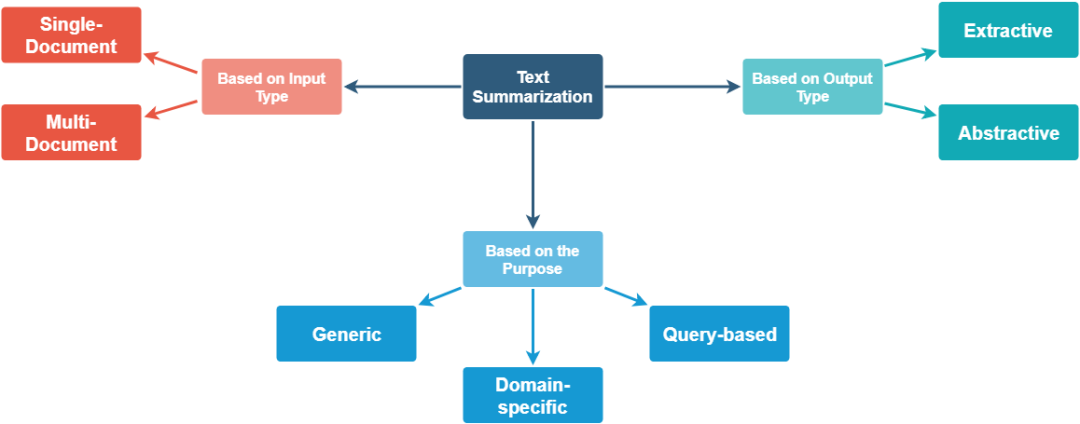
基于句子嵌入的无监督文本摘要(附代码实现)

©PaperWeekly· 作者|高开远
学校|上海交通大学
研究方向|自然语言处理

文本摘要是从一个或多个源中提取最重要信息,并为特定用户(或多个用户)和任务(或多个任务)生成简短版本的过程。 -- Advances in Automatic Text Summarization, 1999.
文本摘要对于人类来说是非常简单的,因为人类天生地具有理解自然语言的能力,并可以提取显著特征以使用自己的文字来总结文档的重点。但是,在当今世界中数据爆炸增长,缺乏人力和时间来解析数据,因此自动文本摘要方法至关重要,主要有以下几个原因:
自动摘要可以缩短文本阅读时间,提高效率;
当搜索我们所需要的文本时,有摘要可以更为容易查找到;
自动摘要提高了索引的效率;
相比于人力摘要,自动摘要更无偏;
个性化的摘要在问答系统中非常有用,因为它们提供了个性化的信息;
使用自动或半自动摘要系统使商业抽象服务能够增加它们处理的文本文档的数量。


Hi Jane,
Thank you for keeping me updated on this issue. I'm happy to hear that the issue got resolved after all and you can now use the app in its full functionality again.
Also many thanks for your suggestions. We hope to improve this feature in the future.
In case you experience any further problems with the app, please don't hesitate to contact me again.
Best regards,
John Doe
Customer Support
1600 Amphitheatre Parkway
Mountain View, CA
United States
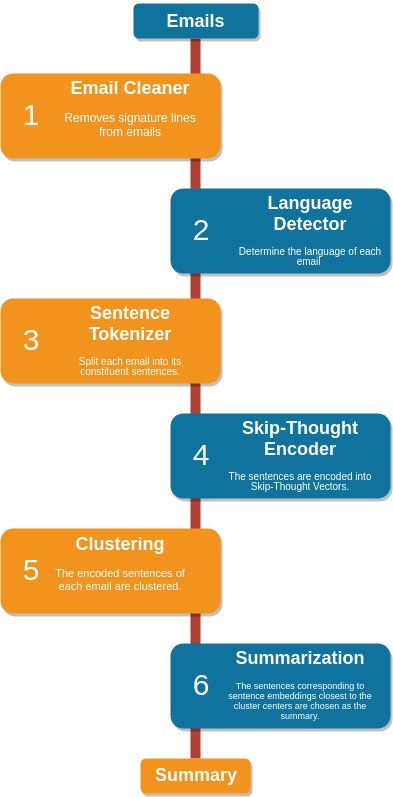
# clean()函数改写了上面github库中代码以清洗邮件
cleaned_email, _ = clean(email)
lines = cleaned_email.split('\n')
lines = [line for line in lines if line != '']
cleaned_email = ' '.join(lines)
from talon.signature.bruteforce import extract_signature
cleaned_email, _ = extract_signature(email)

from langdetect import detect
lang = detect(cleaned_email) # lang = 'en' for an English emailfrom nltk.tokenize import sent_tokenize
sentences = sent_tokenize(email, language = lang)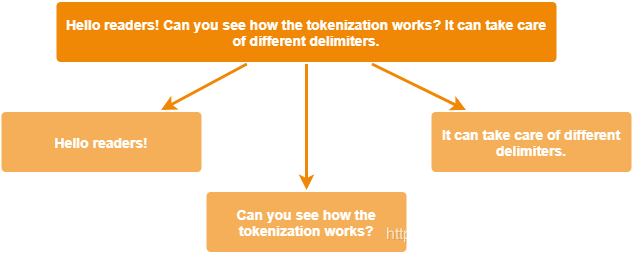
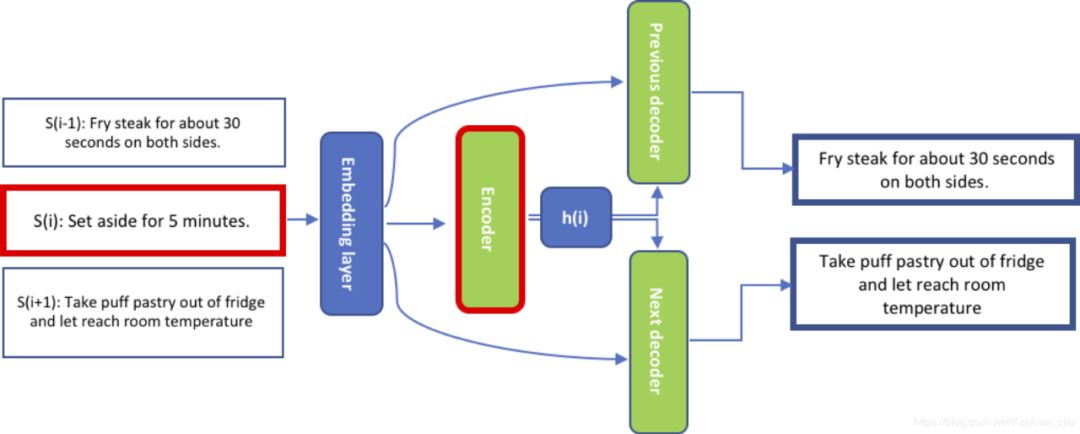
import skipthoughts
# 需要预先下载预训练模型
model = skipthoughts.load_model()
encoder = skipthoughts.Encoder(model)
encoded = encoder.encode(sentences)import numpy as np
from sklearn.cluster import KMeans
n_clusters = np.ceil(len(encoded)**0.5)
kmeans = KMeans(n_clusters=n_clusters)
kmeans = kmeans.fit(encoded)from sklearn.metrics import pairwise_distances_argmin_min
avg = []
for j in range(n_clusters):
idx = np.where(kmeans.labels_ == j)[0]
avg.append(np.mean(idx))
closest, _ = pairwise_distances_argmin_min(kmeans.cluster_centers_, encoded)
ordering = sorted(range(n_clusters), key=lambda k: avg[k])
summary = ' '.join([email[closest[idx]] for idx in ordering])



点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐


