DNN/LSTM/Text-CNN情感分类实战与分析
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要21分钟
跟随小博主,每天进步一丢丢


来自 | 知乎
地址 | https://zhuanlan.zhihu.com/p/37978321
作者 | 天雨粟
编辑 | 机器学习算法与自然语言处理公众号
本文仅作学术分享,若侵权,请联系后台删文处理
前言
最近把2014年Yoon Kim的《Convolutional Neural Networks for Sentence Classification》看了下,不得不说虽然Text-CNN思路比较简单,但确实能够在Sentence Classification上取得很好的效果。另外,之前
@霍华德
大神提了这个问题:
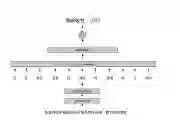
我当时根据自己的理解说了点想法,大神在问题里面也阐明了DNN、CNN和RNN这几种模型的实验效果。所以一直就想自己试试到底这几个模型的实际表现如何,因此机缘巧合之下,就有了这篇文章。
本篇文章将使用Cornell公开的一个数据集(这个数据集也是Yoon Kim在论文实验中所使用的数据集之一),数据链接如下:
数据在我的GitHub中也有,所以pull了代码的话就可以不用单独下载数据了~
这个数据集是用来做情感分类,包含了5331条positive的文本和5331条negative的文本。下面所有的代码都将基于这个数据来构建sentence classification model。
代码运行的TensorFlow版本:1.6.0
正文
文章共分为6个部分:
数据处理
DNN模型
LSTM模型
Text-CNN模型
Text-CNN模型(进阶版)
模型结果对比与分析
建议将代码pull下来辅助学习~
一. 数据处理
我们所使用的数据已经做过一定的预处理,我们可以打开txt文档来查看一下内容:

其中每一行是一个完整的句子,句子之间用空格分隔。
我们数据处理阶段就是要将这些文本转换为机器可以识别的token。
1. 加载数据
首先,我们将数据加载进来:

对文本进行描述性统计:

可以看到我们的正负评论文本各有5331条,平均长度在20左右。
2. 构造词典
接下来我们要基于这些语料来构建我们的词典,构造词典的步骤一般就是对文本进行分词再进行去重。当我们对文本的单词进行统计后,会发现有很多出现频次仅为1次的单词,这类单词会增加我们的词典容量,并且还会给文本处理带来一定的噪声。
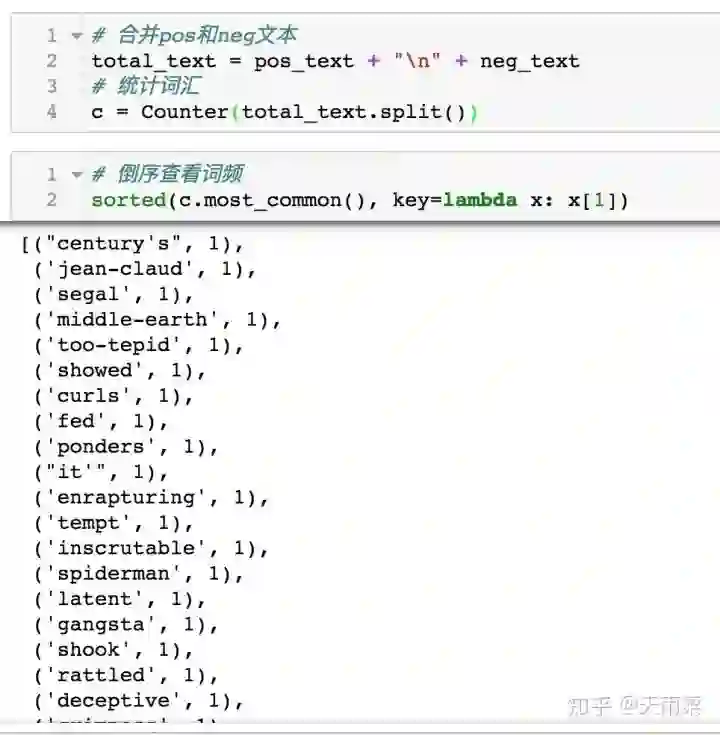
