基于GRU和am-softmax的句子相似度模型 | 附代码实现

作者丨苏剑林
单位丨广州火焰信息科技有限公司
研究方向丨NLP,神经网络
个人主页丨kexue.fm
前言:搞计算机视觉的朋友会知道,am-softmax 是人脸识别中的成果。所以这篇文章就是借鉴人脸识别的做法来做句子相似度模型,顺便介绍在 Keras 下各种 margin loss 的写法。
背景
细想之下会发现,句子相似度与人脸识别有很多的相似之处。
已有的做法
在我搜索到的资料中,深度学习做句子相似度模型,就只有两种做法:一是输入一对句子,然后输出一个 0/1 标签代表相似程度,也就是视为一个二分类问题,比如 Learning Text Similarity with Siamese Recurrent Networks [1] 中的模型是这样的:

▲ 将句子相似度视为二分类模型
包括今年拍拍贷的“魔镜杯”,也是这种格式。另外一种做法是输入一个三元组“(句子 A,跟 A 相似的句子,跟 A 不相似的句子)”,然后用 triplet loss 的做法解决,比如文章 Applying Deep Learning To Answer Selection: A Study And An Open Task [2] 中的做法。
这两种做法其实也可以看成是一种,本质上是一样的,只不过 loss 和训练方法有所差别。但是,这两种方法却都有一个很严重的问题:负样本采样严重不足,导致效果提升非常慢。
使用场景
我们不妨回顾一下我们使用句子相似度模型的场景。一般来说,我们事先存好了很多 FAQ 对,也就是“问题-答案”的语料对。当我们碰到一个新问题时,我们就需要比较这个新问题与原来数据库中所有问题的相似度,找出最相似的那个,根据相似度和阈值决定是否做出回答。
注意,这里边包含了两个要素,第一是“所有”,理论上来说,我们跟数据库中的所有问题都比较一次,然后找出最相似的;第二是“阈值”,我们也不知道新问题在数据库中是否有答案,因此这个阈值决定是我们是否要做出回应。如果不管三七二十一都取 top 1 来作答,那体验也会很差的。
我们先来关心“所有”。“所有”意味着在训练的时候,对于每个句子,除了仅有的几个相似句是正样本,其它所有句子都应该作为负样本。但如果用前面的做法,其实我们很难完整地采样所有的负样本出来,而且就算可以做到,训练时间也非常长。这就是前面说的弊端所在。
来自人脸的帮助
我一直觉得,在机器学习领域中,其实不应该过分“划清界线”,比如有些读者觉得自己是做 NLP 的,于是就不碰图像,反过来做图像的,看到 NLP 的就远而避之。事实上,整个机器学习领域之间的沟壑并没有那么大,很多东西的本质都是一样的,只是场景不同而已。比如,所谓的句子相似度模型,其实几乎就完全对应于人脸识别任务,而人脸识别目前已经相当成熟了,显然我们是可以借鉴的。
先不说模型,我们来想象一下人脸识别的使用场景。比如公司内可以用人脸识别打卡,当有了一个人脸识别模型后,我们事先会存好一些公司员工的人脸照片,然后每天上班时,先拍一张员工的人脸照(实时拍摄,显然不会跟已经存好的照片完全吻合),然后要判断他/她是不是公司的员工,如果是,还要确定是哪一位员工。
试想一下,将上面的场景中,“人脸”换成“句子”,是不是就是句子相似度模型的使用场景呢?
显然,句子相似度模型可以是说 NLP 中的人脸识别了。
模型
句子相似度和人脸识别在各方面都很相似:从模型的使用到构建乃至数据集的量级上,都是如此地接近。所以,几乎人脸识别的一切模型和技巧,都可以用在句子相似度模型上。
作为分类问题
事实上,前面说的 triplet loss,也是训练人脸识别模型的标准方法之一。triplet loss 本身没有错,反而,如果能精调参数并且重新训练,它效果还可能非常好。只是在很多情况下,它实在是太低效了。当前,更标准的做法是:视为一个多分类问题。
比如,假设训练集里边有 10 万个不同的人,每个人 5 张人脸图,那么就有 50 万张训练图片了。然后我们训练一个 CNN 模型,对图片提取特征,并构建一个 10 万分类的模型。没错,就是跟 mnist 一样的分类问题,只不过这时候分类数目大得多,有多少个不同的人就有多少类。那么,句子相似度问题也可以这样做,可以将训练集划分为很多组“同义句”,然后有多少组就有多少类,也将句子相似度问题当作分类问题来做。
注意,这仅仅是训练,最后训练出来的分类模型可能毫无用处。这不难想象,我们可以用已有的人脸数据库来训练一个人脸识别模型,但我们的使用场景可能是公司打卡,也就是说要识别的人脸是公司内部的员工脸,他们显然不会在公开的人脸数据库中。所以分类模型是没有意义的,真正有意义的是分类之前的特征提取模型。比如,一个典型的 CNN 分类模型可以简写为两步:

