人脸识别|人证比对《DocFace+: ID Document to Selfie Matching》论文解读(附代码)
由极市、机器之心和中科创达联合举办的“2018计算机视觉最具潜力开发者榜单”评选活动,现已接受报名,杨强教授、俞扬教授等大牛嘉宾亲自评审,高通、中科创达、微众银行等大力支持,丰厚奖励,丰富资源,千万渠道,助力您的计算机视觉工程化能力认证,提升个人价值及算法变现。极市与您一起定义自己,发现未来~点击阅读原文即可报名~
代码:https://github.com/seasonSH/DocFace
摘要:日常生活中需要大量的出示身份证来验证自己身份的场景,一般又慢又不可靠。所以,需要一个实时的高精度的人证比对系统。本文中,我们提出了DocFace++来解决这问题。我们首先展示了基于梯度的优化方法在每个类别只有很少样本的时候,收敛的很慢。为了克服这个缺点,我们提出了一种方法,叫做动态权值imprint(不知道怎么该翻译这个imprint),来更新分类的权值,这样可以收敛的更快,特征表达更加的泛化。接下来,我们训练了一对部分共享参数的姐妹网络,来学习特定域的人脸表达。在ID-selfie数据集上的交叉验证显示,SphereFace只有59.29±1.55%的TAR在FAR为0.1%的时候,而DocFace+能提升到97.51±0.40%。
1 介绍
人证比对相比通用的人脸识别,要面对许多不一样的问题。对于典型的非限制场景的人脸识别服务,主要的挑战是姿态,光照,表情(PIE)的差别。而对于人证比对,在进行图像采集时,人一般都是配合的,所以PIE的差别一般是很小的。困难主要来自于(1)低质量的身份证照片(2)身份证照片和生活照之间的年龄差别,如下图。另外,由于需要使用深度学习的方法进行训练,缺少大量的数据也是需要面对的困难之一。

我们的前期工作DocFace首先研究了Deep CNN在这个问题上的应用。在本文中,我们首先简单回顾了一下以后的工作,然后将我们的前期工作DocFace扩展成一个更加高级的方法,DocFace+,来建立一个人证比对的系统。我们使用一个大型的中国身份证数据集来开发这样一个系统和评估不同方法的表现:(i)两个COTS人脸比对器 ,(ii)开源的深度学习人脸比对器,(iii)我们提出的方法。我们还对比了在公开数据集上的表现,本文的主要贡献有:
一个基于分类的新的优化方法,用在少样本的数据集上。
一个新的识别系统,包括一对部分共享权值的网络用来学习人证对的各自的特征表示。
对COTS的人脸比对器开源的人脸比对器进行了评估,表明了人证比对是和通用的人脸比对不一样的问题。
