详解U-Net中的重叠-切片(Overlap-tile)

极市导读
本文先对Overlap-tile的原理以及在U-Net中的使用进行说明,然后结合源码对该策略的实现进行解析,内容包括随机切片、镜像填充后按序切片以及将切片重构成图像。 >>极市双11现金福利,前往文末即可查看惊喜!
全文大纲:
1.Overlap-tile在U-Net中的使用
2.随机切片
3.镜像填充
4.按序切片
5.将切片重构成图像
6.总结
前言
最开始接触 U-Net 的时候并不知道原作使用了 Overlap-tile 这种策略,因此当时不太理解为何网络结构要设计成非对称形式,即上采样得到的特征图尺寸与对应层在下采样时的尺寸不一致。
另外发现,这种策略可用于许多场景,特别是当 数据量较少 或者 不适合对原图进行缩放时尤其适用(缩放通常使用插值算法,主流的插值算法如双线性插值具有低通滤波的性质,会使得图像的高频分量受损,从而造成图像轮廓和边缘等细节损失,可能对模型学习有一定影响),同时它还能起到为目标区域提供上下文信息的作用。
本文先对这种策略的原理以及在U-Net中的使用进行说明,然后结合源码对该策略的实现进行解析,内容包括随机切片、镜像填充后按序切片以及将切片重构成图像。
1.Overlap-tile在U-Net中的使用
先来对Overlap-tile策略的原理及其在U-Net中的使用做个介绍,让大家对其有个初步印象和基本理解。
熟悉U-Net结构的炼丹者们肯定清楚,它并不是一个完全对称的结构。也就是说,某一层特征图下采样后再上采样回来到对应层时,其尺寸会发生变化,比原来的小,原因在于U-Net使用的是不带padding的3x3卷积(valid卷积),每次经过这样的一个卷积就会使得特征图尺寸减小2x2。
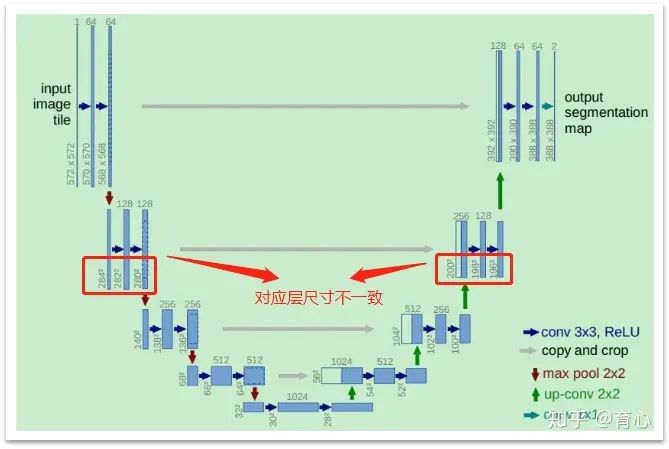
(U-Net)
显然,如果直接输入原图,那么最后输出的尺寸会比原图小。如果我们希望得到和输入一致的尺寸,会怎么做?
最直接的是对输出结果再进行一次上采样,可以使用插值或者转置卷积的方法,若使用插值,由于其是不可学习的,会带来一定的误差;而使用转置卷积的话,又会增加参数量,并且模型也不一定能学习得好。
