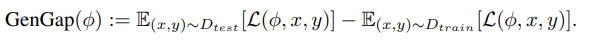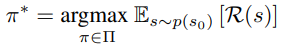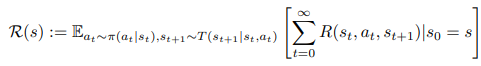强化学
习应用广泛,但为何泛化这么难?如果要在现实世界的场景中部署强化学习算法,避免过度拟合至关重要。来自伦敦大学学院、UC 伯克利机构的研究者撰文对深度强化学习中的泛化进行了研究。
强化学习 (RL) 可用于自动驾驶汽车、机器人等一系列应用,其在现实世界中表现如何呢?现实世界是动态、开放并且总是在变化的,强化学习算法需要对环境的变化保持稳健性,并在部署期间能够进行迁移和适应没见过的(但相似的)环境。
然而,当前许多强化学习研究都是在 Atari 和 MuJoCo 等基准上进行的,其具有以下缺点:它们的评估策略环境和训练环境完全相同;这种环境相同的评估策略不适合真实环境。
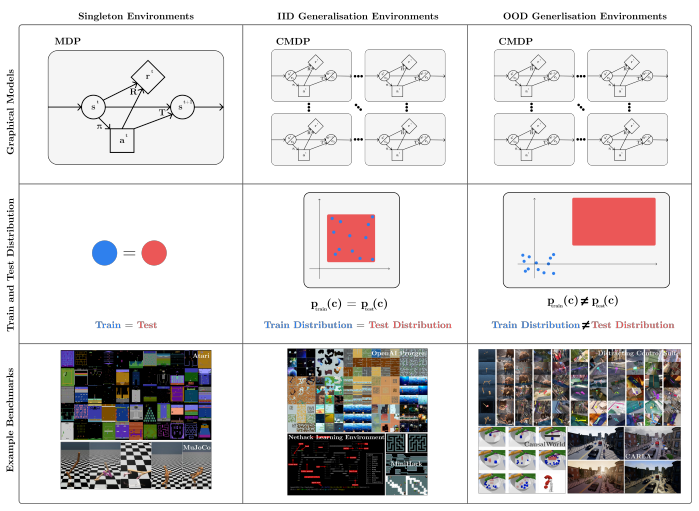
我们以下图为例:下图为三类环境(列)的可视化,涉及图模型、训练和测试分布以及示例基准(行)。经典 RL 专注于训练和测试相同的环境(单例环境,第一列),但在现实世界中,训练和测试环境不同,它们要么来自相同的分布(IID 泛化环境,第二列),要么来自不同的分布( OOD 泛化环境,第三列)。
![]()
经典 RL(训练和测试环境相同)与监督学习标准假设形成鲜明对比,在监督学习中,训练集和测试集是不相交的,而对于 RL 来说,RL 策略要求训练和测试环境相同,因此在评估时可能导致模型过拟合。即使在稍微调整的环境实例上 RL 表现也不佳,并且在用于初始化没见过的随机种子上失败 [7, 8, 9, 10]。
目前,许多研究者已经意识到这个问题,开始专注于改进 RL 中的泛化。来自伦敦大学学院、UC 伯克利机构的研究者撰文《 A SURVEY OF GENERALISATION IN DEEP REINFORCEMENT LEARNING 》,对深度强化学习中的泛化进行了研究。
![]()
论文地址:https://arxiv.org/pdf/2111.09794v1.pdf
