2。
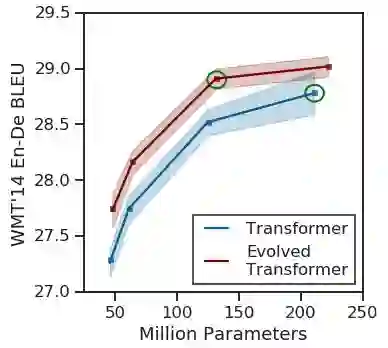
不同尺寸的WMT'14 En-De Evolved Transformer与原Transformer的比较。性能的最大提高发生在较小的尺寸上,而ET在较大的尺寸上也显示出强度,优于最大的Transformer,参数减少37.6%(要比较的模型用绿色圈出)。
为了测试普遍性,我们还在其他NLP任务上将ET与Transformer进行了比较。首先,我们研究了使用不同语言对的翻译,发现ET表现提升,其边缘与英语-德语相似; 再次,由于其有效使用参数,对于中型模型观察到了最大的提升。我们还比较了使用LM1B进行语言建模的两种模型的解码器,并且看到性能提升近2个perplexity。

未来工作
这些结果是探索体系结构搜索在前馈序列模型中应用的第一步。Evolved Transformer 作为Tensor2Tensor的一部分已开源,在那里它可以用于任何序列问题。为了提高可重复性,我们还开源了我们用于搜索的搜索空间,以及实施渐进动态障碍的Colab。我们期待着看到研究团体用新模型做了什么,并希望其他人能够利用这些新的搜索技术!
参考链接:
https://ai.googleblog.com/2019/06/applying-automl-to-transformer.html
论文地址:
https://arxiv.org/abs/1901.11117





