PEGASUS:抽象式文本摘要的最新模型

文 / Peter J. Liu 和 Yao Zhao,软件工程师,Google Research
抽象式文本摘要是自然语言处理中最具挑战性的任务之一,需要理解长篇文章、压缩信息并生成概括性语言。
抽象式文本摘要
https://ai.googleblog.com/2016/08/text-summarization-with-tensorflow.html
试想一下,在学生时代,我们经常需要完成文献的阅读并进行简要概述(如撰写读书报告),以展现自己的阅读理解和写作能力。而现在,我们想要训练机器学习模型完成来此类任务。
目前的主流范例为序列到序列 (seq2seq) 学习,即让神经网络学习怎样将输入序列映射到输出序列。最初,人们使用循环神经网络开发 seq2seq 模型,但最近人们更倾向于使用 Transformer 编码器-解码器模型,因为此类模型在对摘要中的长序列里存在的依赖关系建模时更为高效。
Transformer 模型配合自监督预训练(如 BERT、GPT-2、RoBERTa、XLNet、ALBERT、T5、ELECTRA)作为通用语言学习生成框架,已展现出强大实力。经过多种语言任务微调之后,能够实现最前沿 (SOTA) 性能表现。在之前的研究中,预训练使用的自监督目标一定程度上无法同下游应用联系起来;我们想知道到,如果自监督目标能更精确地反映最终任务,是否能实现更好的性能?
在《PEGASUS:使用提取的空白句进行抽象式摘要预训练》(PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization)(将于 2020 年机器学习国际会议发表)中,我们设计了一个用于 Transformer 编码器-解码器模型的预训练自监督目标(称为 “空白句生成”,Gap-Sentence Generation),以提升抽象式摘要的微调性能,通过 12 个不同的摘要数据集,实现 SOTA 效果。我们将在 GitHub 发布训练代码和模型 Checkpoint,作为对论文的补充。
PEGASUS:使用提取的空白句进行抽象式摘要预训练
https://arxiv.org/abs/1912.08777GitHub
https://github.com/google-research/pegasus
用于摘要的自监督目标
我们的假设是:预训练自监督目标越接近于最终下游任务,微调性能越好。在 PEGASUS 预训练中,文档中移除了几个完整的句子,而模型的任务就是恢复这些句子。预训练的一个示例输入为包含缺失语句的文档,而输出由串联在一起的缺失语句组成。这项任务异常艰巨,即使人类也无法完成,所以我们也不指望模型能够完美处理这一任务。然而,这类极具挑战性的任务促使模型学习真实世界的语言和普遍事实,并学习如何提炼从全篇文档中获取的信息,以生成与微调摘要任务极其相似的结果。此自监督的优势在于,可按照文档数量创建任意数量的示例,无需人工标注,而这往往是纯监督系统的瓶颈所在。
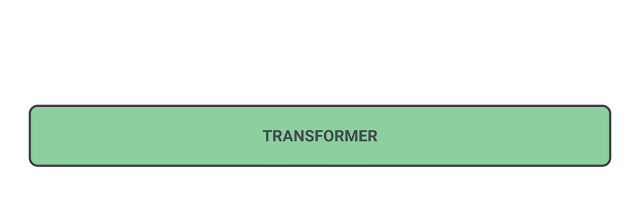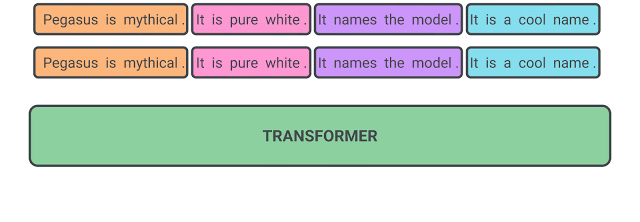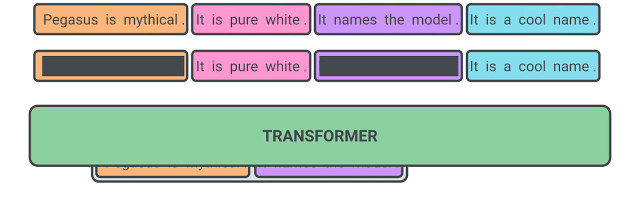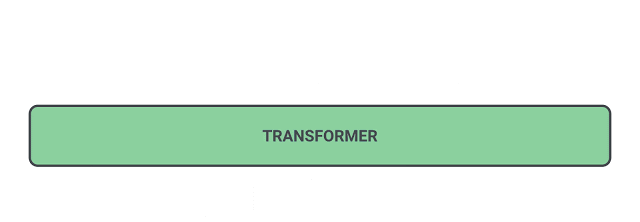
预训练过程中用于 PEGASUS 的自监督示例:该模型经过训练,旨在输出所有被掩盖的语句
我们发现,选择对“重要”语句进行掩盖效果最好,可使自监督示例的输出结果更接近于摘要。根据名为 ROUGE 的指标,我们通过寻找与文档剩余部分最为相似的语句,自动识别出重要语句。ROUGE 使用 0 到 100 的分数(ROUGE-1、ROUGE-2、ROUGE-L 为三种常见变体)计算 n-gram 重叠,从而计算出两篇文本的相似度。
与 T5 等近期其他方法类似,我们使用网络爬取的文档构建的特大型语料库预训练模型,然后使用 12 个公开下游抽象式摘要数据集微调模型,所得结果根据自动指标测量,已达顶尖水平,而使用的参数量仅为 T5 的 5%。我们特意选取种类多样的数据集,包括新闻报道、科学论文、专利、短篇小说、电子邮件、法律文书、操作指南,这表明该模型框架可适应多种话题。
使用少量示例进行微调
虽然 PEGASUS 在使用大型数据集进行训练时表现出优异性能,但我们惊讶地发现该模型无需通过大量示例进行微调,就能实现近乎顶级的性能:
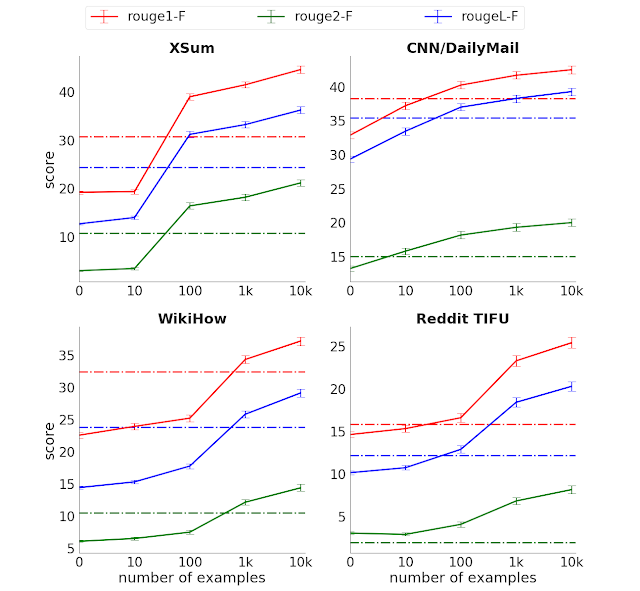
ROUGE 得分(三种变体,分数越高越好)对比四个所选摘要数据集中监督示例的数量虚线表示 Transformer 编码器-解码器没有预训练时,使用全监督的性能
仅使用 1000 个微调示例,该模型在大多数任务下展现出的性能就优于使用完整监督数据的强基线(Transformer 编码器-解码器),后者示例数在某些情况下甚至高出多个量级。这种“样本效率”可显著降低监督数据收集的规模和成本,从而大幅提升文本摘要模型的实用性,而就摘要来说,数据收集成本高昂。
生成的摘要堪比人工质量
虽然我们发现在模型开发过程中,ROUGE 等自动指标是非常实用的代理任务,但该指标仅能提供有限的信息,而无法展现全貌,如无法表现流畅性或与人工表现比较。针对于此,我们开展了人工评估,评分人需要比较模型生成的摘要和人工编写的摘要(评分者事先并不知道摘要来源)。这与 Turing 测试有几分相似。