其中 x 是输入,p 是每一类的概率输出,这里的 softmax 不用加偏置项。作为一个分类问题训练时,我们输出的是人脸图片 x 和对应的 one hot 标签 p,但是在使用的时候,我们不用整个模型,我们只用 CNN(x) 这部分,这部分负责将每一张人脸图片转化为一个固定长度的向量。
有了这个转化模型(编码器,encoder),不管什么场景下,我们都可以对新人脸进行编码,然后转化为这些编码向量之间的比较,从而就不依赖原来的分类模型。所以,分类模型是一个训练方案,一旦训练完成,它就功成身退了,留下的是编码模型。
分类与排序
这样就可以了?还没有。前面说到,我们真正要做的是一个特征提取模型(编码器),并且用分类模型作为训练方案,而最后使用的方法是对特征提取模型的特征进行对比排序。
我们要做特征排序,但是借助分类模型训练,这两者等价吗?
答案是:相关但不等价。分类问题是怎么做的呢?直观来看,它是选定了一些类别中心,然后说:每个样本都属于距离它最近的中心的那一类。
当然这些类别中心也是训练出来的,而这里的“距离”可以有多种可能性,比如欧式距离、cos 值、内积都可以,一般的 softmax 对应的就是内积。分类问题的这种做法,就导致了下面的可能的分类结果:
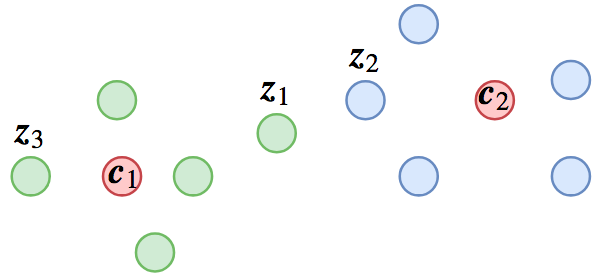
▲ 一种可能的分类结果,其中红色点代表类别中心,其他点代表样本
这个分类结果有什么问题呢?我们留意图上的 z1,z2,z3 三个样本,其中 z1,z3 距离 c1 最近,所以它们是类别 1 的,z2 距离 c2 最近,所以它是类别 2 的,假设这个分类没有错,也就是说 z1,z3 它们可能是同义句,z2 跟它们不是同义的,又或者 z1,z3 是同一个人的人脸图,而 z2 则是另一个人的。
从分类角度,这结果很合理,但我们已经说过,我们最终不要分类模型,我们需要特征之间的比较。这样问题就很明显了:z1,z2 距离这么近,却不是同一类的,z1 跟 z3 距离这么远,却是同一类的。如果我们用特征排序的方法给 z1 找一个同义句,那么就会找到 z2 而不是 z3。
Loss
上面说的,就是分类与排序的不等价性,当然,从图上也可以看出,尽管不完全等价,分类模型还是给了大部分的特征一个合理的位置分布,只是在边缘附近的特征,就可能出现问题。
Margin Softmax
可以想象,问题出现在分类边界附近的那些点上面,而出现问题的原因,其实就是分类条件过于宽松,如果加强一下分类条件,就可以提升排序效果了,比如改为:每个样本与它所属类的距离,必须小于它跟其他类的距离的 1/2。
原来我们只需要小于它与其他类的距离,现在不但要这样,还要小于其它距离的一半,显然条件加强了,而前一个图所示的分类结果就不够好了,因为虽然如图有 ‖z1−c1‖<‖z1−c2‖,但是没有做到 ‖z1−c1‖<1/2‖z1−c2‖,所以还需要进一步优化 loss。
假如按照这个条件训练完成后,我们可以想象,这时候 z1,z2 的距离就被拉大了,而 z1,z3 的距离就被缩小了,这正是我们所希望的结果:增大类间距离,缩小类内距离。
事实上,上面所说的方案,可以说就是人脸识别中很著名的方案 l-softmax [3]。人脸识别领域中,很多类似的 loss 被提出来,它们都是针对上述分类问题与排序问题的不等价性设计出来的,比如 a-softmax、am-softmax、aam-softmax等,它们都统称 margin softmax。而且,不仅有 margin softmax,还有 center loss,还有 triplet loss 的一些改进版本等等。
am-softmax
我不是做图像的,因此人脸识别的故事我就讲不下去了,还是回到本文的正题。上面说到人脸识别不能用纯粹的 softmax 分类,必须要用 margin softmax,而因为句子相似度模型和人脸识别模型的相似性,告诉我们句子相似度模型也是需要 margin softmax 的。总而言之,至少要挑一个 margin softmax 来实现呀。
其中,效果比较好而最容易实现的方案,当数 am-softmax,本文就以它为例子来介绍这一类 margin softmax 的实现方案,最终实现一个句子相似度模型。
am-softmax的做法其实很简单,原来 softmax 是 p=softmax(zW),设:

那么 softmax 可以重新写为:
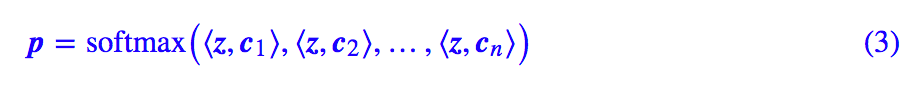
然后 loss 取交叉熵,也就是:
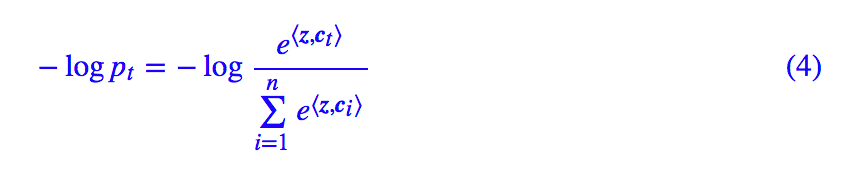
t 为目标标签。而 am-softmax 做了两件事情:
1. 将 z 和 ci 都做 l2 归一化,也就是说,内积变成了 cos 值;
2. 对目标 cos 值减去一个正数 m,然后做比例缩放 s。即 loss 变为:
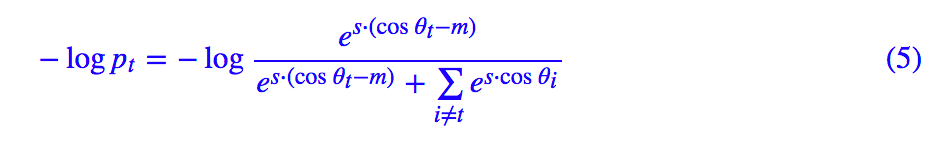
其中 θi 代表 z,ci 的夹角。在 am-softmax 原论文中,所使用的是 s=30,m=0.35。
从 am-softmax 中,我们可以看到针对前面所提的问题的解决方案了。首先,s 的存在是必要的,因为 cos 的范围是 [−1,1],需要做好比例缩放,才允许 pt 能足够接近于 1(有必要的话)。当然,s 并不改变相对大小,因此这不是核心改变,核心是原来应该是 cosθt 的地方,换成了 cosθt−m。
随心所欲地margin
前面提到,从分类问题到特征排序的不完全等价性,可以通过加强分类条件来解决,所谓加强,其实意思很简单,就是用一个新的函数 ψ(θt) 来代替 cosθt,只要:

