学界 | DeepMind提出空间语言集成模型SLIM,有效编码自然语言的空间关系
选自arXiv
作者:Tiago Ramalho , Tomáš Kociský等
机器之心编译
参与:陈韵竹、路
前不久,DeepMind 提出生成查询网络 GQN,具备从 2D 画面到 3D 空间的转换能力。近日,DeepMind 基于 GQN 提出一种新模型,可以捕捉空间关系的语义(如 behind、left of 等),其中包含一个基于从场景文本描述来生成场景图像的新型多模态目标函数。结果表明,内部表征对意义不变的描述变换(释义不变)具备稳健性,而视角不变性是该系统的新兴属性。
论文:Encoding Spatial Relations from Natural Language

论文链接:https://arxiv.org/pdf/1807.01670.pdf
摘要:自然语言处理通过分布式方法在学习词汇语义方面有了重要进展,但是通过这些方法学习到的表征无法捕捉真实世界中隐藏的特定种类的信息。具体来说,空间关系的编码方式与人类的空间推理不一致且缺乏视角变换不变性。我们展示了这样一个系统,它能够捕捉空间关系的语义,如 behind、left of 等。我们的关键贡献是一个基于从场景文本描述来生成场景图像的新型多模态目标,以及一个用于训练的新型数据集。我们证明,内部表征对意义不变的描述变换(释义不变)具备稳健性,而视角不变性是该系统的新兴属性。
1 引言
人类能够通过自然语言唤起彼此脑海里的表征。当人们描述对一个场景的看法时,对话者能够形成该场景的心理模型,并想象所描述的对象从不同的角度看起来是怎样的。在最简单的层面上,如果有人站在你面前并描述一个物体位于他们左边,你就知道它在你的右边。嵌入自然语言意义的现有模型无法实现这样的视点集成(viewpoint integration)。事实上,如 Gershman 和 Tenenbaum(2015)所言,从单语语料库中提取的自然语言分布式表征无法理解语义对等,例如「A 在 B 前面」等同于「B 在 A 后面」。
我们认为,朝人类水平的理解场景描述能力发展的重要一步是建立能够捕捉这些不变性的表征。在本文中,我们介绍了一个能学习此类表征的多模态架构。为了训练和验证该模型,我们创建了一个 3D 场景的大型数据集,包括场景和不同角度的语言描述。我们对学到的表征进行评估,通过从训练数据中未看到的角度生成图像并检查它们是否符合这种新角度下对场景的自然语言描述,来确保它们确实能够泛化。我们还发现,我们学习的表征很符合人类关于场景描述的相似性判断。
众所周知,空间自然语言模糊不清,难以计算处理(Kranjec et al. 2014; Haun et al. 2011)。即使是「behind」这样看似简单的介词也无法明确描述,而需要分级处理(graded treatment)。此外,空间概念的词汇化在不同语言和文化之间可能存在很大差异(Haun et al. 2011)。另外,人类在描述空间体验(Landau and Jackendoff 1993)时以及方位词层次中(Kracht 2002)表达几何属性的方法更加复杂。研究者虽然对人类类别空间关系的处理、感知和语言理解之间的关系进行了大量研究,但对于如何在计算上遍码这种关系几乎没有明确的结论(Kosslyn 1987; Johnson 1990; Kosslyn et al. 1998; Haun et al. 2011)。

图 1:具有对应真值图像的示例描述。如图所示是自然语言(NL)描述和合成语言(SYN)描述。其中保留了标注语言错误。
在自然语言处理领域,空间关系的研究主要集中在从文本中提取空间描述并将其映射到形式符号语言(Kordjamshidi et al. 2012a,b),在这一方面研究者提出了很多标注体系和方法(Shen et al. 2009; Bateman et al. 2010; Rouhizadeh et al. 2011)。与此同时,可视化空间描述方面的研究大量依赖手动创建的表征,不具备分布式表征的通用跨任务优势(Chang et al. 2014; Hassani and Lee 2016)。
2 基于视觉的场景描述数据集
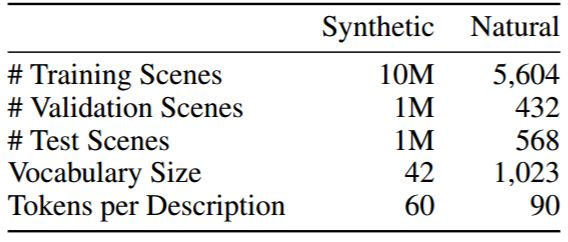
表 1:数据集统计结果。
B.1 数据集示例
B.1.1 合成语言,两个对象