可以发现有很多出现频次进仅为1的单词,去除这些词以后一方面将会极大减小我们的词典容量,加速模型训练,另一方面也会减缓一定的噪声。
实际中一般在分词之后会对单词进行词干化(Stem)处理,之后再进行词频统计,我这里做的比较粗糙~
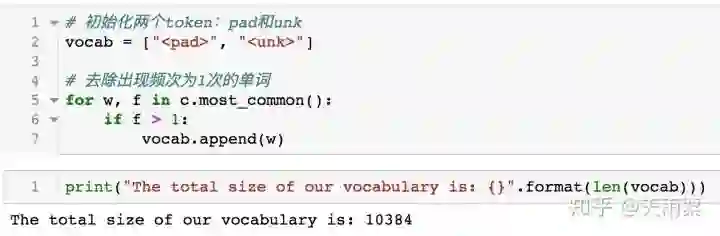
因此我们在构造词典过程中仅保留在语料中出现频次大于1的单词。其中<pad>和<unk>是两个初始化的token,<pad>用来做句子填补,<unk>用来替代语料中未出现过的单词。最后我们得到一个包含10384个单词的词典。
3. 构造映射
有了词典以后我们就需要构造word到token的映射和token到word的映射:

4. 转换文本
有了映射表的基础上,我们就可以对原始文本进行转换,即将文本转换为机器可识别的编码。除此之外,为了保证句子有相同的长度,需要对句子长度进行处理。我们在描述性统计阶段可以发现,语料中句子的平均长度为20个单词,因此我们在这里就设置20作为句子的标准长度:
对于超过20个单词的句子进行截断;
对于不足20个单词的句子进行PAD补全。
下面我们构造一个函数,它可以接收一个完整的str类型的句子,并根据映射表将其转化为tokens。
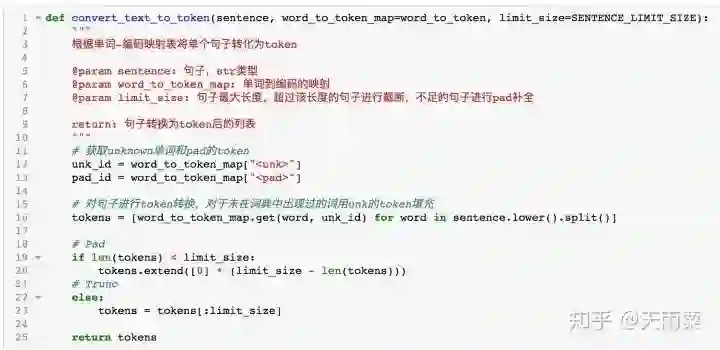
这个函数中,我们首先要获取unk的编码和pad的编码,以备后面句子转换使用。接下来对句子进行映射,如果出现没有见过的单词,则用unk的token替代。最后再对句子的长度进行标准化。
接下来我们分别对pos文本和neg文本进行转换:
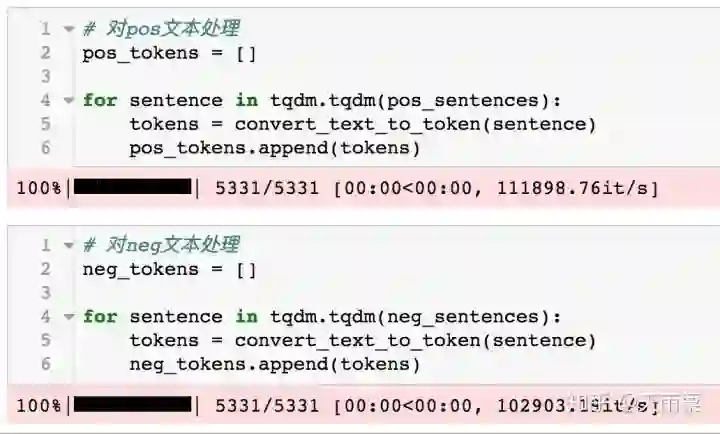
4. 加载pre-trained词向量
本文中将使用Glove中预训练好300维的词向量作为模型的word embeddings。
由于这个文件太大,我没有提交到Github,请各位童鞋到Glove官网自行下载数据集:Global Vectors for Word Representation
或者直接点击这里Glove.6B链接下载。
下载完成后,将压缩包解压,把glove.6B.300d.txt放入data目录下即可。
我们将加载这个词向量:
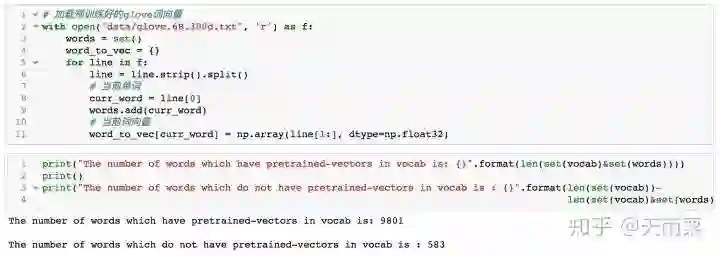
可以发现,我们通过语料构造的词典中,有9801个单词有pre-trained的词向量,而583个单词没有对应的pre-trained词向量,Yoon Kim在论文中提到对于这些没有词向量的单词,直接用random value替代。
