人脸聚类那些事儿:利用无标签数据提升人脸识别性能
随着模型越来越深,标注数据越来越难增加,人脸识别可能遇到瓶颈。本文来自MMLab香港中文大学-商汤科技联合实验室,提出一种有监督的Metric用于人脸聚类,来部分解决无标注数据内部结构复杂、依赖特定Metric、缺乏Outlier控制,以及时间复杂度等问题。
人脸识别也许是最成功也最先到达瓶颈的深度学习应用。在Go Deeper, MoreData,Higher Performance的思想指导下,模型更深了,数据却越来越难增加。目前在人脸的公开数据集标到了百万级别,人脸识别百万里挑一的正确率达到99.9%(MegaFace Benchmark)之后,发现再也标不动了。标注员能标出来的数据永远是简单样本,而人脸识别模型是个“深渊”,当你凝视“深渊”的时候,“深渊”并不想看到你。
“深渊”想看到这样的数据,并且明确被告知不是同一个人:

以及这样的数据,并且明确被告知是同一个人:

在把标注员弄疯之前,不如先让模型自己去猜一猜,说不定就猜对了呢?这其实就是半监督学习的思路。利用已有的模型对无标签数据做某种预测,将预测结果用来帮助模型训练。这种自我增强(Self-Enhanced)的学习方式,虽然看起来有漂移(Drift)的风险,但实际用起来还挺好用 [5]。对于闭集(Close-Set)的问题,也就是所有数据都属于一个已知的类别集合(例如ImageNet, CIFAR等),只需要模型能通过各种方法,例如标签传播(labelPropagation)等,预测出无标签数据的标签,再把它们加入训练即可。
然而问题来了,人脸识别是一个开集(Open-Set)的问题。
例如,人脸比对(Verification)、人脸鉴定(Identification)等任务中,测试样本的身份(Identity)通常没有在训练样本中出现过,测试过程通常是提取人脸特征进行比对,而非直接通过网络推理得到标签。同样,对于无标注数据,在采集的过程中,人脸的身份也是未知的。可能有标注的数据的人脸属于10万个人,而新来的无标注数据属于另外10万个人,这样一来就无法通过预测标签的方式把这些数据利用起来。而聚类不同于半监督学习,只需要知道样本的特征描述(Feature)和样本之间的相似度度量标准(Metric)就可以做聚类。聚完类之后再给每个类分配新的标签,同样可以用来帮助提升人脸模型。
人脸聚类方法
传统的人脸聚类一般采用LBP、HOG之类的手动设计的特征,因为这类特征过于过时,不在我们讨论的范畴。而深度学习时代的人脸聚类,一般采用卷积神经网络(CNN)中提取出来的特征 [4]。人脸识别的CNN通常把人脸图片映射(Embedding)到一个高维的向量,然后使用一个线性分类器,加Softmax激活函数和交叉熵损失(Cross Entropy Loss)来训练。
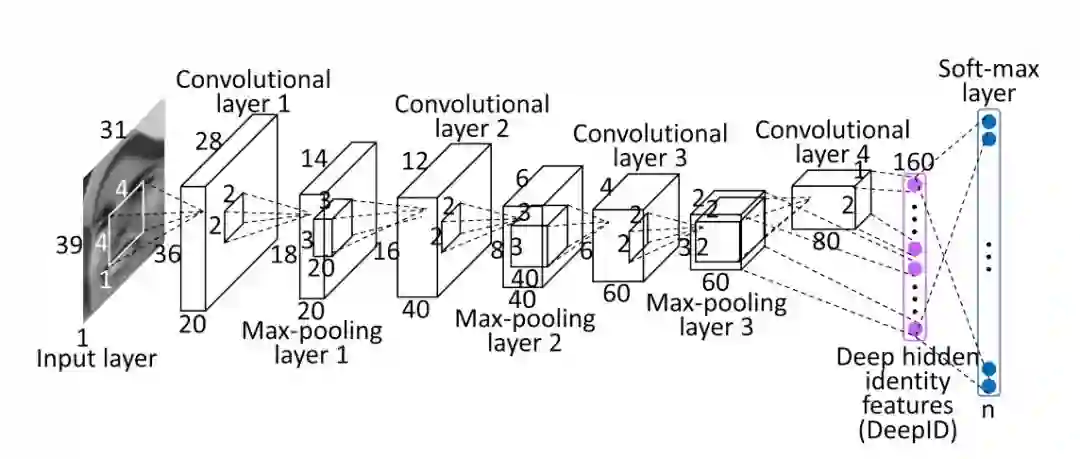
紫色的向量即为人脸特征(图片来自 [3])
这种方式决定了这些经过映射(Embedding)后的人脸在特征空间里分布在不同的锥形(Cone)中(下左图),因而可以使用余弦相似度(Cosine Similarity)来度量相似度。或者如果对人脸特征做二范数(L2)归一化,那么人脸特征则会分布在一个球面上(下右图),这样可以使用L2距离来度量。