我们都可以认为是一种加强,而 am-softmax 则是取 ψ(θt)=cosθt−m,这估计是满足上式的最简单粗暴的方案了(幸好,它效果也很好)。
理解了这种思想之后,其实我们可以构造各种各样的 ψ(θt) 了,毕竟理论上满足 (6) 式的都可以选取。前面我们也提到了 l-softmax 和 a-softmax,它们相当于选择了 ψ(θt)=cosmθt,其中 m 是一个整数。
但我们知道,cosmθt<cosθt 并非总是成立的,所以论文中基于 cosmθt 构造了一个分段函数出来,显得特别麻烦,而且也使得模型极难收敛。事实上,我试验过下面的方式:

结果媲美 am-softmax(在句子相似度任务上)。所以,上述可以作为 l-softmax 和 a-softmax 的一个简单的替代品了吧,我称为 simpler-a-softmax,有兴趣的读者可以试试在人脸上的效果。
实现
最后介绍本文对这些 loss 在 Keras 下的实现。测试环境的 Python 版本为 2.7,Keras 版本为 2.1.5,TensorFlow 后端。
基本实现
用最基本的方式实现 am-softmax 并不困难,比如:
from keras.models import Model
from keras.layers import *
import keras.backend as K
from keras.constraints import unit_norm
x_in = Input(shape=(maxlen,))
x_embedded = Embedding(len(chars)+2,
word_size)(x_in)
x = CuDNNGRU(word_size)(x_embedded)
x = Lambda(lambda x: K.l2_normalize(x, 1))(x)
pred = Dense(num_train,
use_bias=False,
kernel_constraint=unit_norm())(x)
encoder = Model(x_in, x) # 最终的目的是要得到一个编码器
model = Model(x_in, pred) # 用分类问题做训练
def amsoftmax_loss(y_true, y_pred, scale=30, margin=0.35):
y_pred = y_true * (y_pred - margin) + (1 - y_true) * y_pred
y_pred *= scale
return K.categorical_crossentropy(y_true, y_pred, from_logits=True)
model.compile(loss=amsoftmax_loss,
optimizer='adam',
metrics=['accuracy'])
Sparse版实现
上面的代码并不难理解,主要基于 y_true 是目标的 one hot 输入,这样一来,可以通过普通的乘法来取出目标的 cos 值,减去 margin 后再补回其他部分。
如果仅仅是玩个 mnist 这样的 10 分类,那么上述代码完全足够了。但在人脸识别或句子相似度场景,我们面对的事实上是数万分类甚至数十万的分类,这种情况下如果还是用 one ho t输入,就显得非常消耗内存了(主要是准备数据时也麻烦一些)。
理想情况下,我们希望 y_true 只要输入对应分类的整数id。对于普通的交叉熵,Keras 也提供了 sparse_categorical_crossentropy 的方案,便是应对这种需求,那么 am-softmax 能不能写个 Sparse 版出来呢?
一种比较简单的写法是,将转换 one hot 的过程写入到 loss 中,比如:
def sparse_amsoftmax_loss(y_true, y_pred, scale=30, margin=0.35):
y_true = K.cast(y_true[:, 0], 'int32') # 保证y_true的shape=(None,), dtype=int32
y_true = K.one_hot(y_true, K.int_shape(y_pred)[-1]) # 转换为one hot
y_pred = y_true * (y_pred - margin) + (1 - y_true) * y_pred
y_pred *= scale
return K.categorical_crossentropy(y_true, y_pred, from_logits=True)
这样确实能达成目的,但只不过对问题进行了转嫁,并没有真正跳过转 one hot。我们可以用 TensorFlow 的 gather_nd 函数,来实现真正地跳过转 one hot 的过程,下面是参考的代码:
def sparse_amsoftmax_loss(y_true, y_pred, scale=30, margin=0.35):
y_true = K.expand_dims(y_true[:, 0], 1) # 保证y_true的shape=(None, 1)
y_true = K.cast(y_true, 'int32') # 保证y_true的dtype=int32
batch_idxs = K.arange(0, K.shape(y_true)[0])
batch_idxs = K.expand_dims(batch_idxs, 1)
idxs = K.concatenate([batch_idxs, y_true], 1)
y_true_pred = K.tf.gather_nd(y_pred, idxs) # 目标特征,用tf.gather_nd提取出来
y_true_pred = K.expand_dims(y_true_pred, 1)
y_true_pred_margin = y_true_pred - margin # 减去margin
_Z = K.concatenate([y_pred, y_true_pred_margin], 1) # 为计算配分函数
_Z = _Z * scale # 缩放结果,主要因为pred是cos值,范围[-1, 1]
logZ = K.logsumexp(_Z, 1, keepdims=True) # 用logsumexp,保证梯度不消失
logZ = logZ + K.log(1 - K.exp(scale * y_true_pred - logZ)) # 从Z中减去exp(scale * y_true_pred)
return - y_true_pred_margin * scale + logZ这个代码会比前一个带 one hot 的代码要略微快一些。实现的关键是用 tf.gather_nd 把目标列提取出来,然后用 logsumexp 计算对数配分函数,这估计是实现交叉熵的标准方法了。基于此,可以修改为其它形式的 margin softmax loss。现在就可以像 sparse_categorical_crossentropy 一样只输入类别 id 了,其它框架也可以参照着实现。
效果预览
一个完整的句子相似度模型可以在这里浏览:
https://github.com/bojone/margin-softmax/blob/master/sent_sim.py
这是一个基于字的模型,所用到的语料 tongyiju.csv 如图(语料不共享,需要运行的读者请自行按照格式准备语料):