因此,我们将基于pre-trained word embeddings构造一个vocab_size * embedding_size大小的矩阵。
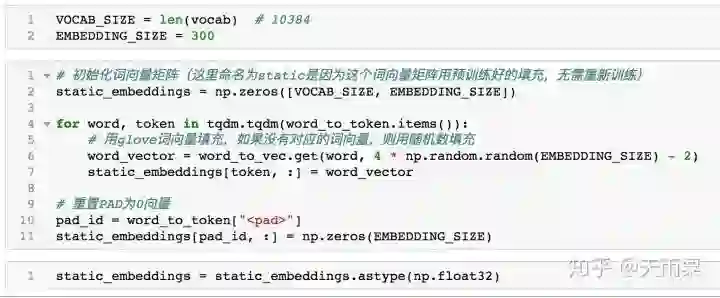
上述代码执行后将得到一个static_embeddings矩阵,这个矩阵每一行是词典中的一个单词所对应的词向量(300维)。
至此,我们就基本完成了数据预处理部分,在这一部分,我们主要完成了两个主要任务:
将原始文本转换为了tokens
构建了我们的word embeddings
二. DNN模型
1. 模型结构
DNN模型对句子的处理方式很简单,对于句子中的每个词,先得到词向量,再将这些词向量进行相加,最终得到句子的向量。将这个向量再连接一个全连接层最后在输出结点输出结果。如下图所示:
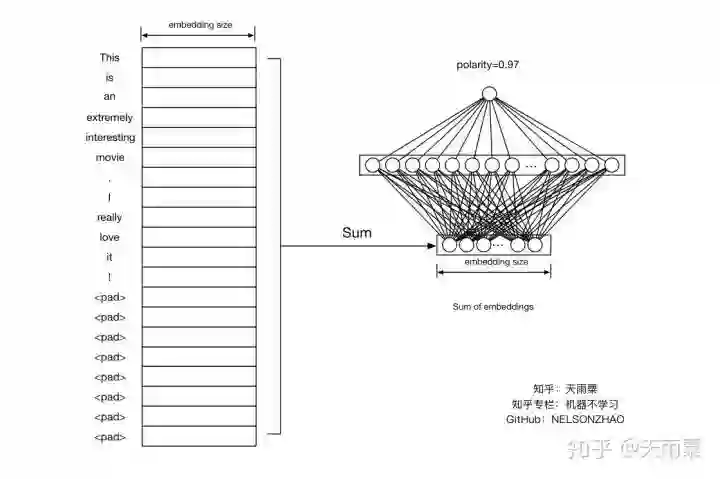
我们的输入是一个句子,即“This is an extremely interesting movie, I really love it!",并用<pad>将句子长度补全为20,对于其中每个词进行word embedding,得到一个20 * embedding_size的矩阵,将这个矩阵的所有行进行相加,便得到sentence embedding,即是一个长度为embedding_size的向量。
随后将这个sentence embedding连接一个全连接层,最后再由单个结点输出概率值。
2. 模型代码
基于上述模型结构,我们可以定义如下代码:
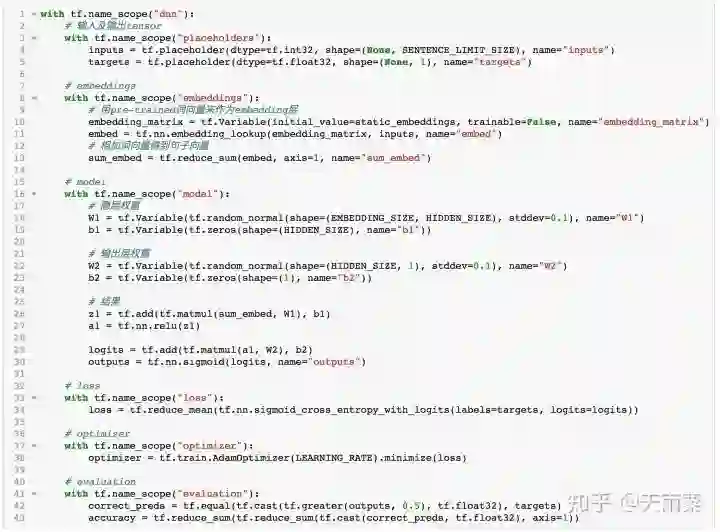
在这个代码中,我分了几个scope,每个scope包含了一组op。后续几个模型也会采取类似的代码方式。
placeholders中定义了inputs和targets两个tensor,其中inputs是我们的输入,shape为[batch_size,sentence_len],这里我们的sentence_len是20。targets的话是1或者0,shape为[batchz_size, 1]
在embeddings中,我们定义了我们的embedding矩阵,用pre-trained值填充,由于这些词向量是训练好的,于是我们显式指定trainable=False。经过lookup得到我们输入序列的每个词向量,再将这些向量相加得到sum_embed
在model中,我们定义了全连接层和输出层的权重并计算结果,全连接层采用了relu作为激活函数
在loss中定义了sigmoid交叉熵损失函数
