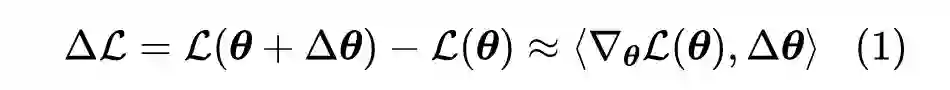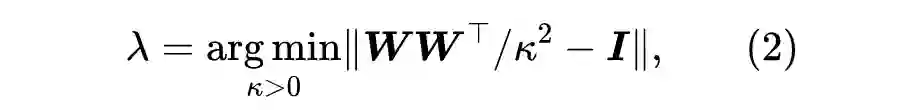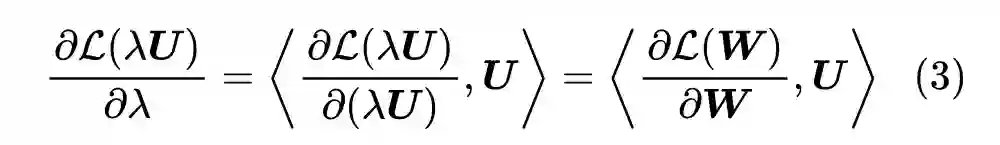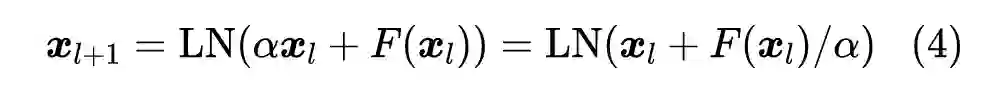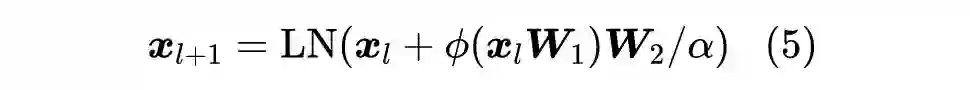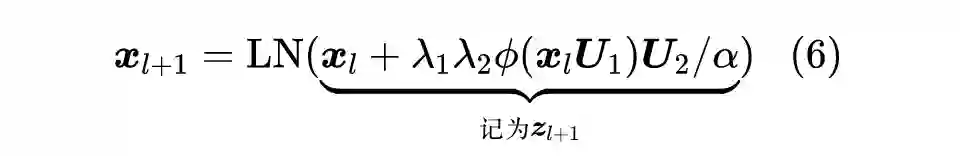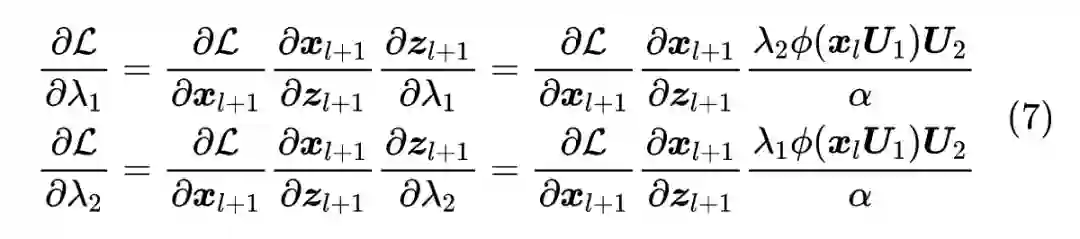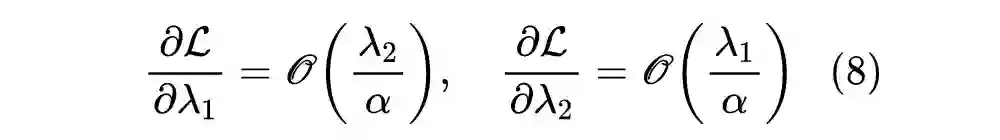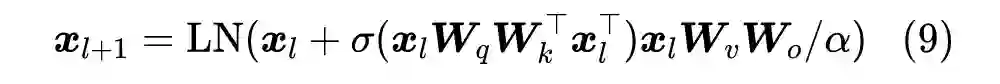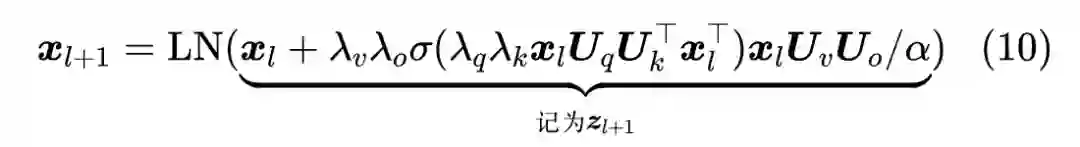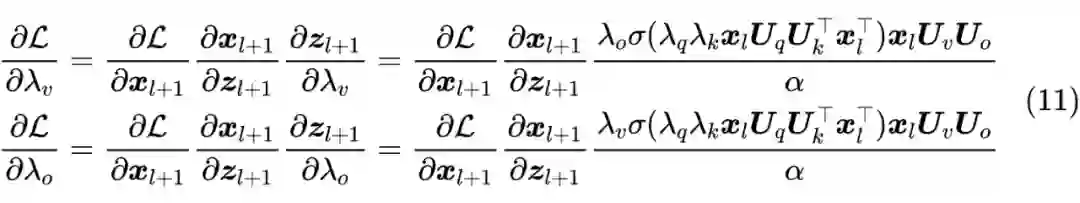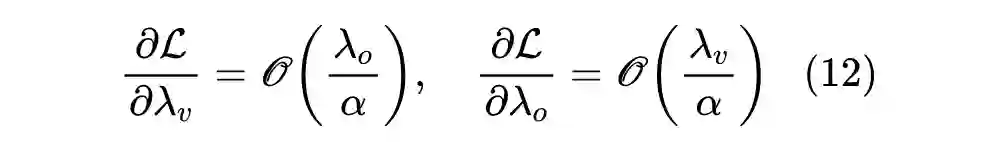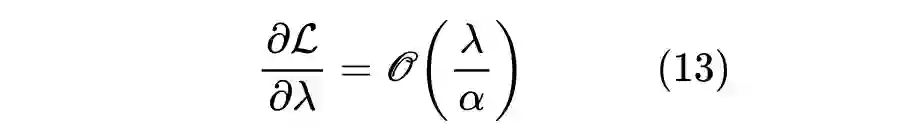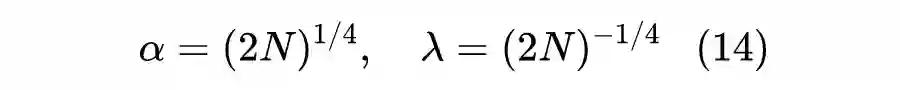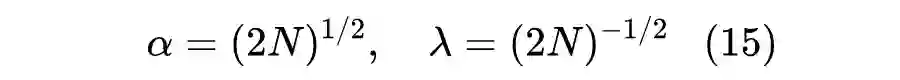![]()
©PaperWeekly 原创 · 作者 |
苏剑林
众所周知,现在的 Transformer 越做越大,但这个“大”通常是“宽”而不是“深”,像 GPT-3 虽然参数有上千亿,但也只是一个 96 层的 Transformer 模型,与我们能想象的深度相差甚远。是什么限制了 Transformer 往“深”发展呢?可能有的读者认为是算力,但“宽而浅”的模型所需的算力不会比“窄而深”的模型少多少,所以算力并非主要限制,归根结底还是 Transformer 固有的训练困难。一般的观点是,深模型的训练困难源于梯度消失或者梯度爆炸,然而实践显示,哪怕通过各种手段改良了梯度,深模型依然不容易训练。
近来的一些工作(如 Admin [1])指出,深模型训练的根本困难在于“增量爆炸”,即模型越深对输出的扰动就越大。上周的论文《DeepNet: Scaling Transformers to 1,000 Layers》[2] 则沿着这个思路进行尺度分析,根据分析结果调整了模型的归一化和初始化方案,最终成功训练出了 1000 层的 Transformer 模型。整个分析过程颇有参考价值,我们不妨来学习一下。