另外一种方法就是将U-Net中的valid卷积改为same卷积,即使用padding,这样每次3x3卷积就不会改变特征图的尺寸了,最终上采样回来的尺寸就能够和输入一致了。但是,padding是会引入误差的,而且模型越深层得到的feature map抽象程度越高,受到padding的影响会呈累积效应。
上述方法都体现出明显的不足之处,那么有没有更好的方法呢?我们来看看U-Net中的Overlap-tile是怎么做的。
做法其实很简单,就是在输入网络前对图像进行padding,使得最终的输出尺寸与原图一致。特别的是,这个padding是镜像padding,这样,在预测边界区域的时候就提供了上下文信息。
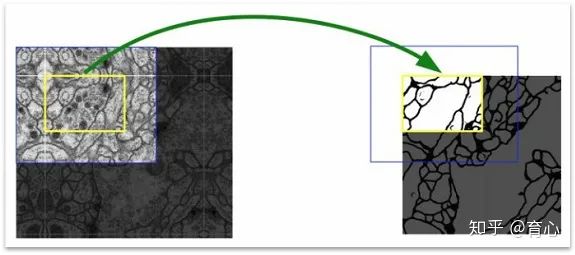
(Overlap-tile)
上图左边是对原图进行镜像padding后的效果,黄框是原图的左上角部分,padding后其四周也获得了上下文信息,与图像内部的其它区域有类似效果。
Overlap-tile策略可搭配patch(图像分块)一起使用。当内存资源有限从而无法对整张大图进行预测时,可以对图像先进行镜像padding,然后按序将padding后的图像分割成固定大小的patch。这样,能够实现对任意大的图像进行无缝分割,同时每个图像块也获得了相应的上下文信息。另外,在数据量较少的情况下,每张图像都被分割成多个patch,相当于起到了扩充数据量的作用。更重要的是,这种策略不需要对原图进行缩放,每个位置的像素值与原图保持一致,不会因为缩放而带来误差。
2.随机切片
随机切片是在图像内部随机选取patch中心,然后将图像切成固定数量的patch。
以下示例是对单张图像及对应的掩膜(mask)做随机切片。
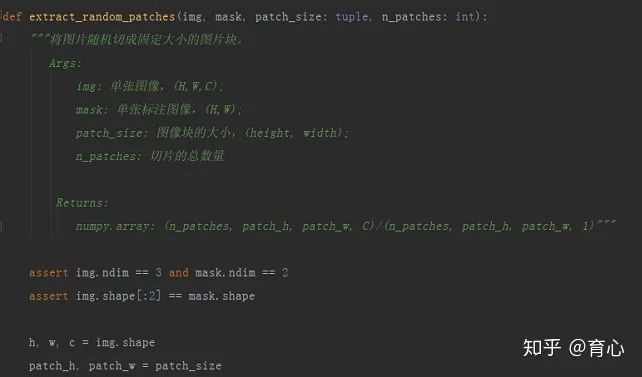
(随机切片 i)
patch中心位置根据其尺寸在图像内部随机选取,确定中心位置后,再根据各边长就可以确定patch的左上和右下两个顶点坐标。
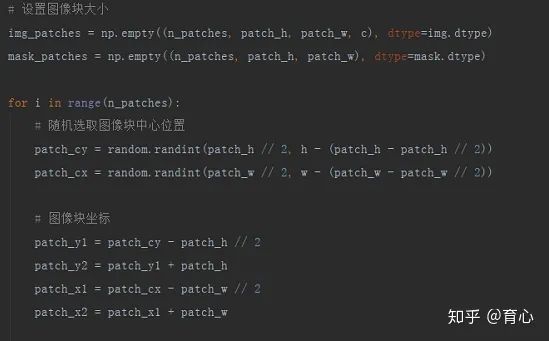
(随机切片 ii)
最后从原图中取出对应位置的区域即可。