evaluation中定义了计算accuracy的op,由于我们pos和neg样本是1:1,因此预测概率超过0.5,我们认为是pos,否则是neg。
3. 训练模型
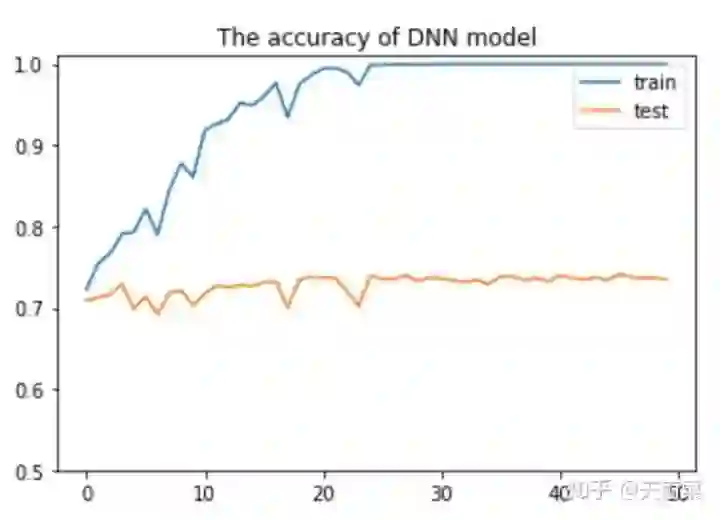
模型构建好之后,我们设置了超参数并对模型进行训练。在这个模型中,我用了80%的数据作为train,剩下20%作为test,一共训练了50个epoch,将模型在train和test上的准确率绘制如下:
用训练好的模型对test数据进行预测,得到准确率如下:
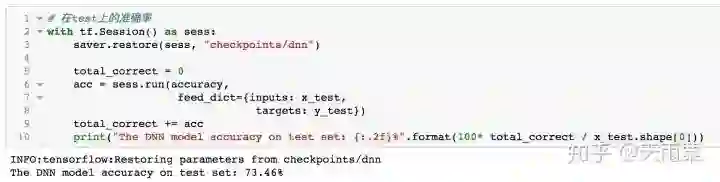
可以看到,dnn模型在train上出现了一定的过拟合,随着训练的进行,当到达25轮左右时,模型在train上的准确率达到了100%,在test上的准确率也相对稳定,最终在test上的准确率为73.46%。
可见DNN模型的效果还可以,当然这个效果主要来自于word embeddings。模型中出现的过拟合可以用dropout或者加入l2正则进行缓解,各位同学可以自己尝试下~
三. LSTM模型
1. 模型结构
RNN模型可以处理序列问题,LSTM更是擅长捕捉长序列关系。LSTM由于有gate的存在,所以能够很好地学习和把握序列中的前后依赖关系,因此也就更加适合用来处理长序列的NLP问题。模型结构如下:
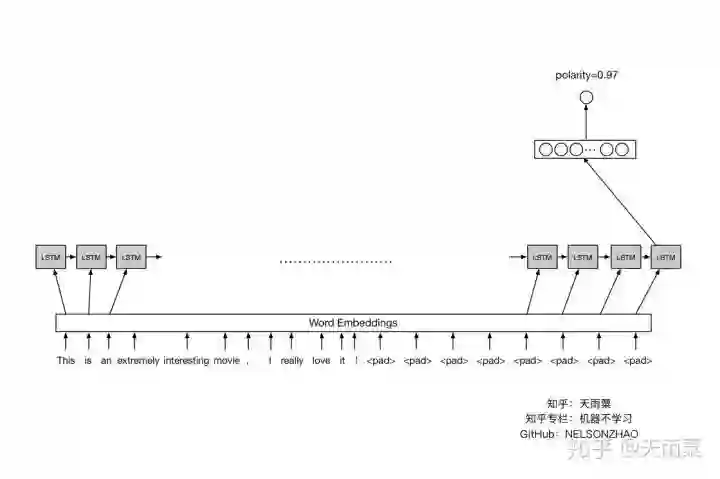
先将句子进行word embedding后,传入LSTM序列进行训练,将LSTM的最后一个hidden state拿出来,加入全连接层得到最终输出结果。
2. 模型代码
基于上述所说的LSTM结构,我们构造模型的代码如下:

上面的代码中和DNN中有几个部分是类似的,这里不再赘述。
在embeddings中,这里不同于DNN中词向量求和,LSTM不需要对词向量求和,而是直接对词向量本身进行学习。其中无论是求和还是求平均,这种聚合性操作都会损失一定的信息
在model中,我们首先构造了LSTM单元,并且为了防止过拟合,添加了dropout;执行dynamic_rnn以后,我们会得到lstm最后的state,这是一个tuple结构,包含了cell state和hidden state(经过output gate的结果),我们这里只取hidden state输出,即lstm_state.h,对这个向量进行连接,最终得到输出结果
optimizer和evaluation和DNN模型类似,不在赘述
3. 训练模型
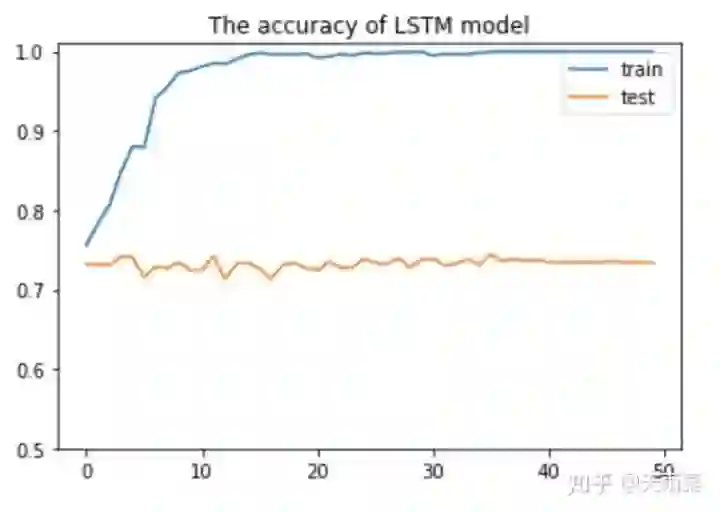
模型构建完毕后,设置超参数进行训练,这里我用了单层512个结点的LSTM。将每一轮的训练数据准确率和测试数据的准确率绘图如下:
用训练好的模型对test数据进行预测,得到准确率如下:
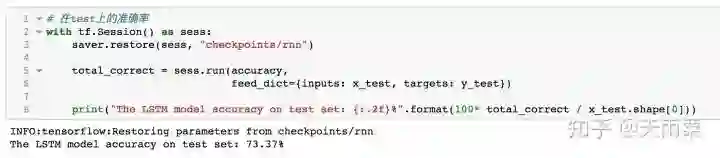
emmmm,好像看起来和DNN的结果差不太多,LSTM有点过拟合了,我没有认真调参~,另外,这也说明pre-trained词向量给DNN模型带来了很大的效果,使得它能够逼近LSTM的准确率;另外,相比于DNN,LSTM模型在train上收敛速度更快。
四. CNN模型
1. 模型结构
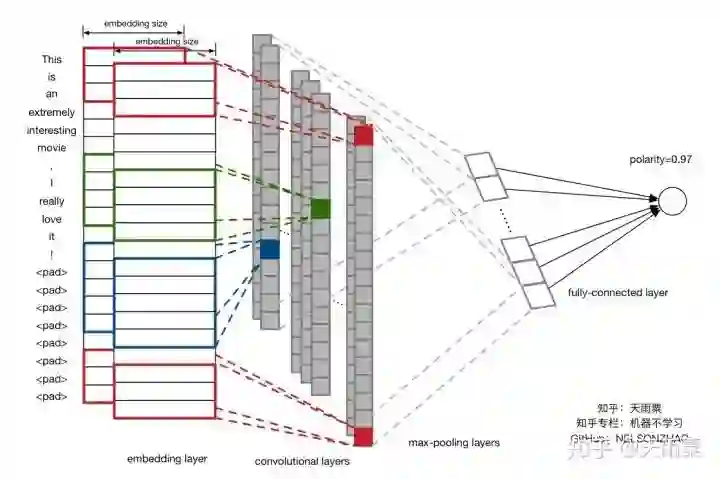
与LSTM捕捉长序列的特点不同,CNN捕捉的是局部特征。我们都知道CNN在图上处理中取得了很不错的效果,这是因为它的卷积和池化操作可以捕捉到图像的局部特征。同理,CNN用在文本处理上,也可以捕捉到文本中的局部信息。下面的实现均参考Yoon Kim在2014年发表的TextCNN的那篇论文。模型结构如下:
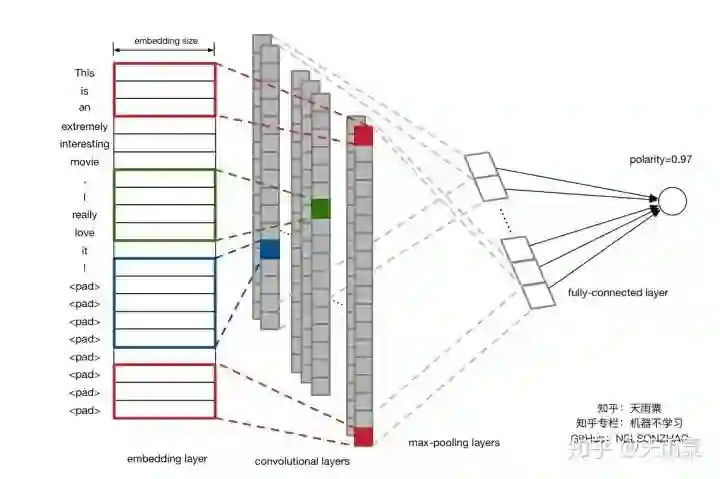
如上图所示,假设我们句子长度为20,不足的用<pad>补全。输入句子序列后,经过embedding,我们获得每个单词的词向量(假设词向量维度为300),则我们就得到一个sentence_len * embedding_size的矩阵,如上图中embedding layer所示。在这里我们就可以将它看做是width=embedding_size,height=sentence_len,channel=1的一张图片,那么我们就可以用filter去做卷积操作。
接下来我们采用了3种filter,Yoon Kim在论文中提到了三种filter size分别是3,4,5,每种filter有100个。如上图所示,红色的filter为height=3,width=embedding_size,channel=1;绿色height=4,蓝色height=5。那么为什么这里的filter在width上都要保持和embedding_size一致呢,其实很好理解,width代表的是词向量的大小,对于一个单词来说,其本身的词向量分割是没有意义的,卷积操作的目的是在height方向滑动来捕捉词与词之间的局部关系。
经过卷积操作后,我们就得到了如上图中所示convolutional layers的输出,多个列向量;再经过max-pooling操作来提取每个列向量中的最重要的信息。最终连一层fully-connected layer得到输出结果。
2. 模型代码