![]()
原论文的完整分析比较长,而且有些假设或者描述细酌之下是不够合理的。所以在本文的分享中,笔者会尽量修正这些问题,试图以一个更合理的方式来得到类似结果。
假设损失函数为
,
是它的参数,考虑参数由
变为
时损失函数的增量:
![]()
对于 SGD 有
,那么
。设模型有
层,每层的平均参数量为
,配合 Xavier 初始化以及各种 Normalization 手段,我们可以使得多数参数的梯度是
量级,所以有
。因此,模型每一步的更新量是正比于模型深度
的(宽度不在本文讨论范围),如果模型越深,那么更新量就越大,这意味着初始阶段模型越容易进入不大好的局部最优点,然后训练停滞甚至崩溃,这就是“增量爆炸”问题。
这时候解决方法有两个,一是初始阶段用更小的学习率进行训练(不超过
量级),然后慢慢增大学习率,这就是 Warmup 技巧;二就是调整初始化方案,使得参数的梯度是
量级,这样就自动抵消掉模型深度的影响。
![]()
怎么做到第二种方案呢?我们可以尝试分析 Transformer 的梯度。然而,精确的梯度求起来比较繁琐,并且事实上我们也不需要精确的梯度,而只是要对梯度做一个量级分析,所以我们可以用如下的“量级分解”技巧转化为标量的导数问题。
![]()
说白了,我们就是要将一个矩阵分解为一个标量
与一个尽可能正交的矩阵
之积。由于
接近正交矩阵,它起到了一个标准参考系的作用,而对应的
则代表了矩阵
的量级。如果
使用 Xavier 初始化,那么
相当于其中的 gain 参数,即在 Xavier 初始化的基础上还要再乘一个
。这是因为 Xavier 初始化的结果就接近一个正交矩阵,这一点可以参考《从几何视角来理解模型参数的初始化策略》
[3]
。
这意味着
跟
在量级上是成正比的,所以对
做量级分析就相当于对
做量级分析。这样原来的矩阵求导就可以转化为标量求导,降低了分析难度。
![]()
很多实验结果都显示虽然 Pre Norm 比 Post Norm 更容易训练,但 Post Norm 的最终效果往往更好些,所以原论文保留了 Post Norm 结构,并考虑了更一般的形式:
![]()
其中
是一个常数。简单起见,我们先考虑 FFN 层,此时
![]()
这里的
是激活函数,一般为 ReLU 或其变体(Swish、GeLU等),它们(近似)满足
。使用前一节的量级分解,我们得到
![]()
![]()
我们断言
都是
的,并且由于
都接近正交矩阵,所以
也是
的,因此最终有
![]()
现在考虑自 Self Attention,作为量级分析,我们考虑单头注意力即可,其形式为
