重磅 | 机器学习大神Bengio最新论文发布,专注RNN优化难题,将在NIPS提出新概念fraternal dropout

本文授权转载自AI科技大本营(ID:rgznai100)
编译 | Troy·Chang、爱心心、reason_W
校对 | reason_W
下个月机器学习领域的顶会Nips就要在大洋彼岸开幕啦,那么这次的Nips又有什么值得关注的亮点呢?Bengio在新作中提出了RNN优化的新概念fraternal dropout,通过最小化使用不同的dropout mask的同一个RNN的预测差异,提升RNN对于不同dropout mask的不变性,来对RNN进行优化。模型在对比实验中取得了非常惊艳的效果,同时在图像标注和半监督任务上也表现不俗,下面就跟随小编对这篇文章进行一发膜拜吧。
摘要
RNN作为神经网络中的一类十分重要的架构,主要用于语言建模和序列预测。然而,RNN的优化却相当棘手,比前馈神经网络要难的多,学界也提出了很多技术来解决这个问题。我们在我们中提出了一项叫做fraternal dropout的技术,主要通过利用dropout来实现这个目标。具体来说,我们首先用不同的dropout mask对两个一模一样的RNN进行训练,同时最小化它们(pre-softmax)预测的差异。通过这种方式,我们的正则项会促进RNN的表示对dropout mask的不变性。我们证明了我们的正则项的上限是线性期望dropout目标,而且线性期望dropout目标已经被证明了可以解决dropout在训练和推理阶段的差异导致的较大差异(gap)。我们在两个基准数据集(Penn Treebank 和Wikitext-2.)上进行了序列建模任务以评价我们的模型,并且获得了十分惊艳的结果。我们也证明了这种方法可以为图像标注(Microsoft COCO)和半监督(CIFAR-10)任务带来显著的性能提升。
1 前言
像LSTM网络(LSTM; Hochreiter & Schmidhuber(1997))和门控循环单元(GRU; Chung et al. (2014))这样的循环神经网络都是处理诸如语言生成、翻译、语音合成以及机器理解等序列建模任务的流行架构。然而由于输入序列的长度可变性,每个时刻相同转换算子的重复应用以及由词汇量决定的大规模密集嵌入矩阵等问题的存在,与前馈网络相比,这些RNNs网络架构更加难以优化。也正是由于同前馈神经网络相比,RNNs在优化问题上遇到的这些挑战,使得批归一化以及它的变体(层归一化,循环批归一化,循环归一化传播),尽管确实带来了很大的性能提升,但其应用依然没有像它们在前馈神经网络中对应的部件一样成功(Laurent等, 2016),。同样的,dropout的朴素应用(Srivastava等,2014)也已经证明在RNNs中是无效的(Zaremba等,2014)。因此,RNNs的正则化技术到目前为止依然是一个活跃的研究领域。
为了解决这些挑战,Zaremba等人(2014)提出将dropout仅用于多层RNN中的非环式连接。Variational dropout(Gal&Ghahramani,2016))会在训练期间在整个序列中使用相同的dropoutmask。DropConnect(Wan等,2013)在权重矩阵上应用了dropout操作。Zoneout(Krueger et al等(2016))以类似的dropout方式随机选择使用前一个时刻隐藏状态,而不是使用当前时刻隐藏状态。类似地,作为批归一化的替代,层归一化将每个样本内的隐藏单元归一化为具有零均值和单位标准偏差的分布。循环批标准化适用于批标准化,但对于每个时刻使用非共享的mini-batch统计(Cooijmans等,2016)。
Merity等人(2017a)和Merity等(2017b)从另一方面证明激活正则化(AR)和时域激活正则化(TAR)也是正则化LSTMs的有效方法。