TextCNN的代码其实很简单,只要我们能够构造出那张图,后面就直接按照图片卷积操作就可以完成。
由于代码比较长,我们分每个name_scope来看,并且像placeholders,evaluation这种和DNN、LSTM部分一样的就不再赘述,这里只讲解关键部分的代码。
完整代码见我的GitHub
embeddings
首先是embeddings,这个和DNN与LSTM有区别,其实就是多了一行代码。因为卷积操作要求有channels这个维度,因此,我们构造完embed以后,实际上shape=(batch_size, vocab_size, embedding_size),但是Tensorflow中卷积要求的维度为(batch_size, heights, widths, channels),因此通过expand_dims增加channels维度。

convolution-pooling
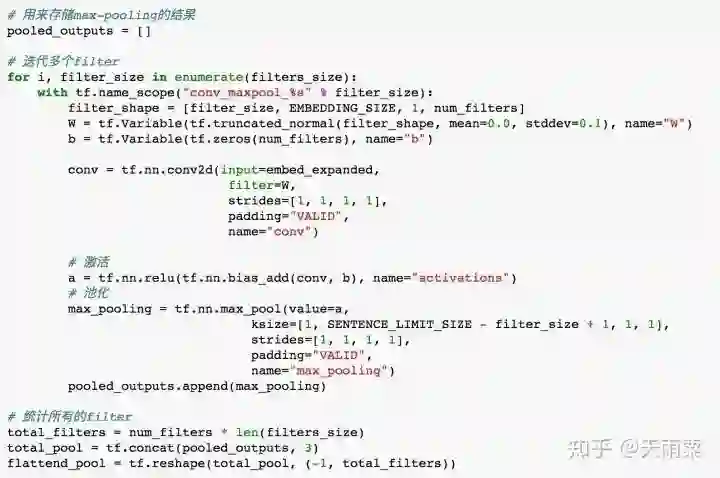
由于我们采用了多种filter(filter size=2, 3, 4, 5, 6),因此对于卷积池化操作要分filter处理。首先定义了pooled_outputs用来存储每种filter的卷积池化操作输出结果。
对于每个filter,先经过卷积操作得到conv,再经过relu函数激活后进行池化,得到max_pooling。由于我们每个filter有100个,因此最终经过flatten后我们可以得到100*5=500维向量,用于连接全连接层。
outputs

Yoon Kim在论文中提到了添加dropout可以带来模型性能提升,因此在这里加入dropout。最后output层进行全连接,经过sigmoid激活输出最终的结果。
loss

不同于之前的模型,这里loss上添加了全连接层权重W的L2正则。虽然Yoon Kim说加不加L2无所谓,但是我自己尝试以后发现加了L2会带来模型在test上的性能提升。
3. 训练模型
经过模型训练,可以得到train和test的准确率变化,如下图:
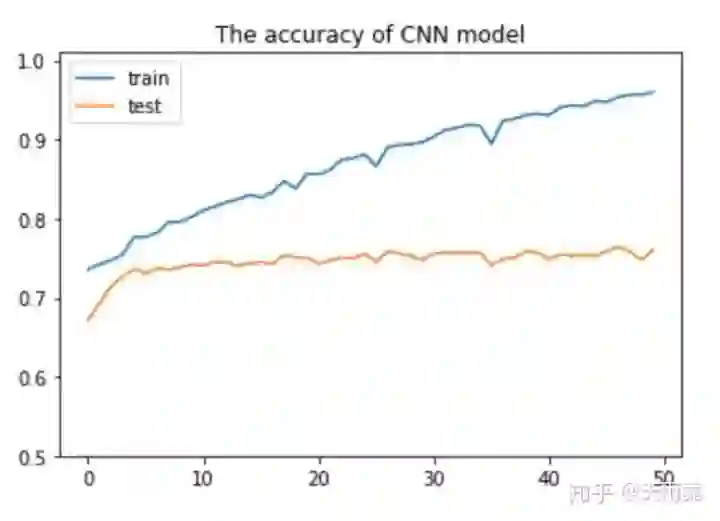
由于我们加入了L2正则和dropout,可以发现模型在train上并没有DNN和LSTM那么过拟合,并且迭代50个epoch以后train上准确率还有上升空间。在test上,模型基本在第10轮以后就差不多稳定了。
我们来用模型预测test的准确率:
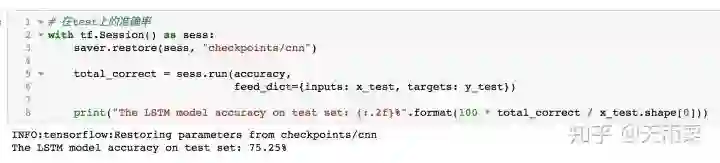