本文由 7 个章节组成:第 2 节中简要描述了 RL 相关工作;第 3 节介绍了 RL 泛化中的形式(formalism)和术语;第 4 节研究者使用这种形式来描述当前 RL 中泛化基准,包括环境(第 4.1 节)和评估协议(第 4.2 节);第 5 节中研究者对泛化研究进行了分类和描述;第 6 节研究者对 RL 当前领域进行了批判性讨论,包括对未来工作关于方法和基准的建议,并总结了关键要点;第 7 节是全文总结。
该研究提出了一种形式和术语,以用于讨论泛化问题,这一工作是建立在之前研究 [12, 13, 14, 15, 16] 的基础上进行的。本文将先前的工作统一成一个清晰的形式描述,这类问题在 RL 中被称为泛化。
该研究提出了对现有基准的分类方法,可用于测试泛化。该研究的形式使我们能够清楚地描述泛化基准测试和环境设计的纯 PCG(Procedural Content Generation) 方法的弱点:完整的 PCG 环境会限制研究精度。该研究建议未来的环境应该使用 PCG 和可控变异因素的组合。
该研究建议对现有方法进行分类以解决各种泛化问题,其动机是希望让从业者能够轻松地选择给定具体问题的方法,并使研究人员能够轻松了解使用该方法的前景以及可以做出新颖和有用贡献的地方。该研究对许多尚未探索的方法进行进一步研究,包括快速在线适应、解决特定的 RL 泛化问题、新颖的架构、基于模型的 RL 和环境生成。
该研究批判性地讨论了 RL 研究中泛化的现状,推荐了未来的研究方向。特别指出,通过构建基准会促进离线 RL 泛化和奖励函数进步,这两者都是 RL 中重要的设置。此外,该研究指出了几个值得探索的设置和评估指标:调查上下文效率和在持续的 RL 设置中的研究都是未来工作必不可少的领域。
在第 3 节中,研究者提出了一种用于理解和讨论 RL 泛化问题的形式。
监督学习中的泛化是一个被广泛研究的领域,因此比 RL 中的泛化研究更深。在监督学习中,通常假设训练和测试数据集中的数据点都是从相同的底层分布中抽取的。泛化性能与测试性能是同义词,因为模型需要泛化到它在训练期间从未见过的输入。在监督学习中的泛化可定义为:
![]()
而在 RL 中,泛化的标准形式是马尔可夫决策过程 (MDP)。MDP 中的标准问题是学习一个策略π(|s),该策略产生给定状态下的行动分布,从而使 MDP 中策略的累积奖励最大化:
![]()
其中π^∗是最优策略,Π是所有策略的集合,R: S→R 是一个状态的返回,计算为:
![]()
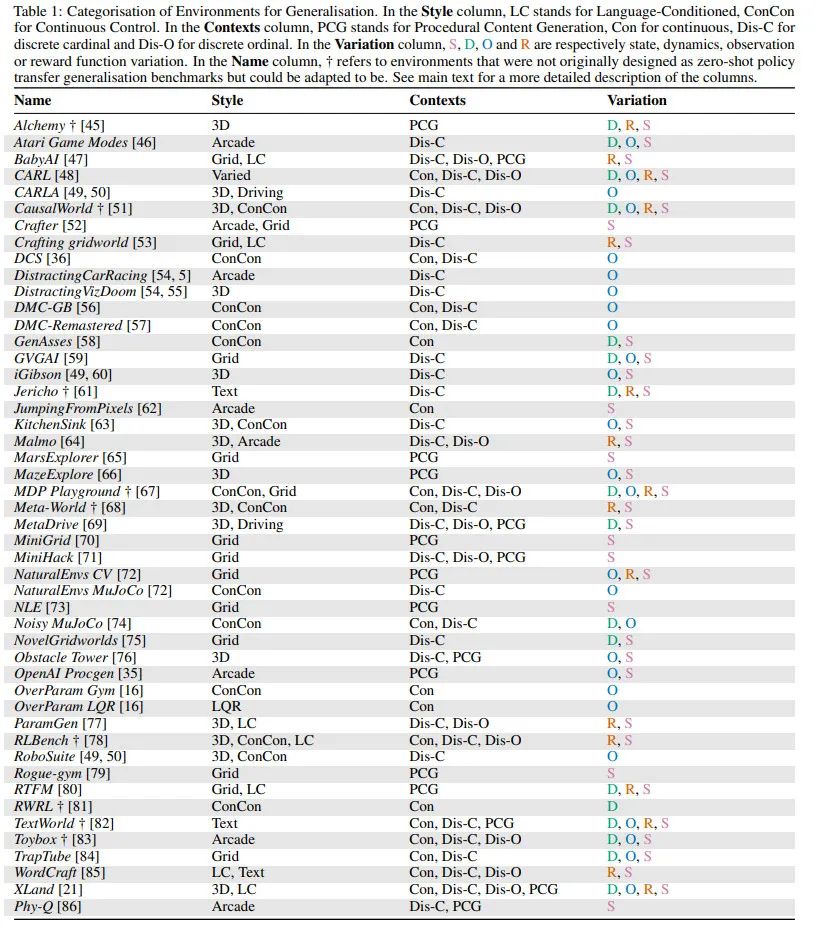
表 1 列出了在 RL 中可以进行测试泛化的可用环境,共 47 个,表中总结了每个环境的关键特性。
