ResNets首次反超有监督学习!DeepMind用自监督实现逆袭,无需标注

极市导读
近日,DeepMind又整了个新活:RELIC第二代!首次用自监督学习实现了对有监督学习的超越。莫非,今后真的不用标注数据了?>>加入极市CV技术交流群,走在计算机视觉的最前沿

机器学习中,伴随着更多高质量的数据标签,有监督学习模型的性能也会提高。然而,获取大量带标注数据的代价十分高昂。
按照AI行业的膨胀速度,如果每个数据点都得标记,「人工智能=有多少人工就有多智能」的刻薄笑话很可能会成为现实。

不过一直以来,表征学习、自监督学习等办法的「下游效能」至今未能超出有监督学习的表现。
2022年1月,DeepMind与牛津大学、图灵研究院针对此难题,联合研发出了RELICv2,证明了在ImageNet中使用相同网络架构进行同等条件下的对比,无标注训练数据集的效果可以超过有监督学习。
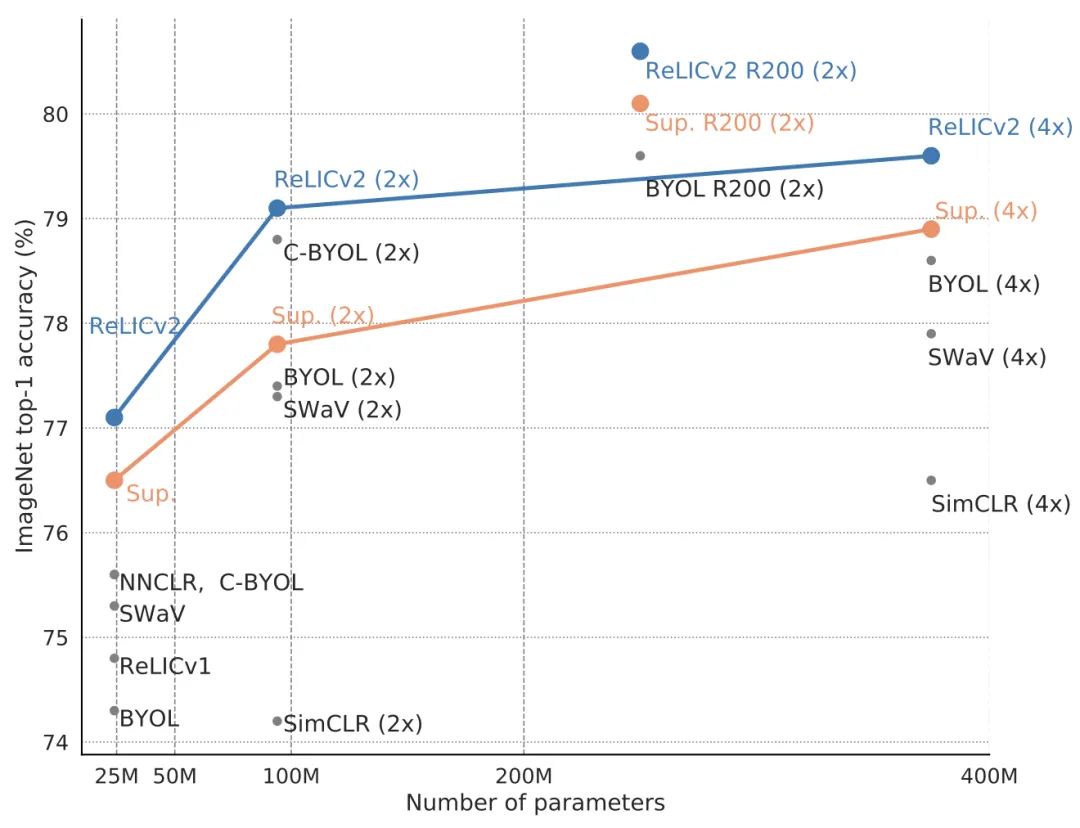
其中,RELICv2使用ResNet50时在ImageNet上实现了77.1%的top-1准确率,而更大的ResNet模型则带来了80.6%的top-1准确率,以较大的优势超越了此前的自监督方法。
为达到上述效果,研究者使用2021年问世的的「以因果预测机制进行表征学习」(缩写RELIC)的架构搭建模型。