可以看到这个准确率相比于DNN和LSTM模型都有了提升,在test上准确率为75.25%。可以看到TextCNN如此简单的模型却能达到相对较高的准确率。
五. CNN模型进阶版
1. 模型结构
CNN模型的进阶即在TextCNN的基础上为embedding多添加一个channel。在第四部分,我们用pre-trained word embeddings构造了shape=(sentence_len, embedding_size, 1)的图,由于pre-trained word embeddings并不在模型中进行训练,因此我们称为static embedding;Yoon Kim在论文中还提到了non-static embedding,即需要随着模型训练的embedding层。这一层可以采用随机初始化,也可以用pre-trained word embedding初始化并进行fine-tune,它的目的在于捕捉task-specific的信息。具体模型结构如下:
可以看到这个与第四部分模型不同的就是在于我们的embedding layer有两层。即在static embedding的基础上添加了一个non-static embedding,相当于原来只有1个channel的图变成了2个channel。添加non-static embedding的好处在于,模型可以通过对语料的学习,得到task-specific的信息。
2. 模型代码
由于这个multi-channel仅仅是在第四部分的模型上添加一个可以trainable的embedding,因此我只放了embedding层的代码:

这里我们除了static的embeddings以外,还要构造一个non-static的embedding,我们用随机初始化来填充non-static embedding。得到这两个embedding以后,只需要按照channel堆叠起来就可以得到shape=(sentence_len, embedding_size, 2)的tensor。
后面的部分就和上述1层channel的模型一样啦,注意这里filter在channel方向上的值要设置为2。
3. 训练模型
经过模型训练,我们绘制其在train和test上的准确率变化图,如下:
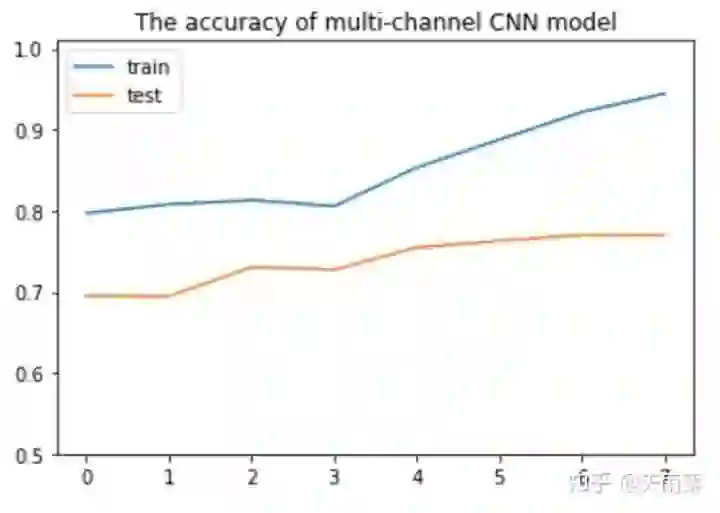
这里我只训练了8轮,因为我发现往后训练的话会发生严重过拟合。因为我们的训练语料其实不是很多,而且又加了一层embedding,这就使模型非常容易过拟合。因此我设置了8轮epoch,可以使得模型在test上取得不错的效果。
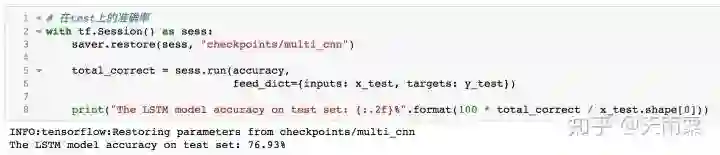