一个开源的人脸比对器,DocFace+,用作人证比对,可以显著的提升通用人脸比对器的能力。实验表明,
SphereFace只有59.29±1.55%的TAR在FAR为0.1%的时候,而DocFace+能提升到97.51±0.40%。
2 相关的工作
2.1 人证比对
和我们的前期工作[1]同时期的工作[2]同样也是基于深度学习的人证比对系统,使用了2.5M个人脸对,也是私有的数据集,他们将整个问题看做是一个双向采样的问题,通过三个阶段来训练:(1)在通用的人脸数据集上预训练分类器(2)迁移学习(3)finetune学习分类器。我们的工作,提出了一个优化的方法来解决收敛慢的问题,而且不需要多个步骤的训练。对比我们之前的工作,差别有:(1)更大的数据集(超过50000对),(2)不同的损失函数,称为DIAM-Softmax,用来学习人脸表示,(3)更加全面的实验,用来分析每个模块的作用,(4)评估我们的系统和已有的其他的系统的性能。
2.2 深度人脸识别
自从深度学习应用到人脸识别中,对人脸识别的能力提升了很多,最常用的方法是使用softmax进行分类的训练。考虑到softmax的loss只是让类间的差别变大,并没有使类内的差别变得内聚。后来提出了度量学习的方法,如对比损失和triplet的损失,提升了在LFW上的表现。后面又提出了度量学习和分类损失的结合的方法,叫做A-Softmax。后来又提出了AM-Softmax,将margin引入到了角度的度量中,比A-Softmax更加鲁棒。
2.3 异构人脸识别
异构人脸识别指的是来自不同形态的人脸识别,比如可见光图像,近红外图像,热红外图像,草图等等。人证比对可以看做是一种特殊的异构人脸比对,两种图像来自于不同的领域。通常异构图像的人脸比对的方法分为两种:基于生成图像的方法和基于可分特征的方法。基于生成图像的方法是指将一种图像转换成另一种,然后使用通用的人脸比对方法。基于可分特征的方法是指将来自于两种不同领域的图像,映射到同一个共享的特征空间中。
2.4 Low-shot(小样本学习)
另外一个相关的领域叫做小样本学习问题。在小样本学习中,模型训练之后可以泛化使用在没有见过的只有很少的几个样本的类别中。小样本学习有两个步骤:首先在大的分类数据集上学习,在测试的时候,将新的类别的少量标注样本放到模型中训练一个新的分类器。小样本学习的意思是每个类别中只有很少的图片。在人证比对的数据集中,每个人也只有很少的图片。[3]提出了一种imprint the weight的方法,我们注意到他们的方法和我们的差别在于他们利用imprinted权重作为初始化参数,而我们使用参数的imprint来进行参数更新。