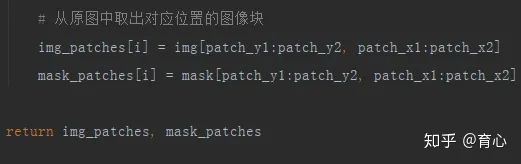
(随机切片 iii)
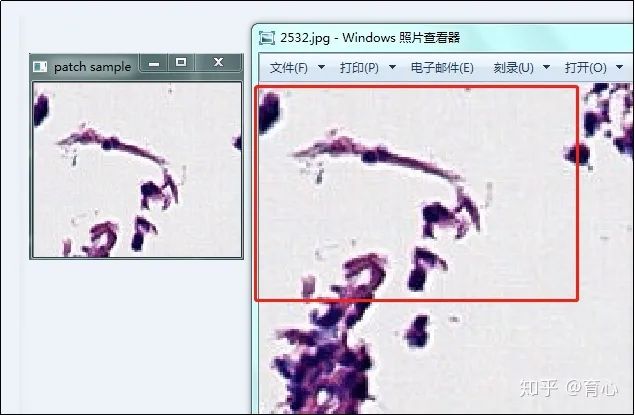
随机切片效果(左:切片得到的图像块;右:原图对应区域)
3.镜像填充
对原图进行镜像填充,能够使模型对边界区域进行预测时获得上下文信息。下图蓝框部分是原图的左上角部分,镜像填充后,得到红框部分。
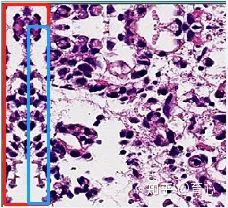
(镜像填充效果)
镜像填充后会进行按序切片,在切片时,各patch之间可以设定一个固定的间隔,这样能够避免过份重叠。至于各边需要填充多少长度,可以基于以下两种方式来决定:
i). 填充后,各边都能恰好切出整数个patch(最后不会剩余一点长度不足一个patch);
ii). 提前计算输入输出之间的尺寸差,使得padding后输出与输入尺寸保持一致。
下面就第i)种方式进行源码解析。若有多张不同尺寸的图片,那么就一张张独立处理;否则,可以组成一个批次进行处理。
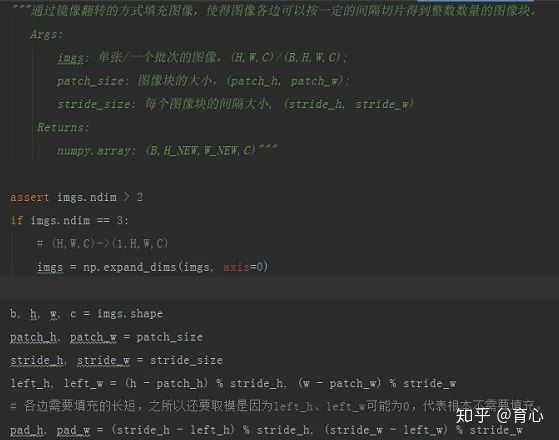
(镜像填充 i)
先在竖直方向上进行填充,填充后,将原图置于中间,顶部和底部使用原图的镜像进行填充。
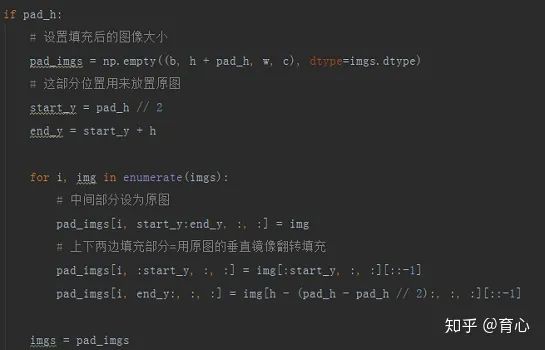
(镜像填充 ii )
然后在水平方向上进行填充,同样地,将填充前的图像置于中间,左右两边剩余部分使用填充前图像的镜像进行填充。
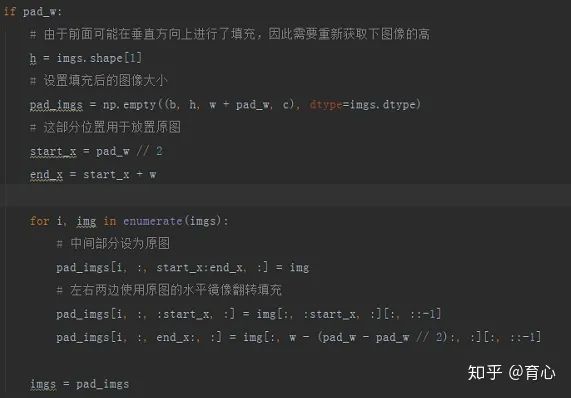
(镜像填充 iii)
4.按序切片
按序切片就是从图像的左上方开始,按照一定间隔依次将图像切成一个个小的图像块,直至图像
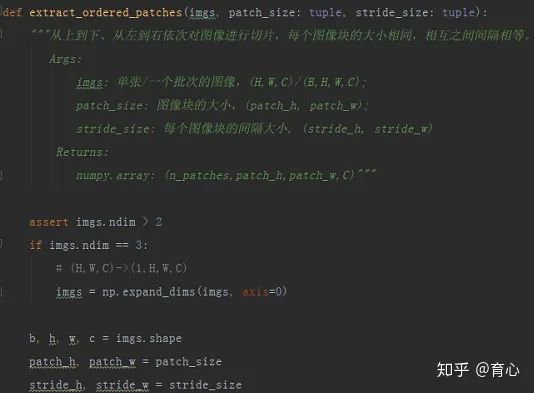
(按序切片 i)
注意,各切片之间的间隔是可以小于切片边长的,这就代表各切片可能存在重叠部分。
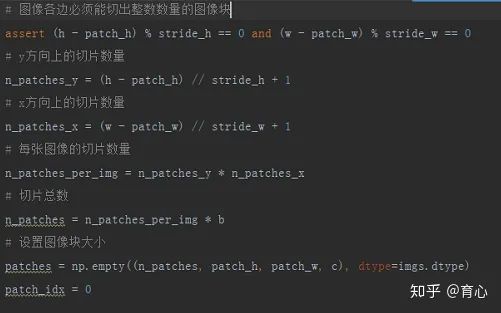
(按序切片 ii)
每张图切出相同数量相同大小的切片,计算出各个切片的位置,从图中取出对应的部分就得到各切片。