![]()
其中
是 softmax 操作的简写,这里省略了 Attention 的 scale 操作。对上式进行量级分解后的形式为
现在我们可以对各个
分别求梯度,而由于 softmax 的存在,事实上
的梯度本身会很小,不会明显影响最终的更新量,所以其实我们考虑
的更新量足矣:
![]()
同样断言
都是
的,并且注意 softmax 出来是一个概率分布,然后对
的各个 token 做加权平均,通常而言,平均前后的向量会在同一数量级,所以我们认为 也是
的,因此结果跟 FFN 层的类似:
![]()
现在不管是 FFN 还是 Self Attention,我们都得到了相似的结论,现在简单起见,假设每个参数的量级(至少在初始化阶段)是一致的,即所有的
取同一个值,那么总的结论是
![]()
即梯度的量级是
。另一方面,我们说
层的 Transformer 模型,一般是
层的 Self Attention 加
层的 FFN,所以严格来说层数是
。因此,按照“增量爆炸”一节的分析,我们需要将梯度调整到
,上式告诉我们可以通过让
来实现。原论文的放缩更为宽松一些,得到的结果是
,量级上是等价的。
现在我们得到了
与
的一个比例关系,但无法直接得到
和
的具体值。按照论文的说法,是从对称角度出发,让
,从而可以解得
![]()
然而,单纯对称的解释显然是不够说服力的,我们需要搞清楚不同的选择究竟有什么不同的结果。为此,我们可以比较另外两组解:
另解一:
,此时参数的初始化缩小到原来的
倍,梯度也被缩小到原来的
倍,根据 SGD 的
得出每步的更新量也是原来的
倍,也就是说,调整前后的相对学习幅度是没有变化的,因此有可能刚开始
级别,但训练集几步后就脱离了这个量级了。
另解二:
,此时参数的初始化没有缩小,但梯度也被缩小到原来的
倍,根据 SGD 的
得出每步的更新量也是原来的
倍,调整前后的相对学习幅度是明显缩小了,因此有可能出现学习得非常慢的情况。
这两种情况看上去都各有缺点,因此介乎两者之间的式(14)似乎就能解释得通了,它就是保持梯度缩放到原来的
倍的同时,让初始学习步伐稍微慢一些,但又不至于太慢,隐式地起到了 Warmup 的作用。
![]()
上面的分析都是基于 SGD 进行的,但事实上我们很少直接用 SGD 去训练 NLP 模型,我们更多是自适应学习率优化器,主要有两大类:一是用二阶矩来校正学习率,Adam、AdamW 等都属此类;另一类是通过参数模长进一步校正学习率,比如 LAMB [4]、AdaFactor [5]。原论文的说法是“我们在 SGD 上进行推导,然后在Adam上验证发现也还可以”,但从理论上来讲,它们并不完全通用,这一节我们就来针对性地做一下分析。