3 数据集
本节我们简单介绍一下我们使用到的数据集。如下图:

3.1 MS-Celeb-1M
这个数据集是公开的,包括8,456,240张图片,99,892个不同的人,大部分从网上下载,在我们的迁移学习框架中,这个数据集作为源领域,用来训练深度网络的丰富的浅层特征。然而,这个数据集有很多的噪声,我们使用的是清理过的数据集,共有5,041,527张图像,98,687个人。数据集的中的部分图片如图1(a)。
3.2 Private ID-selfie
这是个私有的数据集,包含了116914张图像,53591个人。每个人只有一张身份证照片。其中53054个人只有一张自拍照,另外的537个人有多张自拍照。身份证照是从身份证的芯片中读出来的。在实验中,我们构建了5折交叉验证数据集来评估我们的方法中不同部分的效果。数据集的中的部分图片如图1(b)。
3.3 Public IvS
这是个公开的数据集,由[2]发布,用来评估人证比对的能力。数据包括1262个人,5503张图片,每个人有1张身份证照片,1~10张自拍照。这个并不是标准的人证比对,因为身份证照并不是来自实际的身份证,而是类似的证件照。部分照片见图1(c)。
4 方法
4.1 概述
我们首先在MS-Celeb-1M上训练了一个基线模型,然后迁移到我们的目标领中,我们使用了流行的Face-ResNet结构[4],使用了AM-Softmax的损失函数。然后,我们提出了新的优化方法DWI,来更新权值,训练了一对姐妹网络,共享高层的参数。流程见下图:

4.2 原始的AM-Softmax
我们使用了原始的AM-Softmax来训练基线模型。我们简单回顾一下AM-Softmax的方法。假设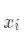
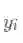
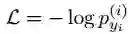
其中:
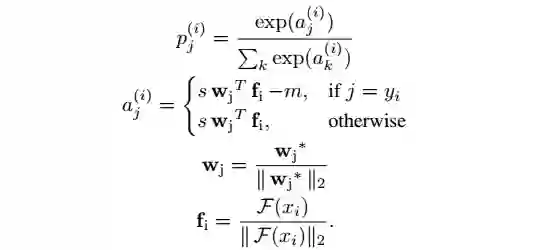
其中,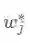
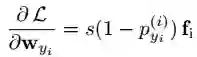
这个梯度作为一个具有吸引力的信号,将
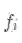
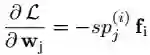
这个梯度提供了排斥的信号,将
4.3 动态权值Imprint(DWI)