在我们中,我们提出了一个基于dropout的简单正则化,我们称之为fraternal dropout。这个方法将最小化两个网络预测损失的等权重加权和(这两个网络由两个不同dropoutmask在同一个LSTM上得到),并将两个网络的(pre-softmax)预测结果的L2差作为正则项相加。我们分析证明了,该方法的正则化目标等于最小化来自不同的i.i.d. dropoutmask的预测结果的方差。该方法将会提升预测结果对于不同dropoutmask的不变性。同时,文章也讨论了我们的正则项和线性期望dropout(Ma等,2016)、II-model(Laine&Aila,2016)以及激活正则化(Merity等,2017a)的相关性,并且通过实验证明了我们的方法与这些相关方法相比带来的性能提升,第五部分的ablation study将进一步解释这些方法。
2 FRATERNAL DROPOUT
Dropout在神经网络中是一种强大的正则化方式。它通常在密集连接的层上更有效,因为与参数共享的卷积层相比,它们更容易受到过拟合的影响。出于这个原因,dropout是RNN系列一个重要的正则化方式。然而,dropout的使用在训练和推理阶段之间是存在gap的,因为推理阶段假设是用线性激活的方式来校正因子,因此每个激活的期望值都会不同。(小编注:为了更好的理解这部分内容,大家可以参考Dropout with Expectation-linear Regularization - https://arxiv.org/abs/1609.08017 ,这篇文章从理论上分析了dropout的ensemble模式和一般的求期望模式的gap。然后提出了将这个gap作为一种正则化方式,也就是说gap的优化目标就是要尽可能小)。另外,带有dropout的预测模型通常会随着不同dropout mask而变化。然而,在这种情况下理想的结果就是最后的预测结果不随着dropout mask的变化而变化。
因此,提出fraternal dropout的想法就是在训练一个神经网络模型时,保证在不同dropout masks下预测结果的变化尽可能的小。比如,假定我们有一个RNN模型M(θ),输入是X,θ 是该模型的参数,然后让
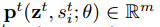
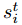
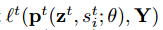
在fraternal dropout中,我们采用两个相同的RNN来同时前馈输入样本X。这两个RNN共享相同的模型参数θ,但是在每个时刻t有不同的dropout masks 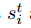
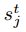
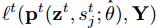
因此,fraternal dropout整体的损失函数就可以由下面公式表示,
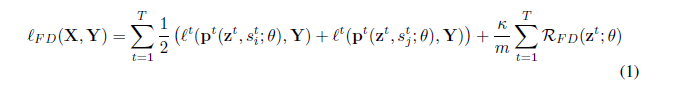
其中κ是正则化系数,m是
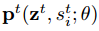
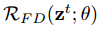
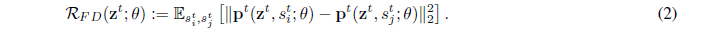
我们采用蒙特卡洛采样来估计
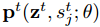
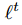