相较于RELIC,RELICv2多了一个可以选择相似点和不同点的策略,相似点可以设计不变性的目标函数,不同点可以设计对比性质的目标函数。RELIC学习出的表征会更接近于底层数据的几何性质。这一特性使得这种方式学到的表征能更好地移用在下游任务上。
结果显示,RELICv2不仅优于其他竞争方法,而且是第一个在横跨1x,2x,和4x的ImageNet编码器配置中持续优于监督学习的自监督方法。
此外,在使用ResNet101、ResNet152、ResNet200等大型ResNet架构的情况下,RELICv2也超过了有监督基线模型的表现。
最后,尽管使用的是ResNet的架构,RELICv2也表现出了可以与SOTA的Transformer模型相提并论的性能。
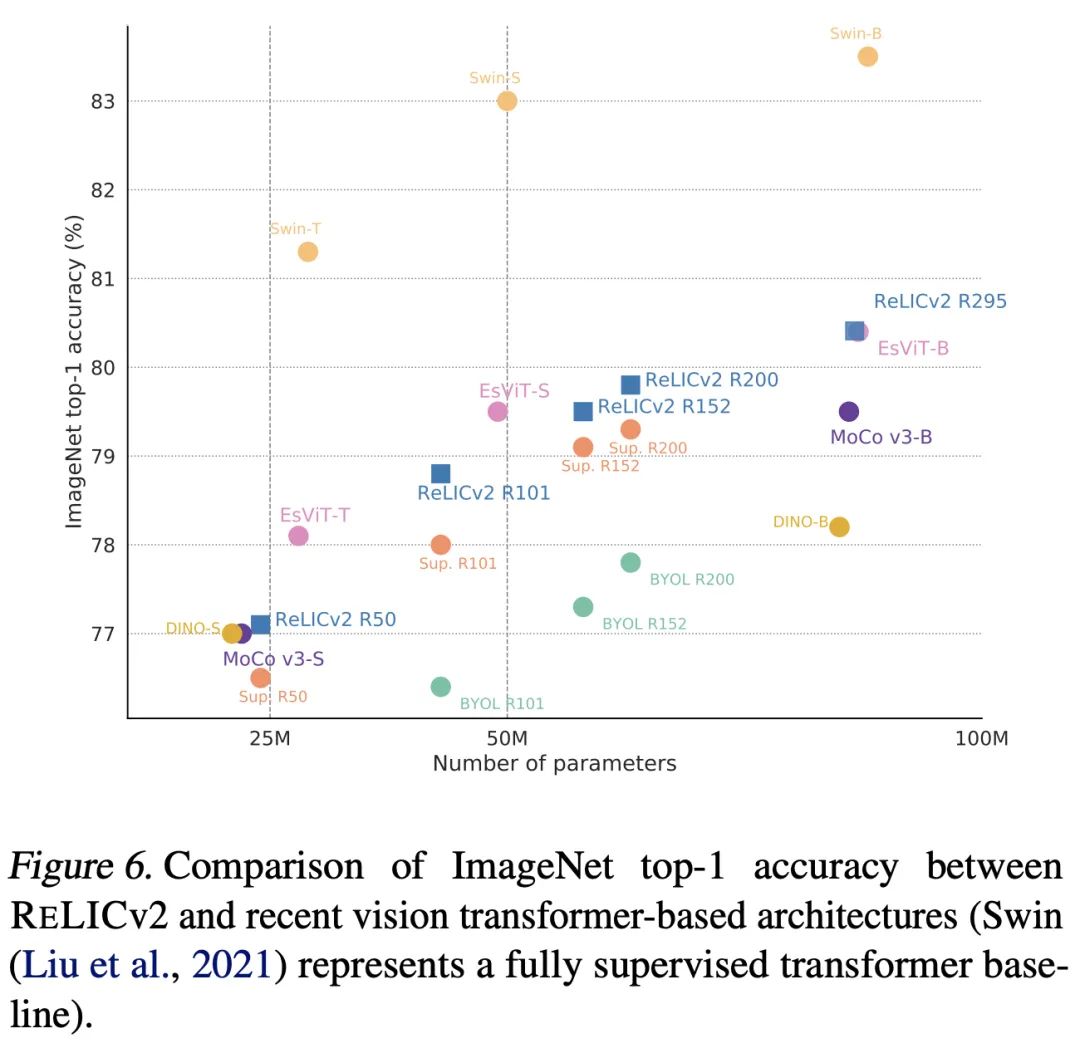
RELICv2和视觉Transformer模型之间的ImageNet top-1准确率比较,Swin代表全监督的Transformer基线
值得注意的是,虽然另有其它研究的结果也超过了这一基线,但它们使用了不同的神经网络架构,所以并非同等条件下的对比。
方法
此前,RELIC引入了一个不变性损失,定义为锚点xi和它的一个正样本x+i之间的Kullback-Leibler分歧:
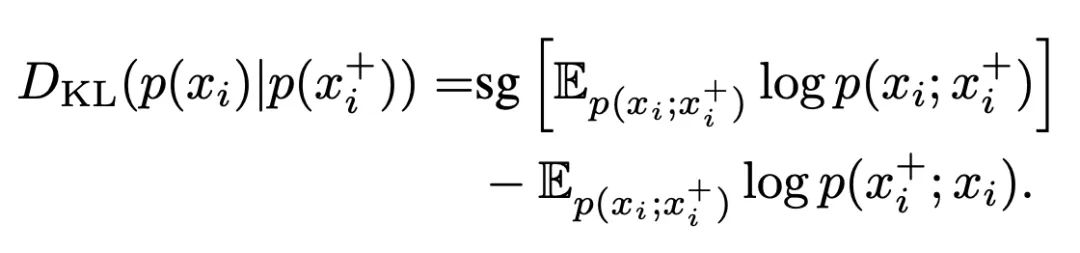
其中,梯度停止算子sg[-]不会影响KL-分歧的计算。
与RELIC类似,RELICv2的目标是最小化对比负对数似然和不变损失的组合。
对于给定的mini-batch,损失函数为:
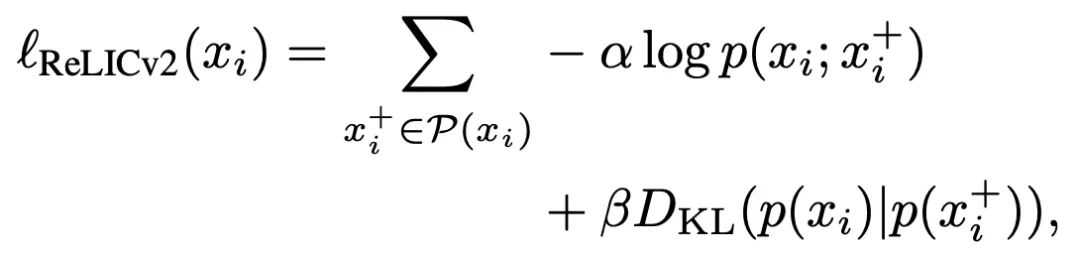
其中,α和β是标量的超参,用于权衡对比和不变损失对整体目标的相对重要性。
RELICv2与RELIC的不同之处在于如何选择适当的正负样本和目标函数两部分之间的组合关系。
增强方法方面,除了标准的SimCLR,作者还应用了两种策略:不同大小的随机裁剪和显著性背景移除。
负样本的采样方面,作者从所有的负样本里随机采样,从而缓解假阴性的问题,也就是从同一个类别里采样到负样本对的问题。
for x in batch: # load a batch of B samples
# Apply saliency mask and remove background
x_m = remove_background(x)
for i in range(num_large_crops):
# Select either original or background-removed
# Image with probability p_m
x = Bernoulli(p_m) ? x_m : x
# Do large random crop and augment
xl_i = aug(crop_l(x))
ol_i = f_o(xl_i)
tl_i = g_t(xl_i)
for i in range(num_small_crops):
# Do small random crop and augment
xs_i = aug(crop_s(x))
# Small crops only go through the online network
os_i = f_o(xs_i)
loss = 0
# Compute loss between all pairs of large crops
for i in range(num_large_crops):
for j in range(num_large_crops):
loss += loss_relicv2(ol_i, tl_j, n_e)
# Compute loss between small crops and large crops
for i in range(num_small_crops):
for j in range(num_large_crops):
loss += loss_relicv2(os_i, tl_j, n_e)
scale = (num_large_crops + num_small_crops) * num_large_crops
loss /= scale
# Compute grads, update online and target networks
loss.backward()
update(f_o)
g_t = gamma * g_t + (1 - gamma) * f_o
上👆🏻:RELICv2的伪代码
其中,f_o是在线网络;g_t是目标网络络;gamma是目标EMA系数;n_e是负样本的数量;p_m是掩码应用概率。
结果
ImageNet上的线性回归
RELICv2的top-1和top-5准确率都大大超过了之前所有SOTA的自监督方法。
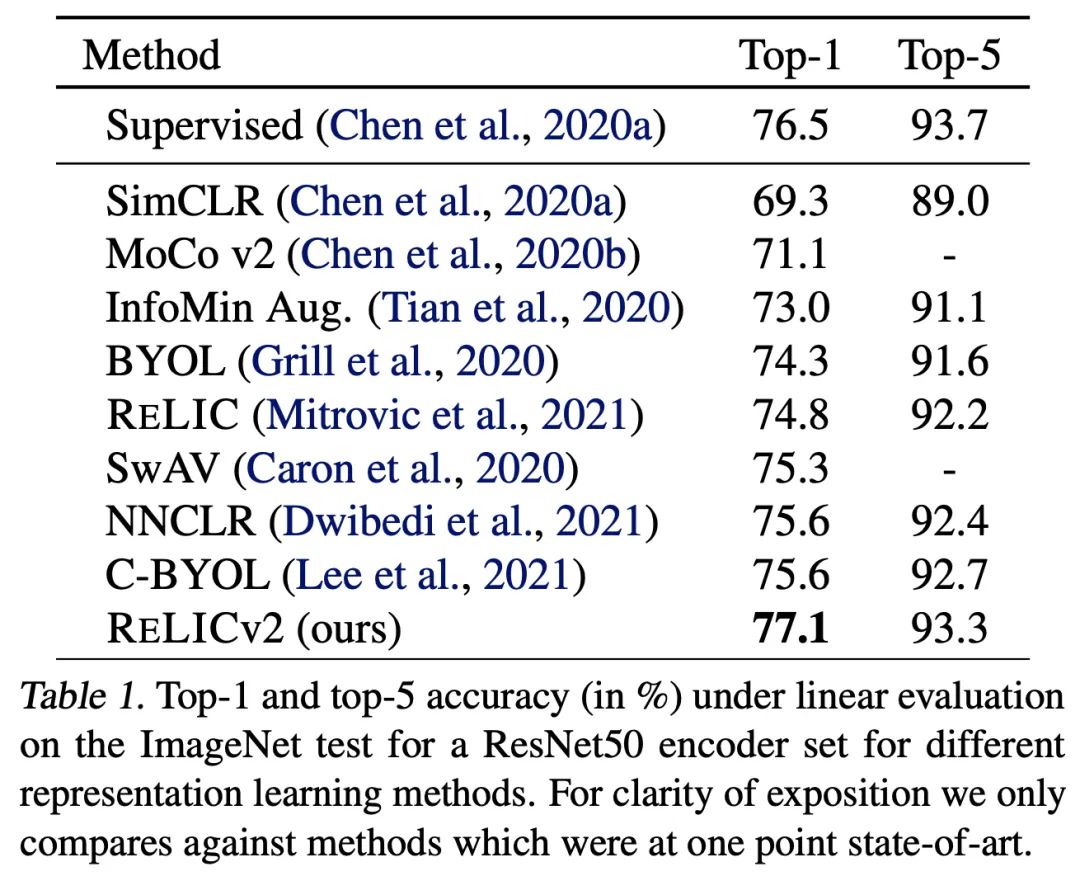
对于其他的ResNet架构,RELICv2在所有情况下都优于监督学习,绝对值高达1.2%。
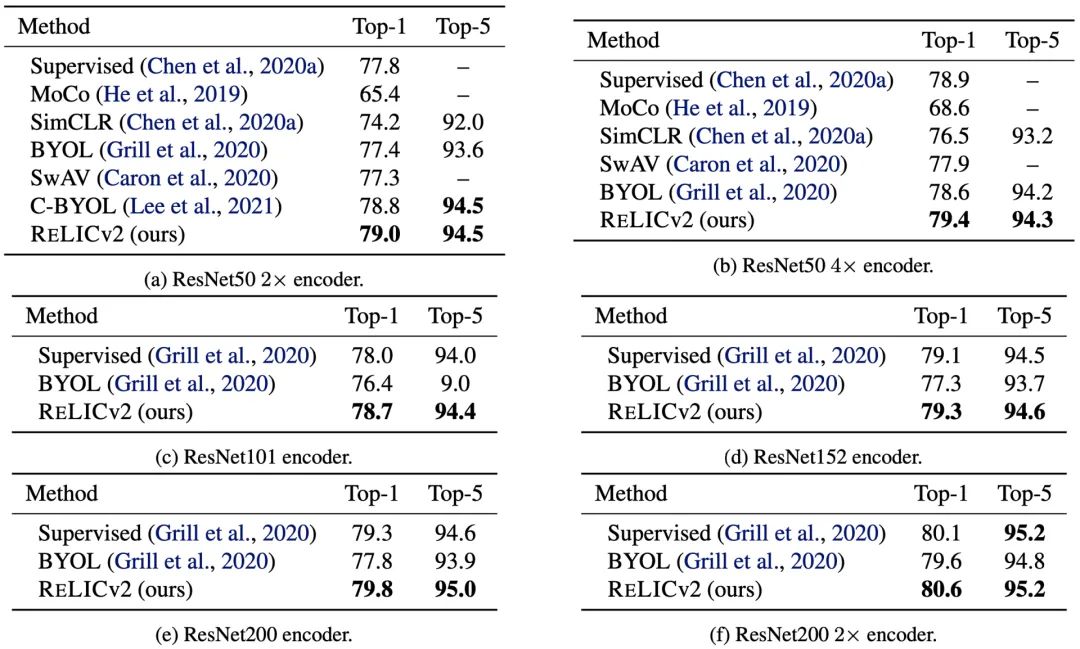
ImageNet上的半监督训练
作者对表征进行预训练,并利用ImageNet训练集中的一小部分可用标签,对所学的表征进行重新修正。
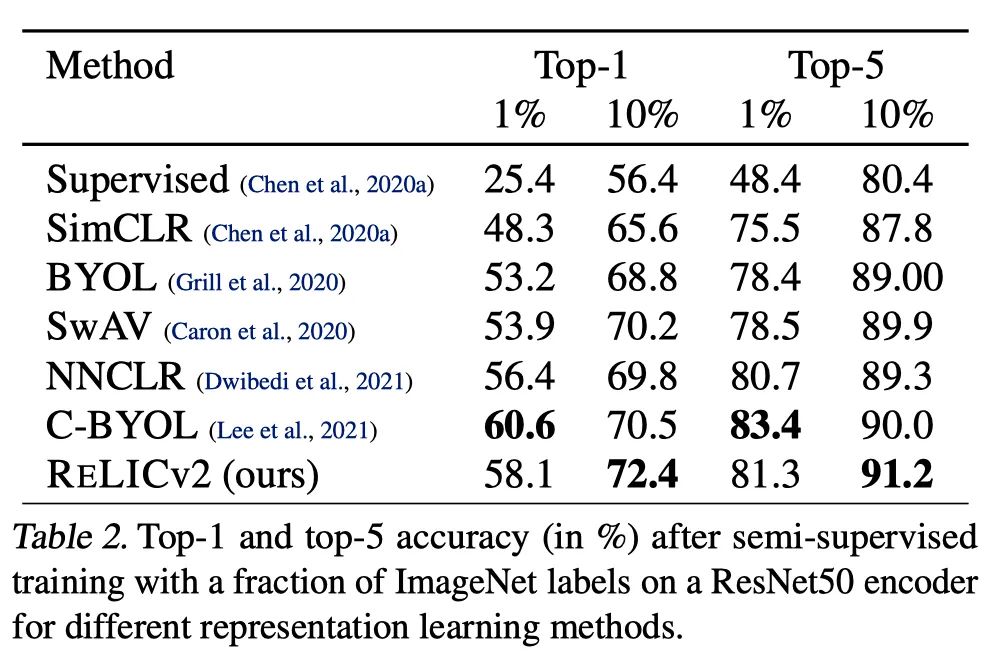
当使用10%的数据进行微调时,RELICv2的表现好于监督学习和此前所有SOTA的自监督方法。
当使用1%的数据时,只有C-BYOL的表现好于RELICv2。
任务迁移
作者通过测试RELICv2表征的通用性,从而评估所学到的特征是否可以用在其他的图像任务。
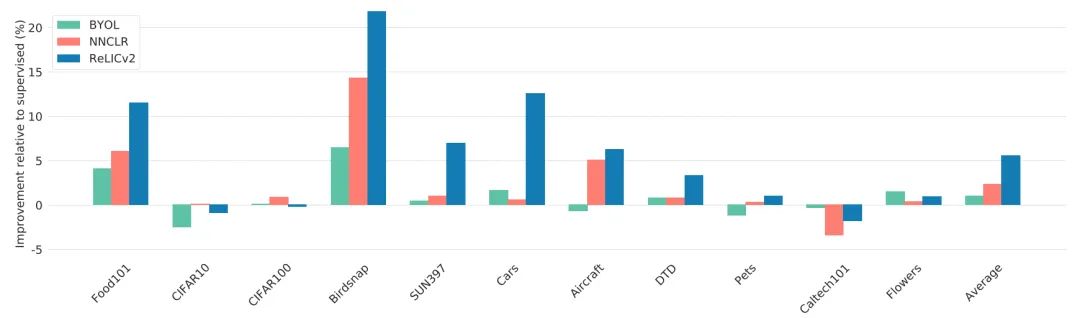
总的来说,RELICv2在11项任务中的7项都比监督学习和竞争方法都要好。
在所有任务中,RELICv2比监督学习平均提高了5%以上,是NNCLR的两倍。
其他视觉任务。为了进一步评估所学表征的通用性,作者通过finetuning评估RELICv2在其他具有挑战性的视觉任务中的表现。

可以看出,在PASCAL和Cityscapes上,RELICv2都比BYOL有明显的优势。而对于专门为检测而训练的DetCon,RELICv2也在PASCAL上更胜一筹。
在JFT-300M上的大规模迁移
作者使用JFT-300M数据集预训练表征来测试RELICv2在更大的数据集上的扩展性,该数据集由来自超过18k类的3亿张图片组成。
其中,Divide and Contrast(DnC)是一种专门为处理大型和未经整理的数据集而设计的方法,代表了当前自监督的JFT-300M预训练的技术水平。