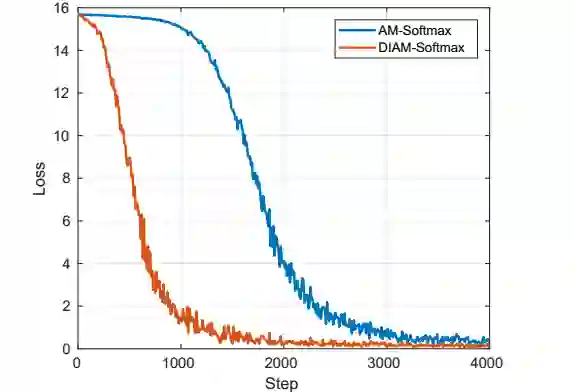
虽然AM-Softmax和其他类似的分类学习的方法在通用的人脸识别数据集上取得了很大的成功,我们发现在ID-selfie上却表现不好。事实上,这些方法经常收敛的很慢,而且容易陷入到局部最优中。如下图,AM-Softmax开始的时候并没有收敛,直到几个epoch之后才开始收敛。
为了得到这个问题的更多的线索,我们提取了特征的样本还有归一化之后8个类别的权值向量,然后通过t-SNE降维到2,通过可视化的方法显示如下。圆点是样本点,菱形是归一化的权值。在AM-Softmax中许多权值向量在数据集很小的时候偏离了对应的分布,如橘黄色代表的类别和紫色代表的类别。
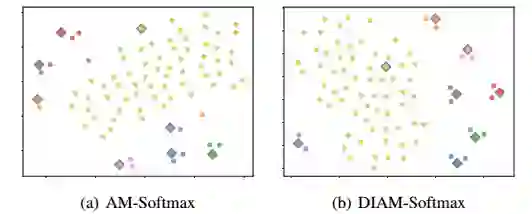
注意一下,这些偏移甚至是在收敛之后的。这样的偏移在通用的数据集中影响不大,因为有互斥信号的存在,大部分的不同的类别之间还是可以分开的。但是在每个类别只有很少样本的数据集中,这种伤害就会变大。这主要是由于优化方法造成的。因为SGD在是通过mini-batch进行更新的,在一个只有两个样本的类别中,每个权值向量在一个epoch中只能收到两次吸引信号。再乘以学习率,这个稀疏的吸引信号对权值的影响变得很小。这种稀疏的信号导致了最后的分类层权值的欠拟合而不是过拟合,导致了特征分布的偏移,从而使得收敛变慢。
基于上面的观察,我们提出了不同的优化方法。主要的思想是基于样本的特征来更新权值,避免欠拟合,加速收敛。这种权值imprinting的方法之前有人研究过,不过是用在权值初始化上的。收到center loss的启发,我们提出了动态权值Imprinting的方法来更新权值:
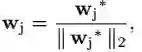
其中:
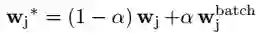
这里的

直观上,DWI能够加速权值的更新,利用样本的特征,和优化器的参数设置无关。对比基于梯度的优化方法,他每次的更新基于同类的样本,不考虑其他类别的互斥性。这个可能会引起一些疑虑,这样的是否可以优化我们的loss。根据经验表明,我们发现DWI不仅可以优化损失函数还可以帮助收敛的更快如图6,7。我们的交叉验证结果表明在ID-selfie数据集上,DWI比SGD要好,即使我们训练SGD的时间是两倍以上。见下表:
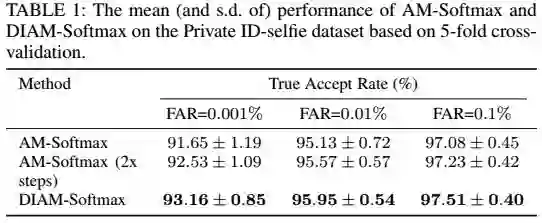