在不透露摘要来源的前提下,评分人对模型生成的摘要与人工编写的摘要进行比较并打分,以上为示例图,评分者能够看到完整文本
我们使用 3 个不同的数据集进行了实验,发现相比于模型生成的摘要,人工编写的摘要并不总是评分人的首选。此外,仅使用 1000 个示例训练的模型表现几乎同样优秀。在使用研究透彻的 XSum 和 CNN/Dailymail 数据集后,模型仅使用 1000 个示例就达到了与人工无异的表现。这表明摘要无需再使用大型监督示例数据集,也可实现多种低成本用例。
XSum
https://tensorflow.google.cn/datasets/catalog/xsumCNN/Dailymail
https://tensorflow.google.cn/datasets/catalog/cnn_dailymail
理解能力测试:计算舰船数量
本文后附上了 XSum 数据集中的一篇示例文章,以及模型生成的抽象式摘要。此模型正确提取并改述了四艘经过命名的护卫舰(HMS Cumberland、HMS Campbeltown、HMS Chatham 和 HMS Cornwall),将其称为“四艘皇家海军护卫舰”,而通过提取式方法无法实现此类效果,因为“四”并未在文中任何位置出现。这是侥幸?还是模型可以计数?为查明产生这一结果的原因,我们采取的一种方法就是添加或移除舰船,观察计数是否有变化。
示例文章
https://www.bbc.com/news/uk-england-21326309
如下所示,舰船数量为 2 到 5 艘时,模型成功“计算”出了相应数量。然而,添加第六艘舰船时,“HMS Alphabet”模型错误将数量错算为“七”。由此可见,模型似乎已学会计算列表中的少量项目数量,虽然并未达到我们所期望的概括水平。但我们依然认为这种基础计数能力非常了不起,因为我们并未将此能力编程到模型中,也由此可以证明模型具有一定的“符号推理”能力。
PEGASUS 代码和模型发布
为支持该领域研究可持续进展,并确保成果可再现,我们会将 PEGASUS 代码和模型检查点发布在 GitHub 上。其中包括可用于调整 PEGASUS 的微调代码,以适应其他摘要数据集。
GitHub
https://github.com/google-research/pegasus
致谢
此项研究是 Jingqing Zhang、Yao Zhao、Mohammad Saleh 和 Peter J. Liu 通力合作的成果。感谢 T5 和 Google 新闻团队提供 PEGASUS 预训练所用的数据集。
以下是模型的一个示例,了解更多请阅读原文:
-
原文
https://ai.googleblog.com/2020/06/pegasus-state-of-art-model-for.html
了解更多请点击 “阅读原文” 访问 Github。
🌟将我们设为星标
第一时间收到更新提醒
不再错过精彩内容!

分享 💬 点赞 👍 在看 ❤️
以“三连”行动支持优质内容!