如上图所示,multi-channels在test上的准确率为76.93%,高于之前的三个模型。
六. 总结
至此为止,我们已经完成了分别用DNN、RNN以及CNN处理sentence classification的任务。其中,DNN和RNN在test上的准确率相差无几,而CNN在test上的准确率要高出1%~2%,multi-channels CNN在test准确率高达76.93%,并且训练次数也较少。
我们的模型都相对比较简单,但总体来说这几个模型都取得了不错的准确率,其很大程度上来自于pre-trained word embedding,可见word embedding在NLP模型中的重要性,而multi-channels CNN的准确率提升则在于加入了task-specific的信息。
另外,我们再来从直觉上进一步理解DNN、RNN、CNN这几个模型在NLP处理上的区别,我们以情感分析为例。
首先DNN是最简单的模型,并且它没有处理序列关系的功能,因此在NLP的很多任务中表现并不是很好,如下图所示:
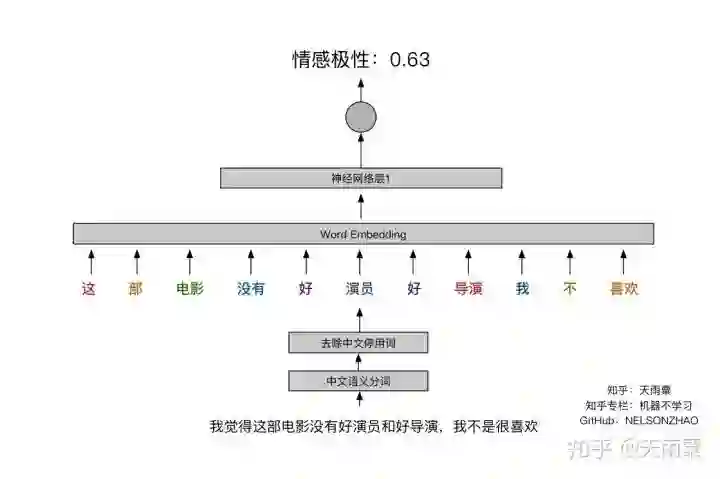
这个句子本身是一个negative的句子,但是我们知道DNN对于text的处理是将词向量相加,因此当这个句子中的positive词汇大于negative词汇时,模型就很容易判定错误。上面的句子中有2个”好“和1个”喜欢“,而否定词仅有”没有“和”不“,因此模型就会认为这是一个positive的句子。但实际上”没有“否定了”好“,”不“否定了”喜欢“。
再说RNN(LSTM),如下图:
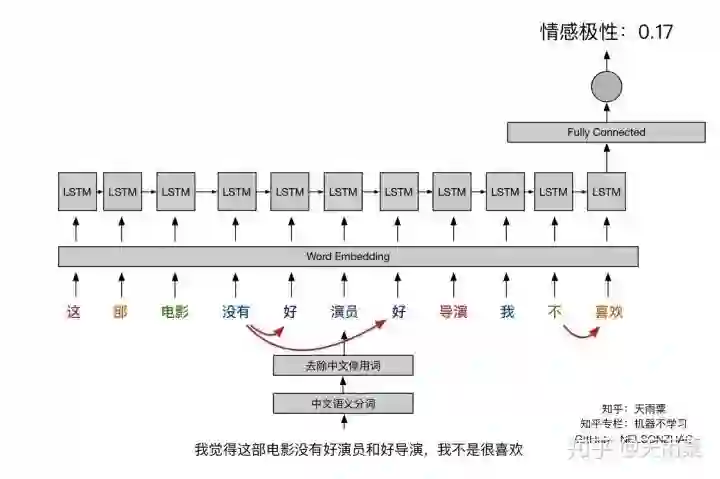
RNN的好处在于它能够捕捉长序列关系,这种长序列关系的捕捉靠的就是gate。正因为有gate存在,模型才会学习到哪些信息需要保留,哪些信息需要遗忘。在处理中,当模型看到”好“时,它仍记得之前有否定词”没有“,同理,对于”喜欢“和”不“的关系也能够学习到。
最后说CNN,如下图:
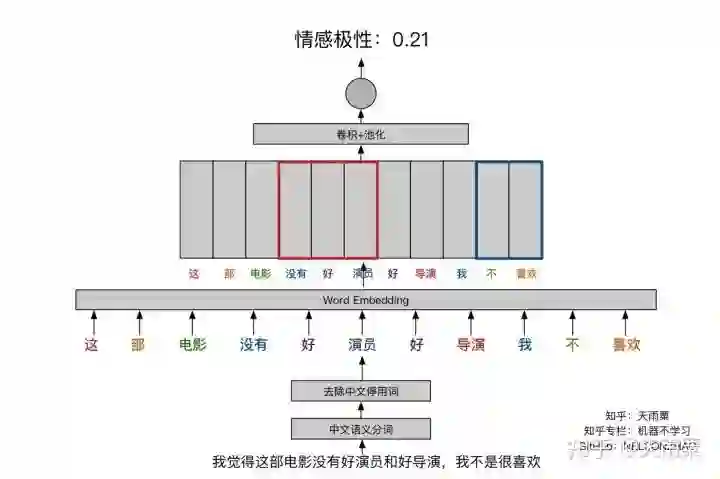
CNN虽然没有RNN这种序列依赖的结构,但它的卷积操作实质上是对局部信息的捕捉,池化则是对局部重要信息的提取。例如,上面的红色框是一个size=3的filter,蓝色框是一个size=2的filter。他们分别能够捕捉到局部的”没有-好演员“和”不-喜欢“这样的否定关系,因此也一样能够正确对句子进行分类。
总而言之,DNN无法捕捉序列关系,RNN(LSTM)可以捕捉长依赖序列关系,CNN可以捕捉局部序列关系。