B.1.2 合成语言,三个对象

B.1.3 自然语言,两个对象

B.1.4 自然语言,三个对象

3 模型描述
我们提出了一种模型,该模型学习将单个底层输入的多种描述集成到单个表征中,随后在多模态设置中利用该表征生成新数据。
我们将该模型称为空间语言集成模型(Spatial Language Integrating Model,SLIM)。其灵感来自于生成查询网络(Generative Query Network,Eslami et al. 2018),该网络集成了多个视觉输入,可用于生成相同环境的新视图。为了让表征能编码视点无关的场景描述,设置该模型使之在构建表征之前不知道哪个视点会被解码。在我们的例子里,向模型输入从 n 个不同视点所看到的场景的文本描述,以编码成场景表征向量。然后,利用该向量重建从新视点看到的场景图像。
如图 2 所示,我们提出的模型由两部分组成:一个表征网络,它从多视点场景的文本描述中生成聚合表征(aggregated representation);一个以场景表征为条件的生成网络,它将场景渲染为新视点下的图像。我们对这两个网络进行了如下描述(详见附录 A)。
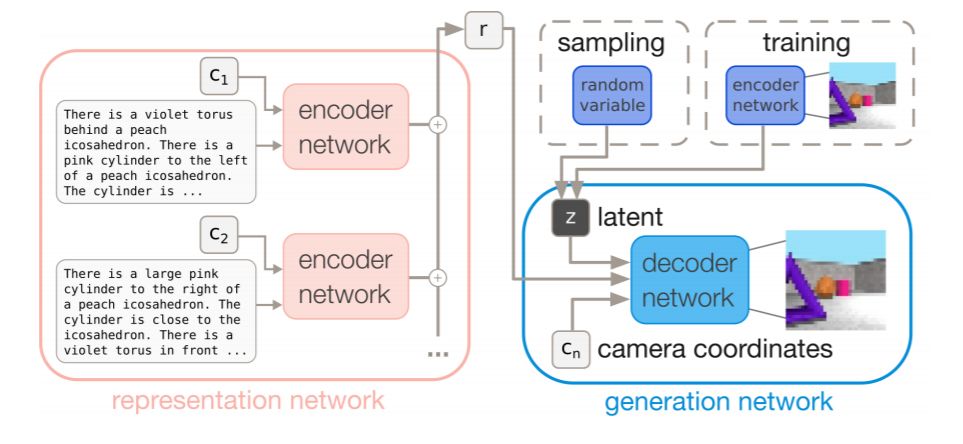
图 2:模型图示。表征网络解析多个摄像机坐标拍摄的多视点场景的多个描述和文本描述。所有视点的表征被聚合成一个场景表征向量 r,然后生成网络使用该向量 r 来重建从新的相机坐标看到的场景的图像。
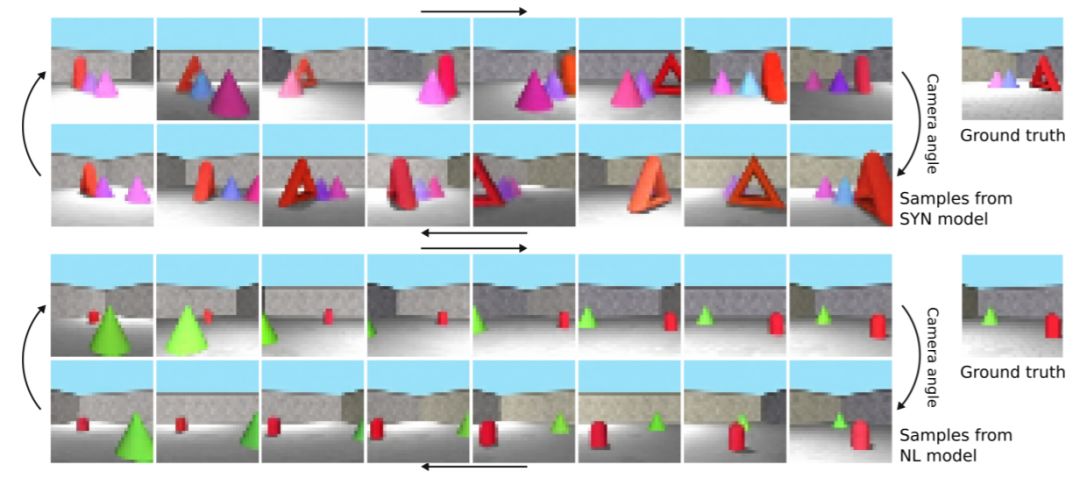
图 3:从合成语言(顶部)和自然语言(底部)模型生成的样本。相应的描述是:「There is a pink cone to the left of a red torus. There is a pink cone close to a purple cone. The cone is to the left of the cone. There is a red torus to the right of a purple cone.」;「There are two objects in the image. In the back left corner is a light green cone, about half the height of the wall. On the right side of the image is a bright red capsule. It is about the same height as the cone, but it is more forward in the plane of the image.」
4 场景编码实验
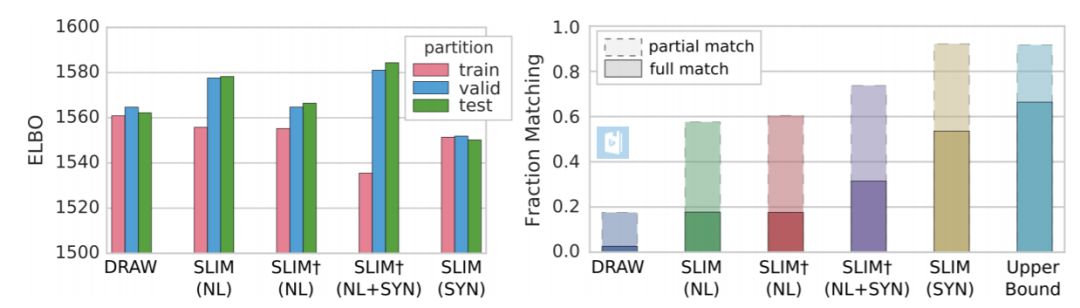
图 4:训练中用于训练/验证/测试分割的模型变体的 ELBO 值。人类对视觉场景样本和相应描述之间一致性的排名。对于 SLIM†(NL + SYN),仅根据自然语言输入计算。
5 表征分析
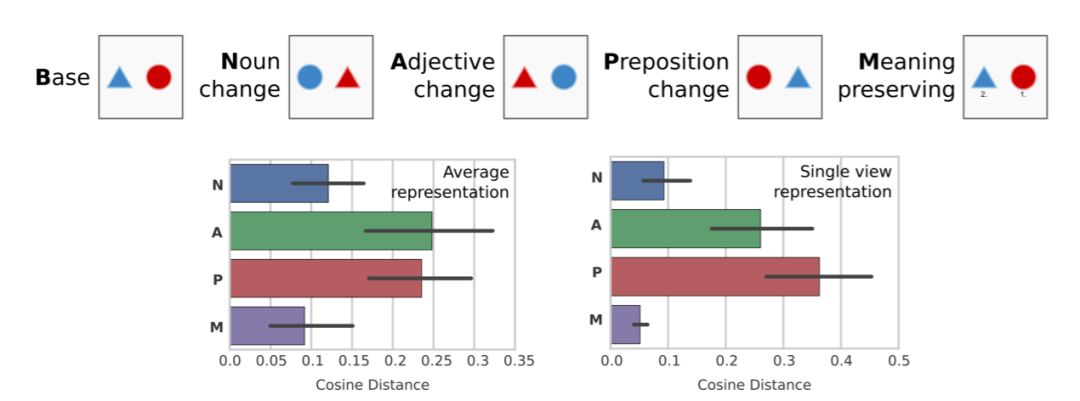
图 5:上面的图是用于测试表征相似性的场景变换可视图。左下角是基本表征和将四种变换方法中的一种应用于上下文输入而产生的表征之间的余弦距离。右下角采取相同的分析方法,但其对象是单个编码器步骤生成的表征。黑条代表 95%CI。为了对比,人类的平均排名是 M> P> A> N(Gershman and Tenenbaum 2015)。