我们注意到,如下面所示,我们正则化项的目标等价于最小化在不同dropout masks下,预测函数的方差(附录中有证明)
备注1 假定
因此,
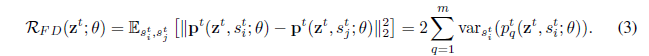
3 相关工作
3.1 线性期望dropout相关工作
Ma et al.(2016)分析研究显示下述两者之间的预期误差(在样本上)是有上限的,即在所有的dropout mask下的模型的期望值与使用平均mask的期望值之间的误差。基于这一结论,他们提出了明确地最小化差异(我们在我们的该符号表达中采用了他们的正则式),
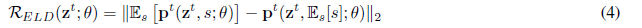
其中,s是dropout mask。但是,基于可行性考虑,他们提出在实践中使用下列正则式进行替代,
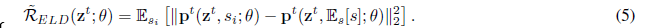
特别地,这个式子是通过在网络中的两次前馈输入(分别使用和不使用dropout mask),以及最小化主要网络损失(该损失是在有dropout的情况下的)和前面指定的正则项(但是在无dropout的网络中没有反向传播梯度)来实现的。Ma et al.(2016)的目标是最小化网络损失以及期望差异,这个期望差异是指来自独立的dropout mask的预测值和来自期望的dropout mask的预测值之间的差异。同时,我们的正则项目标的上限是线性期望dropout,如下式所示(附录中证明):
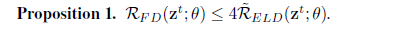
结果表明,最小化ELD目标可以间接地最小化我们的正则项。最终如前文所述,他们仅在无dropout的网络中应用了目标损失(target loss)。实际上,在我们的ablation研究中(参见第5节),我们发现通过网络(无dropout)反向传播目标损失(target loss)会让优化模型更难。但是,在该设置中,同时反向传播目标损失(target loss)能够获得包括性能增益和收敛增益的网络收益。我们认为由于在所用实例(case)中,网络权重更有可能通过反向传播更新来达到目标,所以我们的正则项收敛速度会更快。尤其对于权重dropout(Wan et al., 2013)更是如此,因为在这种情况下,dropout权重将不会在训练的迭代中获得更新。
3.2 II –model 相关工作
为了实现在半监督分类任务中提高性能的目标,Laine & Aila(2016)提出了II –model。他们提出的模型和我们提出的模型相似,除了他们仅在其中一个网络中应用了目标损失(target loss),并且使用的是依赖时间的权重函数(而我们使用常量k/m),可以等价于是我们模型的深度前馈版本。他们实例的直觉(intuition)是利用未标记的数据来最小化两种预测上的差异,即两种使用不同dropout mask的同一网络的预测值。而且,他们也在监督任务中测试了他们的模型,但是无法解释使用这一正则项带来的提升。
通过对我们的实例(case)进行分析,我们证明了,最小化该正则项(在II –model中也使用了)同最小化模型预测结果(备注1)中的方差是等价的。此外,我们也证明了正则项同线性期望dropout(命题1)之间的关系。在第5节,我们研究了基于没有在II –model中使用的两种网络损失的目标的影响。我们发现在两个网络中应用目标损失(target loss)将使得网络获得关键性的更快的收敛。最后,我们注意到时域嵌入(temporal embedding ,Laine&Aila(2016)提出的另一模型,声称对于半监督学习来说,是比II –model更好的版本)在自然语言处理应用中相当的棘手,因为保存所有时刻的平均预测值会十分消耗内存(因为预测值的数目往往非常大-数以万计)。还有一点,我们证明了在监督学习的实例(case)中,使用时间依赖的权重函数来代替一个常量值k/m是没有必要的。因为标记的数据是已知的,我们没有观察到Laine&Aila(2016)提到的问题,即当在早期训练的epoch中太大时,网络会陷入退化。我们注意到寻找一个优化的常量值比调整时间依赖的函数更加容易,这也在我们的实例中进行了实现。