注意,DWI并不是专门为AM-Softmax设计的,也可以用在其他的方法中,如L2-Softmax,这只是一个权值更新的方法,并不影响loss函数的形式。从另外的角度,DWI也导出了一个新的损失函数,因为不同的分类器的权值的选择导致了不同的学习目标。这里,我们将综合了DWI和AM-Softmax的新的损失函数叫做DIAM-Softmax。
很重要的一点是,DWI并没有带来很多的计算,训练速度也是和之前一样的。另外,DWI只更新那些mini-batch中出现的权值向量,这就天然的是和那些类别数非常多的数据集,权值矩阵无法全部放到内存中,可以个mini-batch只加载一部分进行训练。
4.4 特定域的建模
人证比对的问题可以认为是异构人脸比对的一个特例,一个通用的方法是使用两个不同的模型将来自两个域的图像映射到同一个特征空间中。我们使用了一对姐妹网络,具有同样的结构,使用不同的参数。这两个模型的特征都是从基线模型中迁移得到的,具有相同的初始化值。虽然增加了模型的大小,但是推理时间是一样的。使用这样一对网络可以对不同的领域建模,但是更多的参数也增大了过拟合的风险。因此,和我们的前期工作不同,我们提出了高层共享权值的姐妹网络来防止过拟合。我们使用了一对Face_ResNet网络,只共享bottleneck层。
4.5 数据采样
当我们训练分类网络的时候,mini-batch通常是从数据集中随机选取的,由于我们的图是来自两个不同的领域,这种图像层次的均匀采样并不是最优的选择。一般身份证照片只有一张,而自拍照可能有多张,均匀采样可能导致身份证照片的模型训练有偏差。我们提出了一种不同的采样策略来处理数据集不均衡的问题,每一个迭代中,B/2个类别是均匀分布随机选择的,B是batchsize的大小,每个类别中选取一对身份证-自拍照来构建mini-batch,经验表明,这种策略能够比直接均匀采样效果更好,下面的实验会说到。
5 实验
5.1 实验设置
我们使用TensorFlow来进行所有的实验,我们在MS-Celeb-1M上训练基础模型,我们使用256的batch size,训练了280K个迭代。开始的学习率是0.1,然后160K迭代的时候,减少到0.01,240K迭代的时候,减少到0.001。在ID-selfie上finetune的时候,我们使用了batchsize为248,训练了姐妹网络4000个迭代。开始时,我们使用了小的学习率0.01,然后3200个迭代之后,减小到0.001。每次迭代都是用的SGD,momentum为0.9,weight decay为0.0005。所有的图片都通过MTCNN对齐,缩放到96x112。margin的参数m设为5。使用GeForce 1080Ti,推理速度是每张图片3ms。使用MS-Celeb-1M和AM-Softmax,我们的基线模型在LFW的准确率是99.67%,VR为99.6%在0.1%的FAR上。