图示为2维,实际在高维空间(图片来自 [6])
有了特征和度量标准之后,就可以考虑如何选择一个聚类算法了。现成的聚类算法包括K-Means,Spectral, DBSCAN, Hierarchical Agglomerative Clustering (HAC), Rank Order等以及它们的变种。利用这些方法聚类之后,将每一类中的样本分配相同的标签,不同的类分配不同的标签,就可以用来充当训练集了。
到此为止,似乎已经可以顺利地完成这个任务了。然而

使用20万张图提取特征之后来测试一下这些聚类算法,K-Means花了10分钟,HAC花了5.7小时,DBSCAN花了6.9小时, Spectral花了12小时。若使用60万张图片提取的特征来做聚类,K-Means超内存了,HAC花了61小时,DBSCAN花了80小时,Spectral跑到天荒地老之后也甩了一句超内存。当图片数量增加到140万的时候,几乎所有的聚类算法都挂了。

K-Means, Spectral, HAC等传统聚类方法的问题主要在于以下方面:
(a) 聚类算法具有较高的时间复杂度。例如,K-Means是O(NKT),Spectral是O(N^3),HAC是O(N^2)。
(b) 通常认为数据分布服从某些简单的假设。例如,K-Means假设数据类内具有球状的分布 [2],并且每一类具有相同的方差(Ariance),以及不同的类具有相同的先验概率。然而对于大规模人脸聚类,无标注数据通常来源于开放的场景(in-the-wild),数据内部的结构比较复杂,难以一致地服从这些假设。例如,我们期望数据长这样(如下左图):
(c) 通常使用某种特定的Metric。例如上述提及的Cosine Similarity和L2距离。同样,对于复杂的数据结构,衡量两个样本是否属于同一类,单纯靠样本之间的局部相似度是不够的,这个metric需要融合更多信息。
(d) 缺乏较好的离群值(Outliers)控制机制。Outliers来源于人脸识别模型对难样本的Embedding误差,以及观测到的数据不完整。尽管部分聚类算法例如DBSCAN理论上对Outliers鲁棒,但从其实际表现来讲这个问题远没有得到解决。

有监督的Metric
终于可以说说自己的工作了。我们被ECCV2018接收的一篇论文(Consensus-Driven Propagation in Massive Unlabeled Data for FaceRecognition),简称CDP [1],尝试解决上述这些问题中的一部分。我们提出了一种有监督的Metric用于人脸聚类,来部分解决无标注数据内部结构复杂、依赖特定Metric、缺乏Outlier控制的问题,顺便还解决了一下时间复杂度的问题(CDP做到了线性复杂度),当然性能也提升了一大截。
介绍方法之前我们先来介绍一下Affinity Graph。Graph在半监督学习和聚类上经常出现。Affinity Graph的节点是数据样本,边代表数据之间的相似度。一种常见的Affinity Graph是KNN Graph,即对所有样本搜索K近邻之后将样本与其近邻连接起来得到。我们的方法CDP基于KNN Graph来构建数据的结构。
CDP本质是学习一个Metric,也就是对样本对(Pairs)进行判断。如下图,CDP首先使用多个人脸识别模型构建成一个委员会(Committee), Committee中每个成员对基础模型中相连的Pairs提供包括关系(是否是Neighbor)、相似度、局部结构等信息,然后使用一个多层感知机(MLP)来整合这些信息并作出预测(即这个Pair是否是同一个人)。
这个过程可以类比成一个投票的过程,Committee负责考察一个候选人(Pair)的各方面信息,将信息汇总给MLP进行决定。最后将所有的Positive Pairs组成一个新的Graph称为Consensus-driven Graph。在此Graph上使用简单的连通域搜索并动态剪枝即可快速得到聚类。由于MLP需要使用一部分有标签的数据来训练得到,所以CDP是一种基于有监督的Metric的聚类方法。