当在JFT上训练1000个epoch时,RELICv2比DnC提高了2%以上,并且在需要较少的训练epoch时,取得了比其他竞争方法更好的整体性能。
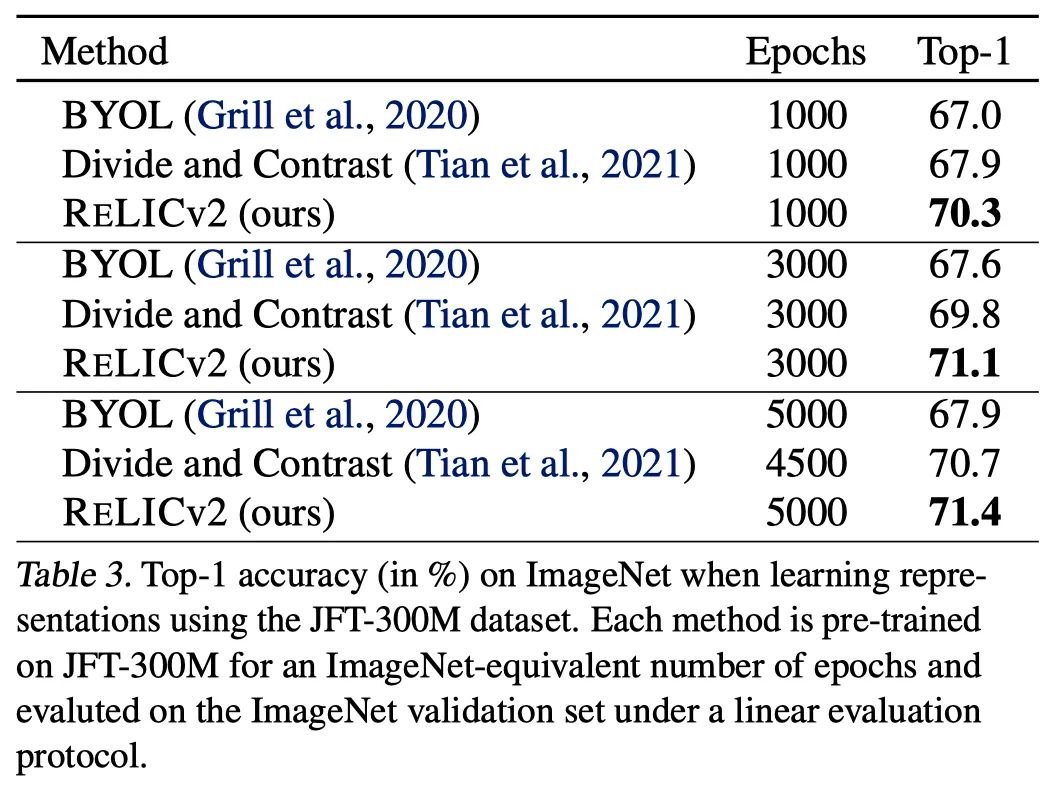
图注:使用JFT-300M数据集学习表征时在ImageNet上的top-1准确率
分析
通过计算所学表征之间的距离,可以了解到损失函数中的显式不变量对RELICv2所学到的表征的影响。
作者为此挑选了两种狗(维兹拉犬与雪达犬)和两种猫(暹罗猫和埃及猫)。在这四个类别中的每一个都有50个来自ImageNet验证集的点。
图中,每一行代表一幅图像,每一个彩色的点代表该图像的五个最近的邻居之一,颜色表示该图像与最近的邻居之间的距离。与基础类结构完全一致的表征会表现出完美的块状对角线结构;也就是说,它们的最近邻居都属于同一个基础类。
可以看到,RELICv2学习到的表征之间更加接近,并且在类和超类之间表现出比BYOL更少的混淆。
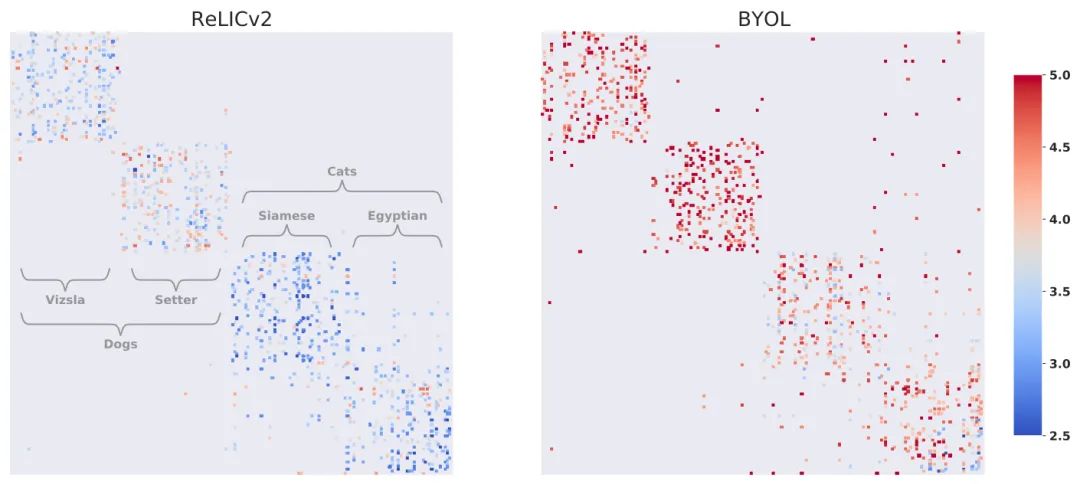
为了量化所学潜在空间的整体结构,作者比较了所有的类内和类间距离。
其中,l2-距离的比值越大,也就是说表征更好地集中在相应的类内,因此也更容易在类与类之间进行线性分离。
结果显示,与监督学习相比,RELICv2的分布向右偏移(即具有较高的比率),这表明使用线性分类器可以更好地分离表征。