表 2: Gershman and Tenenbaum (2015) 变换。
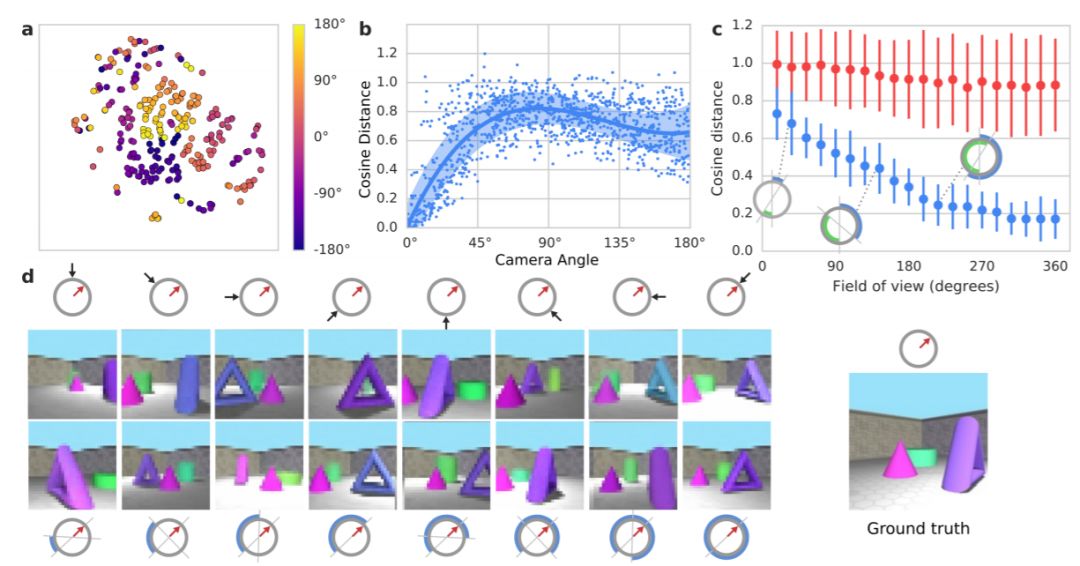
图 6:a) 单个描述编码的 t-SNE,根据不同摄像机角度着色。b) 同一场景单个描述表征之间的距离,是视点之间角度的函数。c) 从相对弧绘制的聚合表征之间的距离,是这些弧的大小的函数。蓝色对比相同场景表征,红色对比不同场景表征。d) 在不同的输入条件下,恒定场景和坐标的输出样本。顶部:单个描述(黑色箭头方向),底部:来自越来越大的弧的聚合描述。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