在下面的章节中,都是使用5折交叉验证的方式进行评估的,整个数据集平均分成5份,拿其中4份进行训练,另外一份进行测试。我们使用全部的ID-Selfie进行交叉数据验证,使用余弦距离作为相似度的评分。
5.2 动态权值Imprinting
在这部分,我们希望可以对比出不同的权值imprinting策略如何影响DIAM-Softmax的表现,然后找出最好的设置。我们首先对比了不同的α然后评估了不同的
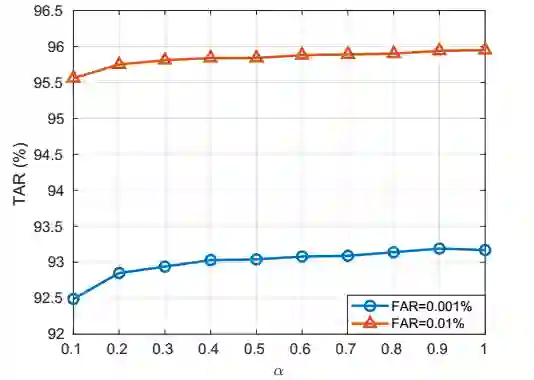
在上图中,我们通过在不同的类别中随机选择ID-selfie对来构建mini-batch,
不同的
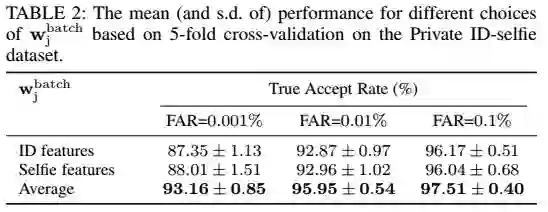
从表中可以看到,使用平均的特征,得到最好的效果。这个和[2]的结果有些不同,[2]中发现使用身份证图片的权值进行初始化效果最好。这个差别可能来自于不同的分类器权值更新的策略,我们是动态更新的,而不是固定的。大部分的类别中只有两张图像,只用其中一张图片来更新权值,容易造成loss的偏差。
5.3 数据采样
数据来自于两个不同的渠道,我们对比了三种不同的采样策略:(1)随机图像采样,(2)从不同的类别中随机的采样一对图像,(3)从不同的类别中随机采样身份证-自拍照图像对(我们提出的方法)。方法(1)是通常分类任务用的采样策略,方法(2)是度量学习中常用的策略,因为度量学习需要在minibatch中有同一个人的样本对。对于(1)和(2)分类器的权值根据每个类别的样本的特征的平均值来更新。对应的结果如下图:
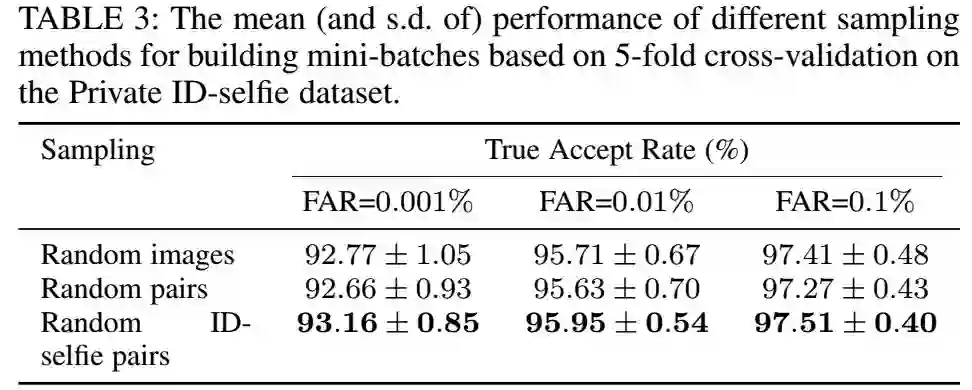
可以看出,随机采样要比随机采样图像对稍好一点,这是因为不同类别的采样的采样机会是不一样的,模型会更偏向小的类别,小的类别的采样机会更多一点。随机身份证-自拍照图像对的采样方式会更好一点,这表明平衡的参数学习在我们的这个问题中的重要性。这也暗示了应该通过解决类别的平衡的问题进一步的提升模型的能力。
5.4 参数共享
为了评估共享参数和特定域参数的作用,我们使用了不同的共享参数的子集来评估共享参数的影响。结果见下图:
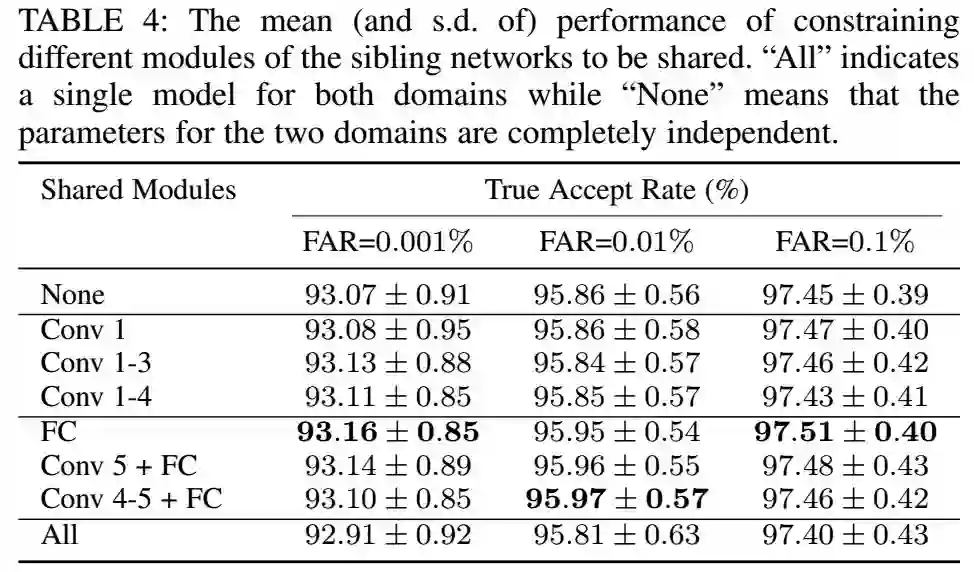
从表中可以看到,共享不同的参数的影响并不是很大,这是因为我们的基线模型已经能够学到比较好的参数,特别的,共享低层的参数的影响很小,但是共享FC层能够稍微的提升一点。然后再增加共享的层,又会变差一点,共享所有的参数,是所有的里面最差的。可以看到,两个不同的域确实是有一些差别,学习不同的域的模型,确实是有帮助的。
