1000层的Transformer,诞生了!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:夕小瑶的卖萌屋
大家好,我是卖萌酱。
今天下午卖萌屋作者群里一位MILA实验室的大佬在临睡前(蒙特利尔时间凌晨0点半)甩出来一篇论文:

DeepNet: Scaling Transformers to 1,000 Layers
大佬表示太困了,肝不动了,于是卖萌酱左手抄起一罐咖啡,右手接过论文就开始肝了,必须第一时间分享给卖萌屋的读者小伙伴们!
论文链接:
https://arxiv.org/pdf/2203.00555.pdf
代码:https://github.com/microsoft/unilm
首先,把Transformer模型训深最大的问题是什么?
耗显存?
训练慢?
都不是!最大的问题是压根就不收敛啊...
所以这篇论文最关键的贡献就是提出了一种新的Normalization方式——DeepNorm,有效解决了Transformer训练困难的问题。
其实早在2019年,就有研究者针对Transformer训练困难的问题,提出了Pre-LN来提升Transformer的训练稳定性,但是随后有人发现,Pre-LN会导致模型底层的梯度比顶层的还要大,这显然是不合理的,因此往往训练出的模型效果不如传统的Post-LN。
尽管后续也有一些补丁来试图解决这些问题,但这些既有的尝试都只能让Transformer的模型深度最多训练到几百层,始终无法突破千层的天花板。
本文提出的DeepNorm,则成功打破了这个天花板。
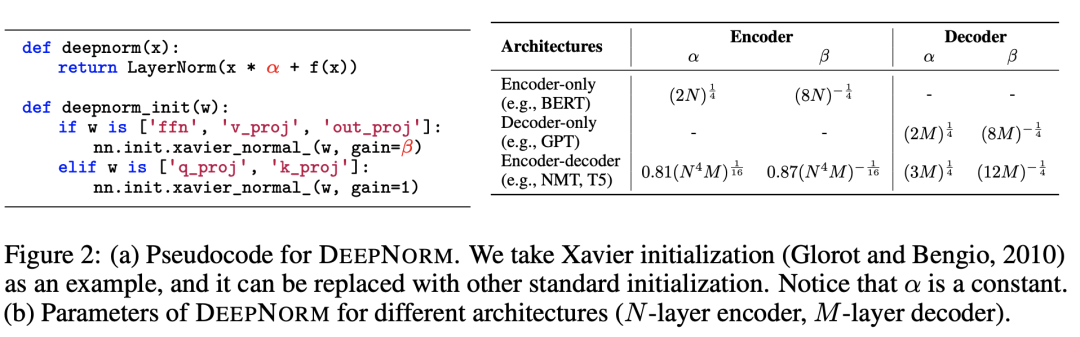
从以上DeepNorm伪代码实现中,可以看到这确实是simple but effective的方法,作者也给出了几个不同场景下的参数经验取值。
效果层面,作者在机器翻译benchmark上做了实验:
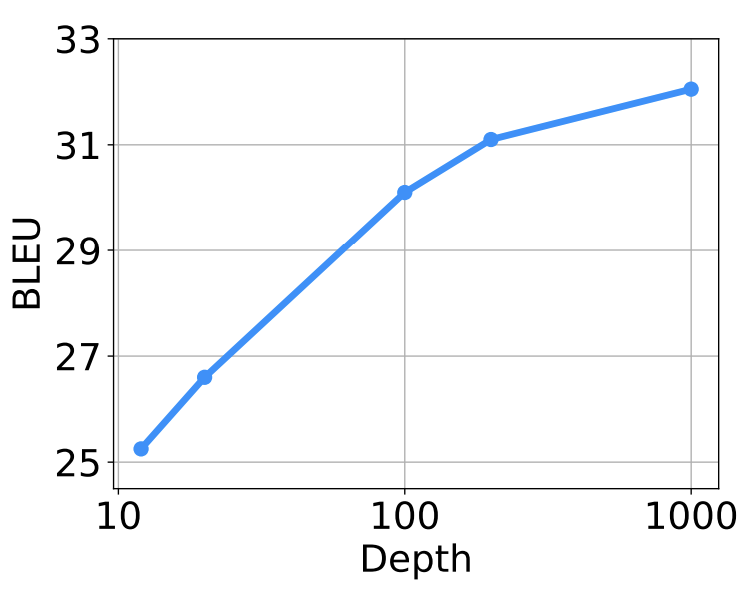
可以看到随着模型深度从10层到100层再到1000层,机器翻译BLEU指标持续上升。

而在与前人工作的比较上,200层的DeepNet(3.2B参数量)比Facebook M2M 48层的矮胖大模型(12B参数量)有足足5个点的BLEU值提升。
此外,作者表示将来会尝试将DeepNet往更多NLP任务上迁移(包括预训练语言模型),期待DeepNet能给NLP带来下一波春天!
DeepNet论文下载
后台回复:DeepNet,即可下载上述论文
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看