CDP框架
接下来就是激fei动chang人wu心liao的结果分析了。
在复杂度上,CDP由于只需要探索局部结构,因此除了KNN搜索之外,聚类部分的复杂度是接近线性的。在20万数据上,不计入KNN搜索(依赖别的库)的时间的话,CDP单模型的耗时是7.7秒,多模型的耗时是100秒。在140万数据上,CDP单模型的耗时是48秒,多模型的耗时是585秒。试验结果上看时间复杂度甚至低于线性(小于7倍)。
在聚类结果上,例如对20万数据聚类,即使使用单模型也达到了89%的fsCore,多模型可以达到95.8%,强于大部分传统聚类算法。各种聚类算法运行时间和性能测试见GitHub。
我们的实验中使用CDP聚类后的数据加入人脸识别模型的训练之后,可以让模型达到接近全监督(使用Ground Truth标签)的结果。如下图所示:
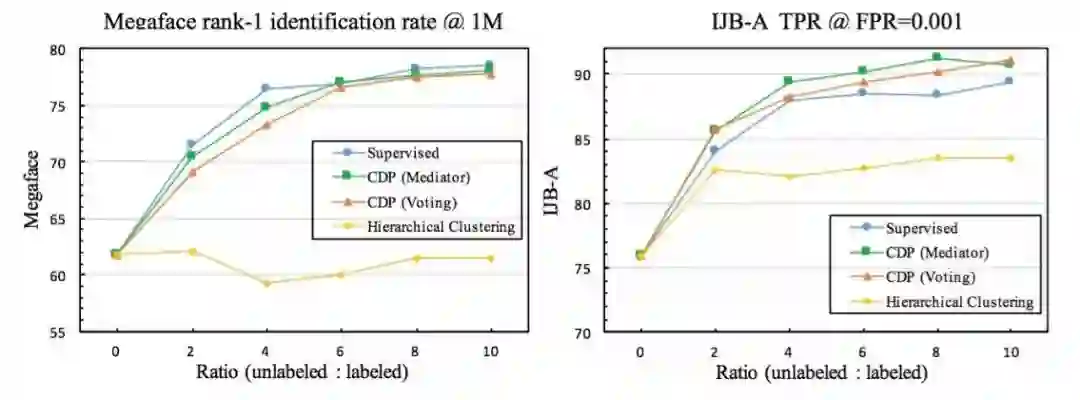
在两个测试集(Benchmark)上,随着数据的增多,用CDP聚类结果训练的人脸模型性能的增长接近全监督模型(所有数据都使用Groundtruth标注)。有趣的是在IJB-A上我们的结果超过了全监督模型,原因可能是训练集的Ground Truth标签会有一些噪声(Noise),例如误标注,导致全监督模型在IJB-A的某些测试样例上表现不佳。
下图是切换不同的CNN模型结构后的结果:

聚类后的部分结果如下图所示:

我们发现CDP还可以用来做数据和标签清理(Denoise)。例如一个标注好的数据集可能有一些标错的样本,或者非常低质量的图片,可以使用CDP来找到这些图并舍弃。如下图:

每一组人脸在原始标注中属于同一个人,左上角数字是CDP分配的标签,红框中的样本为CDP丢弃的样本,包括:1. 被错误标注进该类,实际是一个孤立点的样本。2. 低质量图片,包括过度模糊、卡通等。
在这篇工作中我们发现,基于学习的Metric能基于更多的有效信息进行判断,会比手动设计的Metric更擅长解决比较复杂的数据分布。另外,这种类似多模型的投票的方式在鲁棒性上带来了很大提升,这样可以从无标签数据中发掘出更多的难样本。
代码链接:
https://github.com/XiaohangZhan/cdp,欢迎watch/star/fork以及交流。
有监督的聚类算法
CDP属于一种自下而上(Bottomup)的方法,因此只能感知局部的数据结构。然而感知全局的数据结构对于聚类更为重要,为此,我们最近提出了一种自上而下(Top Down)的有监督聚类方法,能自动学习根据数据的结构进行聚类,更加充分地解决上述传统聚类的问题,不过暂时需要保密。有兴趣的朋友可以持续关注商汤公众号,加商汤君微信(sensetime888)沟通交流,添加微信请备注“学术交流”。
References:
[1] X. Zhan, Z. Liu, J. Yan, D. Lin, and C.C. Loy. Consensus-driven propagation in massive unlabeled data for facerecognition. In European Conference on Computer Vision (ECCV), September2018.
[2] A. K. Jain. Data clustering: 50 yearsbeyond k-means. Pattern recognition letters, 31(8):651–666, 2010. 2
[3] Y. Sun, X. Wang, and X. Tang."Deep learning face representation from predicting 10,000 classes."in Proceedings of the IEEE conference on computer vision and patternrecognition (CVPR). 2014.
[4] Otto, C., Wang, D., & Jain, A. K.(2018). Clustering millions of faces by identity. IEEE transactions onpattern analysis and machine intelligence (PAMI), 40(2), 289-303.
[5] Zhu, X. (2006). Semi-supervisedlearning literature survey. Computer Science, University ofWisconsin-Madison, 2(3), 4.
[6] Wang, H., Wang, Y., Zhou, Z., Ji, X.,Li, Z., Gong, D., ... & Liu, W. (2018). CosFace: Large margin cosine lossfor deep face recognition. in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition (CVPR). 2018.
注:本文部分图片来自网络