和II –model的方法相似,我们的方法也和其他半监督任务相关,主要有Rasmus et al.(2015)和Sajjadi et al.(2016)。由于半监督学习并不是本文要关注的部分,因此我们参考了Laine&Aila(2016)的更多细节。
4 实验
4.1 语言模型
在语言建模的情形下,我们在两个基准数据集Penn Tree-bank(PTB)数据集(Marcus等,1993)和WikiText-2(WT2)数据集(Merity等,2016)上测试了我们的模型。预处理操作参考了Mikolov等(2010)(用于PTB语料库),并且用到了Moses tokenizer(Koehn等,2007)(用于WT2数据集)。
对于这两个数据集,我们都采用了Merity等人描述的AWD-LSTM 3层架构。 (2017a)。 用于PTB的模型中的参数数量是2400万,而WT2的参数数量则是3400万,这是因为WT2词汇量更大,我们要使用更大的嵌入矩阵。 除了这些差异之外,架构是相同的。
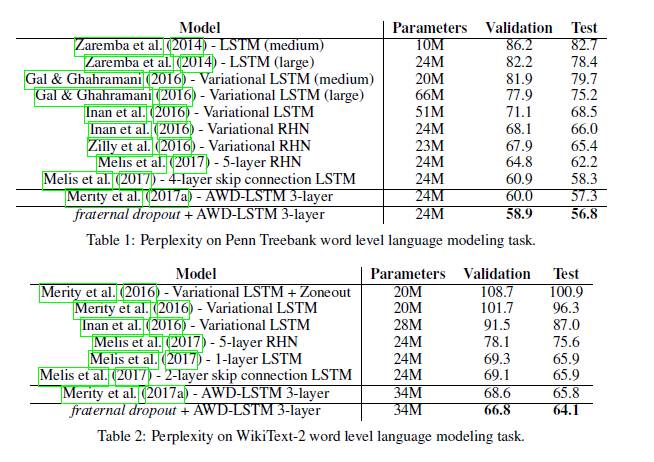
Penn Tree-bank(PTB)词级任务
我们使用混淆度指标来评估我们的模型,并将我们获得的结果与现有的最好结果进行比较。表1显示了我们的结果,在现有benchmark上,我们的方法达到了最先进的性能。
WikiText-2词级任务
在WikiText-2语言建模任务的情况下,我们的表现优于目前的最新技术水平。 表2列出了最终结果。关于实验的更多细节可以在5.4节中找到。
4.2 图像标注
我们也把fraternal dropout应用到了图像标注任务上。我们使用著名的show and tell模型作为baseline(Vinyals等,2014)。这里要强调的是,在图像标注任务中,图像编码器和句子解码器架构通常是一起学习的。但既然我们想把重点放在在RNN中使用fraternal dropout的好处上,我们就使用了冻结的预训练ResNet-101(He 等,2015)模型作为我们的图像编码器。这也就意味着我们的结果不能与其他最先进的方法直接比较,但是我们提供了原始方法的结果,以便读者可以看到我们的baseline良好的表现。表3提供了最终的结果。
我们认为,在这个任务中,κ值较小时,效果最好,因为图像标注编码器在开始时就被给予了所有信息,因此连续预测的方差会小于在无条件的自然语言处理任务中的方差。Fraternal dropout可能在这里是有利的,主要是因为它对不同mask的平均梯度进行了平均,从而更新权重频率更快。
5 ABLATION STUDIES (模型简化测试)
在本节中,我们的目标是研究与我们方法密切相关的现有方法。expectation linear dropout (Ma et al. ,2016),Π-model(Laine & Aila 2016)和activity regularization(Merity et al. 2017b),我们所有的ablation studies(小编注:ablation study是为了研究模型中所提出的一些结构是否有效而设计的实验)都是采用一个单层LSTM,使用相同的超参数和模型结构。
5.1 线性期望DROPOUT (ELD)
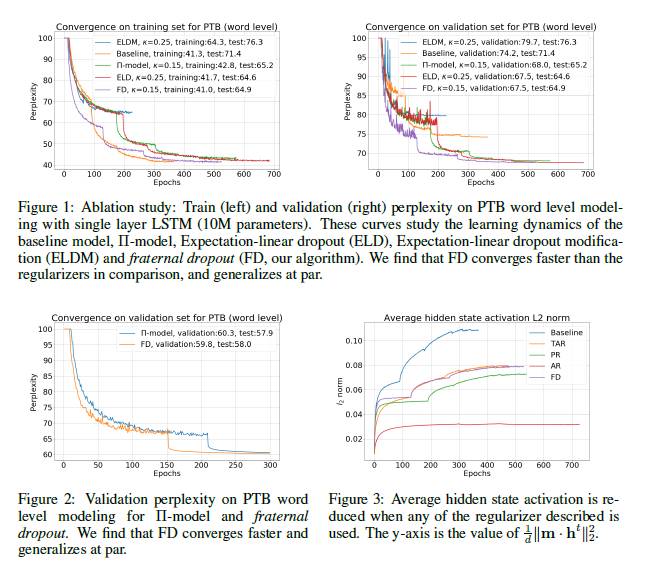