5.5 和静态权值Imprinting的对比
在[2]中,使用了固定的分类器的权值来进行精细的训练,比原来的效果有了较大的提升。我们把这样的方法称为静态的imprinting。静态权值imprinting的好处是,可以同时的提取所有的特征,更新分类器的权值。但是,这样不仅仅是需要额外的计算资源,而且不容易捕捉到全局最优。我们对比了动态权值imprinting和动态权值imprinting,对比结果如下:
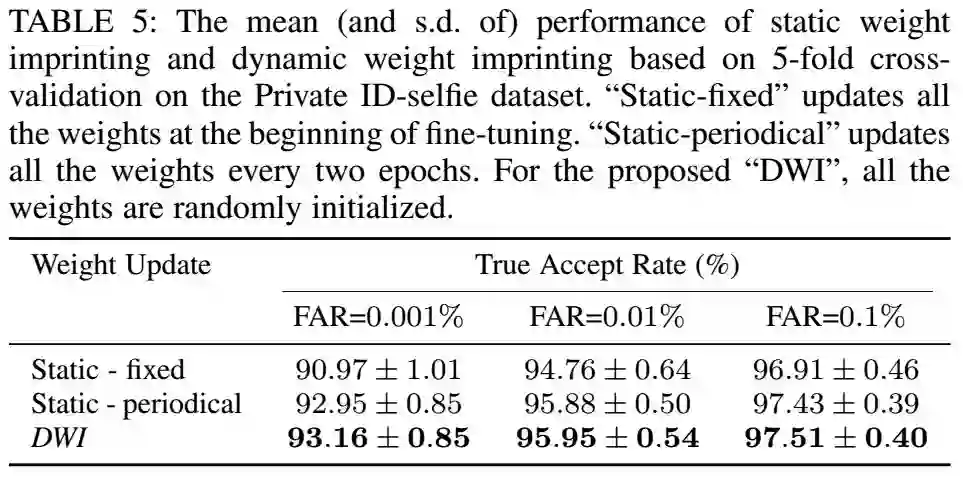
上表中,我们考虑了两种静态权值imprinting的方法(1)在finetune最开始的时候更新权值,然后训练的时候固定权值(2)每两个epoch更新一下权值。对于静态权值,我们从每一个类别中随机组成身份证-自拍照的图像对,然后提取特征向量的平均值进行权值的更新。从表中可以看到,periodical的方法比fixed方法好,fixed方法无法跟踪特征的分布。然而,periodical的方法需要大量的计算,在更新的时候我们需要提取大量的特征。相比之下,DWI不需要额外的计算,效果也更好。
5.6 对比不同的损失函数
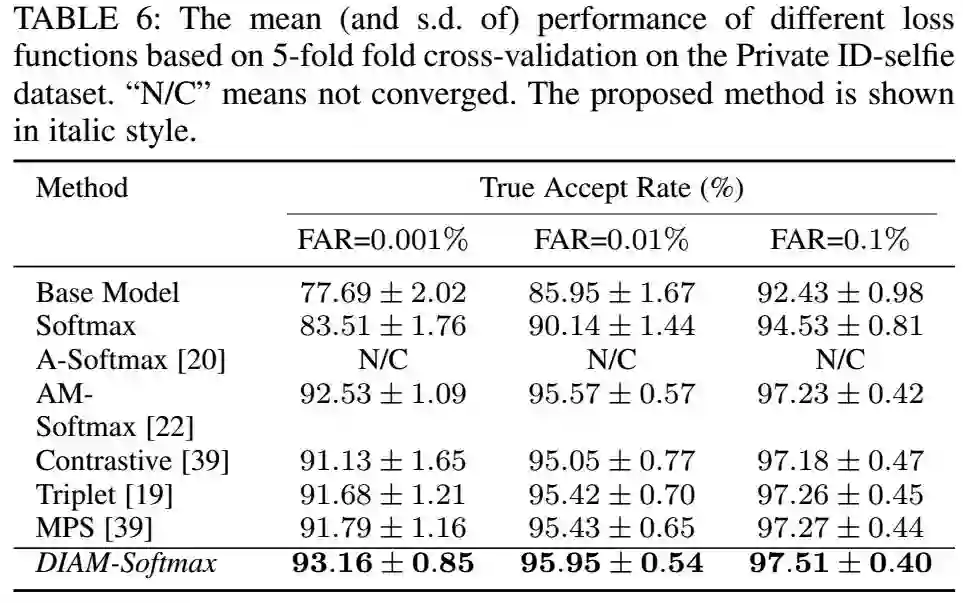
在这部分中,我们评估了使用不同的损失函数来finetuneID-selfie数据集的结果。我们对比了DIAM-Softmax和基于分类的嵌入学习的损失函数:softmax,A-Softmax,AM-Softmax,还有三个度量学习的loss,对比损失loss,三元组loss,和MPS loss,这是我们之前的工作。为了公平,我们全部使用TensorFlow,设置也是完全相同,除了AM-Softmax训练时间是其他的两倍。结果如下:
TAR的训练曲线如下:
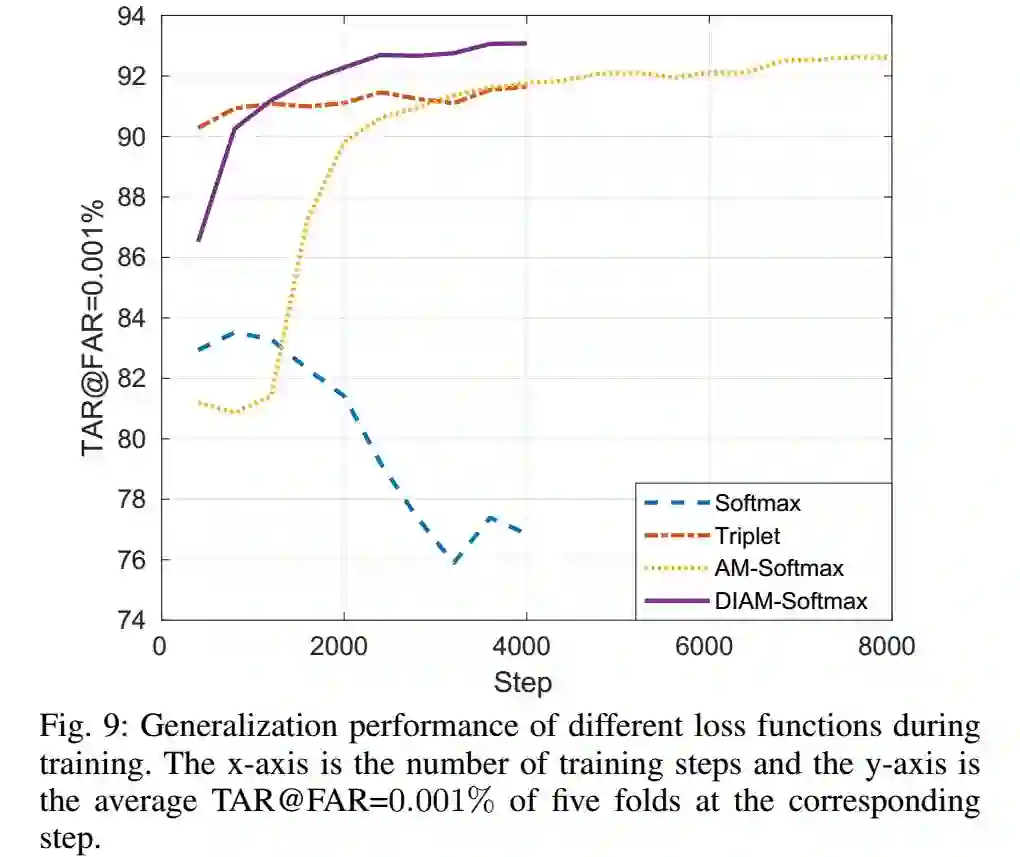
从图中可以看到,softmax很快就过拟合,度量学习的方式比较稳定,而且收敛很快,AM-Softmax比度量学习要好,但是收敛慢。DIAM-Softmax不仅收敛快,而且效果也好。
5.7 与现有方法的对比
比较的结果如下:
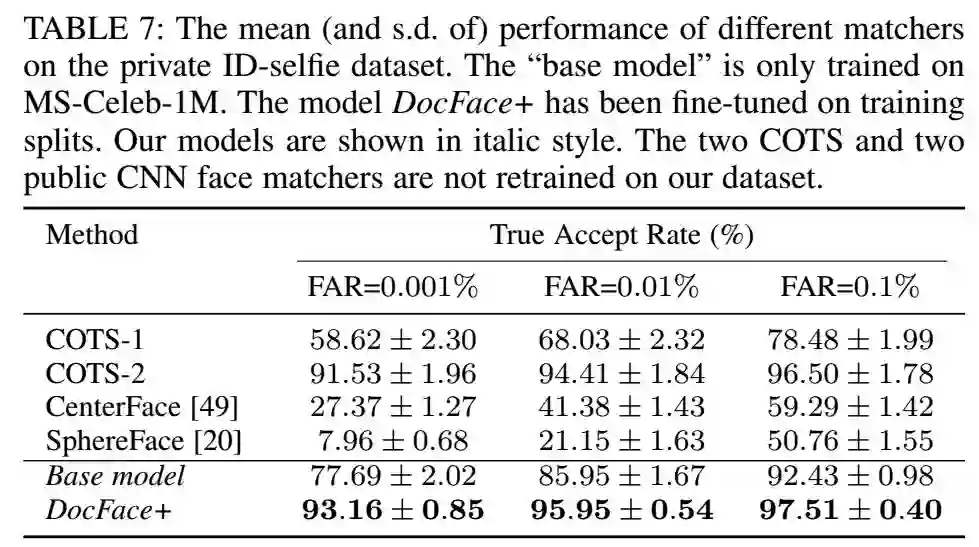
5.8 在Public-IvS数据集上的评估
对比结果如下:
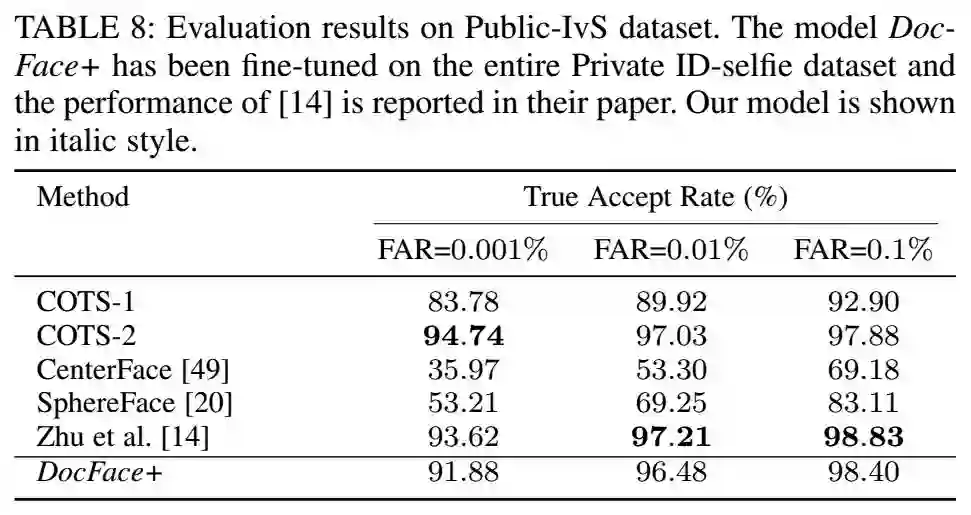