▲ 句子相似度语料格式
其中前面的 id 表示句子组别,用 \t 隔开,同一组的句子可以认为都是同一句,不同组的句子则是非同义句。
训练结果:训练集的分类问题上,能达到 90%+ 的准确率,而验证集(evaluate 函数)上,几种 loss 的 top1、top5、top10 的准确率分别为(没有精细调参):
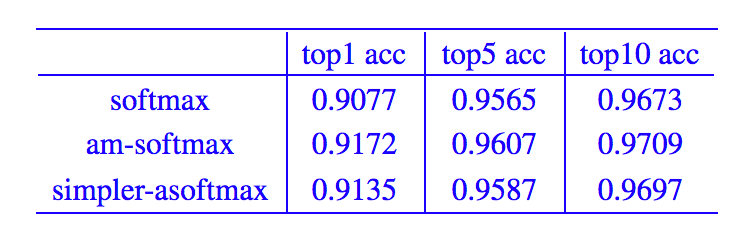
值得一提的是,evaluate 函数完全是按照真实的使用环境测试的,也就是说,验证集的每一个句子都没有出现过在训练集中,运行 evaluate 函数时,仅仅是在验证集内部进行排序,如果按相似度排序后的前 n 个句子中出现了输入句子的同义句,那么 top n 的命中数就加 1。
因此,这样看来,准确率是很可观的,能满足工程使用了。下面是随便挑几个匹配的例子:

结论
本文阐述了笔者对句子相似度模型的理解,认为它的最佳做法并非二分类,也并非 triplet loss,而是模仿人脸识别中的 margin loss 来做,这是能最快速提升效果的方案。当然,我并没有充分比较各种方法,仅仅是从我自己对人脸识别的粗浅了解中觉得应该是那样。欢迎读者测试并一同讨论。
参考文献
[1]. Paul Neculoiu, Maarten Versteegh, Mihai Rotaru: Learning Text Similarity with Siamese Recurrent Networks. Rep4NLP@ACL 2016: 148-157
[2]. Feng, Minwei, et al. "Applying deep learning to answer selection: A study and an open task." 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU). IEEE, 2015.
[3]. Liu W, Wen Y, Yu Z, et al. Large-Margin Softmax Loss for Convolutional Neural Networks[C]//Proceedings of The 33rd International Conference on Machine Learning. 2016: 507-516.

点击以下标题查看作者其他文章:

▲ 戳我查看招募详情

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看作者博客