![]()
其中,Style 列:提供了对环境类型的粗略高层次描述;Contexts 列:在文献中有两种设计上下文集的方法,这些方法之间的关键区别是 context-MDP 创建是否对研究人员可访问和可见。第一种称为 PCG,在 context-MDP 生成中依赖于单个随机种子来确定多个选择;第二种方法对 context-MDP 之间的变化因素提供了更直接的控制,称之为可控环境。Variation 列:描述了在一组 context MDP 中发生的变化。
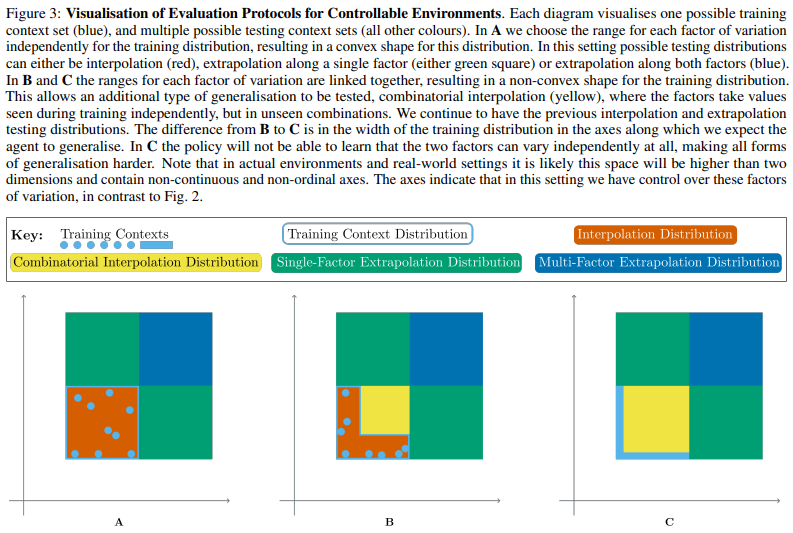
泛化评估协议:事实上,在纯 PCG 环境中,评估协议之间变化唯一有意义的因素是上下文效率限制。PCG 环境提供了三类评估协议,由训练上下文集决定:单个上下文、一小组上下文或完整上下文集。这些分别在图 2A、B 和 C 中进行了可视化。
![]()
可控环境评估协议:许多环境不仅使用 PCG,并且具有变化因子,可以由环境用户控制。在这些可控环境中,评估协议范围更广。对于每个因素,我们可以为训练上下文集选择一个选项,然后在此范围内或之外对测试上下文集进行采样。选项范围如图 3 所示。
![]()
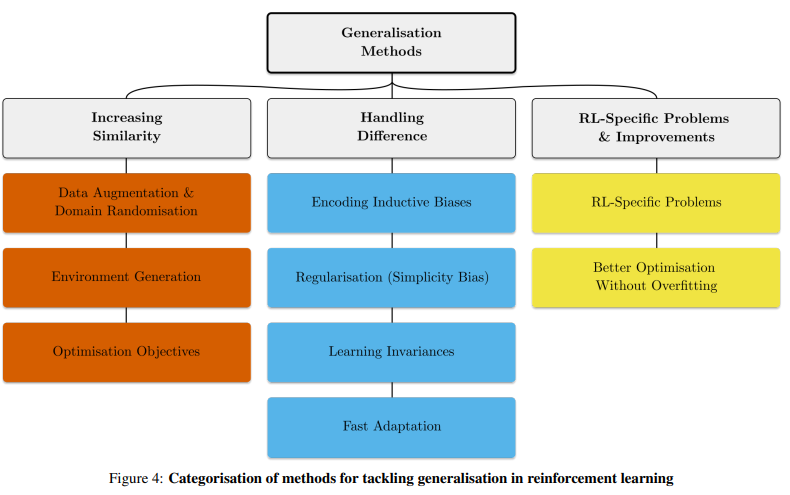
文中对处理 RL 中泛化的方法进行分类。当训练和测试上下文集不相同时,RL 泛化问题就会出现。图 4 是分类图表。
![]()
在其他条件相同的情况下,训练和测试环境越相似,RL 泛化差距越小,测试时间性能越高。通过将训练环境设计为尽可能接近测试环境,可以增加这种相似性。因此,本文在增加相似性方法中,包括数据增强和域随机;环境生成;优化目标。
处理训练和测试之间的差异:经过训练的模型会依赖训练中学习到的特征,但在测试环境中的一点改变就会影响泛化性能。在 5.2 节中,该研究回顾了处理训练和测试环境特征之间存在差异的方法。
关于 RL 特定问题和改进:前两节中的动机大多同样适用于监督学习。然而,除了来自监督学习的泛化问题之外,RL 还存在抑制泛化性能的其他问题。在 5.3 节中,该研究针对这一问题进行了讨论,并且还讨论了纯粹通过更有效地优化训练集(至少在经验上)来提高泛化的方法,这些方法不会导致网络过拟合。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com