从表中可以看到,在这个数据集上的数据比在私有数据集上的数据要好,这说明这个数据集比我们的私有数据集要简单,因为这个不是真正的人证比对数据集,而是网上收集的。从数据上看,Zhu的效果比我们的好,但是我们的数据集只有120k张图像,而zhu的数据集有2.5M张图像。
6 总结
本文提出了一个新的人证比对的方法,DocFace+,通过迁移学习,通过在大数据集上训练基线模型,再在私有的数据集上进行finetune,使用了一个共享高层权值的姐妹网络,基于我们的观察,我们提出了DWI的优化方法,还有一个AM-Softmax的变体,DIAM-Softmax。实验表明,我们的方法不仅能加快收敛,还具有更好的泛化表现。我们做了很多的实验进行了很多的对比。各种对比表明,我们的方法能够取得非常好的结果。
参考文献
[1] Y. Shi and A. K. Jain, “Docface: Matching id document photos to selfies,” in BTAS, 2018.
[2] X. Zhu, H. Liu, Z. Lei, H. Shi, F. Yang, D. Yi, and S. Z. Li, “Large-scale bisample learning on id vs. spot face recognition,” arXiv:1806.03018, 2018
[3] H. Qi, M. Brown, and D. G. Lowe, “Low-shot learning with imprinted weights,” in CVPR, 2018
[4] A. Hasnat, J. Bohne, J. Milgram, S. Gentric, and L. Chen, “Deepvisage: Making face recognition simple yet with powerful generalization skills,” arXiv:1703.08388, 2017
作者:ronghuaiyang
来源:AI公园
https://mp.weixin.qq.com/s/A2LasCkDWMl8razmAl9vVw
*推荐阅读*
DeepMind&VGG提出基于集合的人脸识别算法GhostVLAD,精度远超IJB-B 数据集state-of-the-art
极市干货|小美&张德兵:分布式人脸识别及工业运用经验
如何走近深度学习人脸识别?你需要这篇超长综述 | 附开源代码
杨强教授、俞扬教授等大牛嘉宾评审团,万元大奖,丰富资源,助力您的计算机视觉工程化能力认证,点击阅读原文即可报名“2018计算机视觉最具潜力开发者榜单”~