(按序切片 iii)
5.将切片重构成图像
将图像切片后,模型是对切片进行预测的,那么通常我们需要将这些切片的预测结果重新组合成整张图像对应的预测结果以方便评估和展示。
预测结果的重组与切片重组成图像的原理类似,这里就切片重组进行源码解析。
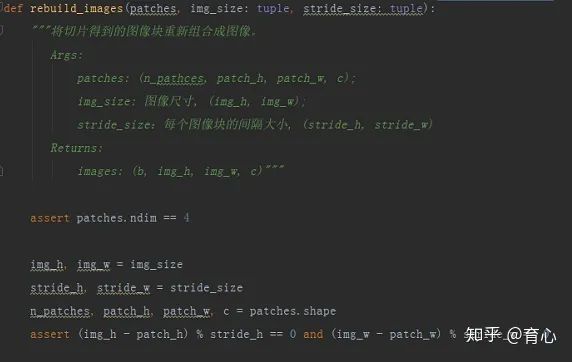
(切片重组 i)
在上一节提到,切片之间可能存在重叠部分,而重叠部分的像素值,我们通常取平均值。对于切片重构图像来说,取平均后的像素值与原图相同;而对于切片预测结果重组成整图预测结果来说,求平均相当于对多次预测所得的概率求均值作为最终预测结果。
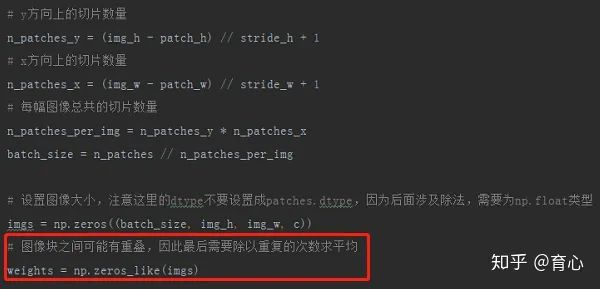
(切片重组 ii)
注意,并不是将切片直接放入图像对应位置,而是使用求和(下图中 img +=、weights +=),就是因为切片之间可能存在重叠的部分,我们需要对这些部分求均值。
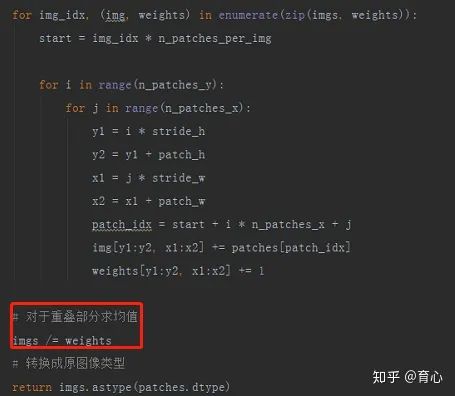
(切片重组 iii)
如果切片前做了padding,那么重构后的图像尺寸对应的是padding后的尺寸,因此我们还要裁出原图。我们在padding的时候,原图是放中间的,那么记下之前padding的长度就很容易计算出原图位置了。
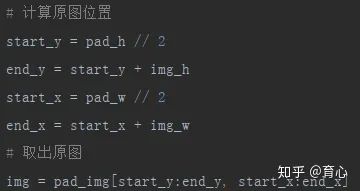
(裁剪出原图)
6.总结
如本文所述,Overlap-tile带来的好处有许多:不需要对图像进行缩放从而避免图像细节损失、能够为边界区域提供上下文信息、在数据量较少时充当数据扩充的手段。但是,在炼丹的世界里,实际效果如何还得“炼一炼”才知道,感兴趣的炼丹师可以在训练中尝试下这种策略。
作者简介
CW,广东深圳人,毕业于中山大学(SYSU)数据科学与计算机学院,毕业后就业于腾讯计算机系统有限公司技术工程与事业群(TEG)从事Devops工作,期间在AI LAB实习过,实操过道路交通元素与医疗病例图像分割、视频实时人脸检测与表情识别、OCR等项目。目前也有在一些自媒体平台上参与外包项目的研发工作,项目专注于CV领域(传统图像处理与深度学习方向均有)。
推荐阅读