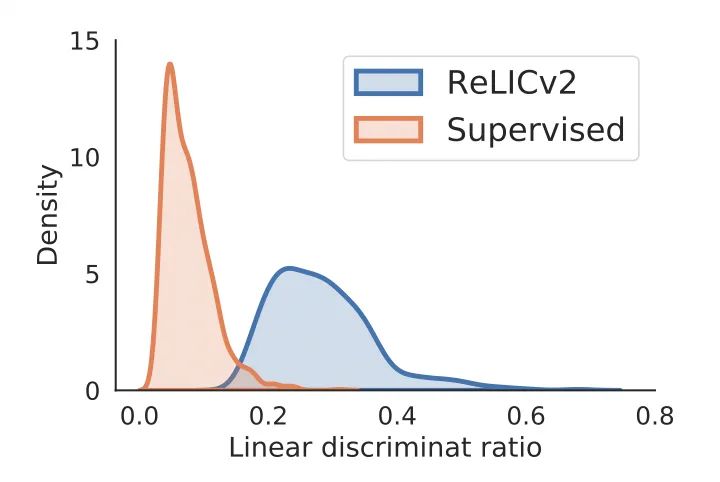
线性判别率的分布:在ImageNet验证集上计算的嵌入的类间距离和类内距离的比率
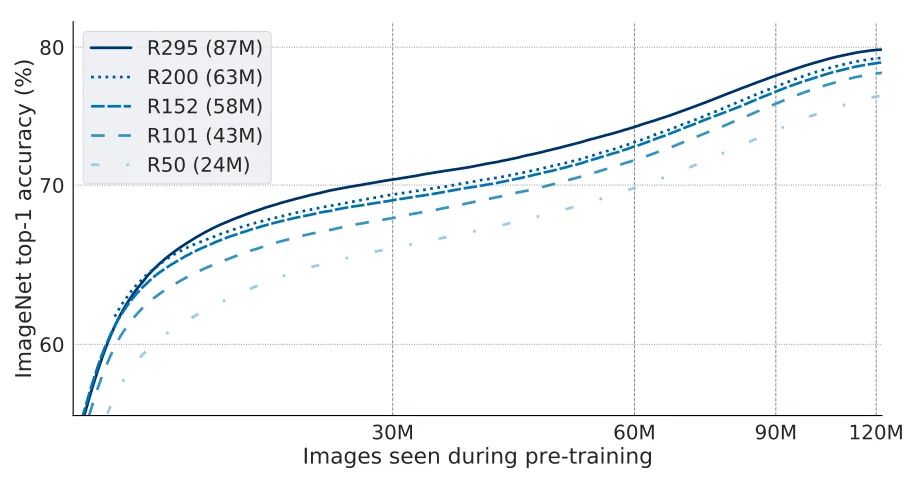
此外,作者也验证了其他工作的发现——模型越大就越具有样本效率。也就是说,在相同精度下,大模型需要的样本更少。
可以看到,为了达到70%的准确性,ResNet50模型需要的迭代次数大约是ResNet295模型的两倍。相比起来,ResNet295的参数数量大约是ResNet50的3.6倍(分别为87M和24M)。
结论
RELICv2首次证明了在没有标签的情况下学习到的表征可以持续超越ImageNet上强大的有监督学习基线。
在使用ResNet50编码器进行的同类比较中,RELICv2代表了对当前技术水平的重大改进。
值得注意的是,RELICv2优于DINO和MoCo v3,并在参数数量相当的情况下表现出与EsViT类似的性能,尽管这些方法用了更强大的架构和更多的训练。
参考资料:https://arxiv.org/abs/2201.05119
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