对于 Adam 类优化器来说,每一步的更新量大约为
,所以
,它是正比于梯度的 1 次方而不是 2 次方,因此要过要让更新量跟层数无关,那么梯度应该缩小到原来的
倍才对,即应该有
,如果同样让
,那么有
![]()
对于 LAMB 类优化器来说,每一步更新量大约为
,所以
,注意到参数的缩放比例是
、梯度的缩放比例是
,从而是
。注意这类优化器每步的相对更新量是一样的(等于学习率
),所以不管怎么调整相对更新大小都不会变化,所以我们可以直接取
。
![]()
前面的两节推导过程都用到了断言“
都是
的”,那么它是否成立呢?这里我们事后分析一下。
其实也很简单,经过前述调整后,不管是 FFN 层(6)还是 Self Attention 层 (10),初始阶段每个残差分支的权重被缩放到原来的
倍,不管是哪种优化器的结果,
都是一个比较小的数字,这意味着初始阶段整个模型其实接近一个恒等函数,因此
自然都是
的,所以结论和断言是自洽的。
另外,可能有读者想问同样的分析是否可以用到 Pre Norm 结构上呢?答案是可以的,并且结论是基本一致的,只是因为 Norm 放在了残差分支之前,所以就没必要设置
参数了,所以结论就是上述关于 Post Norm 的结果中所有的
都等于为 1,然后重新计算相应的
。
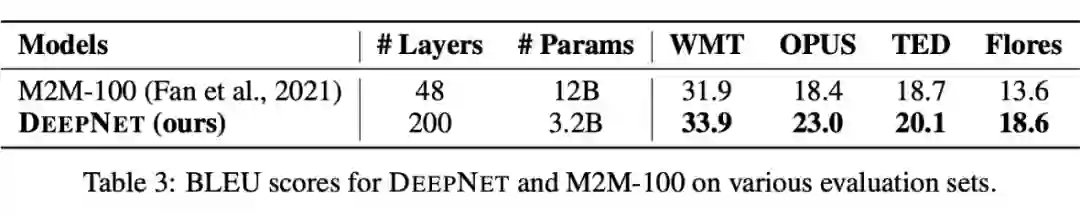
最后,读者可能有疑问的是花了那么多功夫讨论把模型做深,那么模型深度真有那么重要吗?有,原论文给出了一个漂亮的实验结果,用一个 200 层的“深而窄”的模型(32 亿参数),战胜了之前48层“浅而宽”的 SOTA 模型(120 亿参数):
![]()
本文分析了将 Transformer 做“深”的瓶颈所在并给出了相应的解决方案,文章的主要思路源于微软新出的 DeepNet,并对原论文的分析过程做了一定的简化和完善。
[1] https://arxiv.org/abs/2004.08249
[2] https://arxiv.org/abs/2203.00555
[3] https://kexue.fm/archives/7180
[4] https://kexue.fm/archives/7094
[5] https://kexue.fm/archives/7302
![]()
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()