第二部分已经讨论了我们法方法和ELD方法的联系。这里我们进行实验来研究使用ELD正则化和我们的正则化(FD)性能上的差异。除了ELD,我们还研究了一个ELD的改进版ELDM。ELDM就是跟FD的用法相似,将ELD应用在两个相同的LSTM上(在原作者的实验中只是在一个LSTM上用了dropout)。因此我们得到了一个没有任何正则化方式的基准模型。图1画出了这几种方法训练过程的曲线。与其他方法相比,我们的正则化方法在收敛性上表现的更好。而在泛化性能上,我们发现FD和ELD相似,而基准模型和ELDM表现得更差。有趣的是,如果一起看训练和验证曲线,ELDM似乎还有待进一步的优化。
5.2 Π-MODEL
因为Π-MODEL和我们的算法相似(即使它是为前馈网络中的半监督学习而设计的),所以我们为了明确我们算法的优势,分别从定性和定量的角度研究了它们在性能上的差异。首先,基于PTB(Penn Treebank Dataset)任务,我们运行了单层LSTM和3层AWD-LSTM来在语言建模上对两种算法进测试比较。图1和2显示了测试结果。我们发现我们的模型比Π-MODEL收敛速度明显加快,我们相信这是因为我们采用两个网络(Π-MODEL相反)反向传播目标损失,导致了更多的采用基于目标梯度的参数更新。
尽管我们设计的算法是专门来解决RNN中的问题,但为了有一个公平的对比,我们在半监督任务上也与Π-MODEL做了对比。因此,我们使用了包含10类由32x32大小图像组成的CIFAR-10数据集。参照半监督学习文献中通常的数据拆分方法,我们使用了4000张标记的图片和41000张无标记图片作为训练集,5000张标记的图片做验证集合10000张标记的图片做测试集。我们使用了原版的56层残差网络结构,网格搜索参数
5.3激活正则化(AR)和时域激活正则化(TAR)分析
Merity et al.(2017b)的作者们研究了激活正则化(AR)的重要性,和在LSTM中的时域激活正则化(TAR),如下所示,

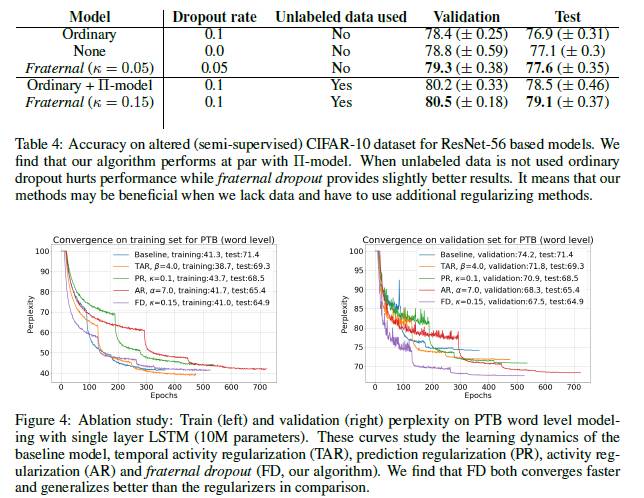
表4:基于ResNet-56模型在改变的(半监督任务)CIFAR-10数据集的准确率。我们发现我们提出的算法和II模型有同等的表现。当未标记数据没有被使用,传统dropout会破坏性能,但是fraternal dropout提供了略好的结果。这意味着当缺乏数据和不得不使用额外的正则方法时,我们的方法是有利的。
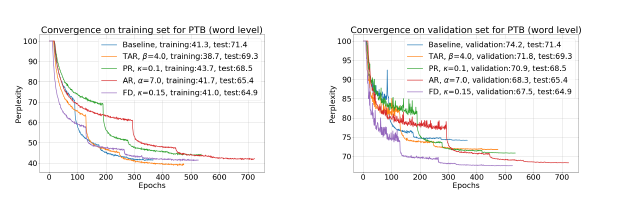
图4:Ablation研究:使用PTB词级模型的单层LSTM(10M参数)的训练(左)和验证(右)混淆度。显示了基准模型、时域激活正则化(TAR)、预测模型(PR)、激活正则化(AR)和fraternal dropout(FD,我们的算法)的学习动态曲线。我们发现与对照的正则项相比,FD收敛速度更快,泛华性能更好。
其中,是LSTM在时刻t时的输出激活(因此同时取决于当前输入和模型参数)。注意AR和TAR正则化应用在LSTM的输出上,而我们的正则化应用在LSTM的pre-softmax输出上。但是,因为我们的正则项能够分解如下:
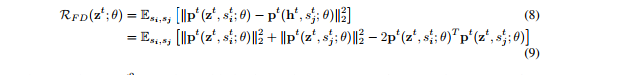
并且,封装了一个项和点积项,我们通过实验确定了在我们的方法中的提升并不是单独由正则项决定的。TAR目标也有一个相似的争论。我们在上运行网格搜索,包括在Merity et al.(2017b)中提到的超参数。我们在提出的正则项中使用。而且,我们也在一个正则式为正则项(PR)上进行了比较,以进一步排除仅来自于正则项的任何提升。基于这一网格搜索,我们选择了在验证集上对所有正则化来说最好的模型,另外还报告了一个未使用已提及的4种正则化的基准模型。学习动态如图4所示。与其他方法相比,我们的正则项在收敛和概括期间都表现更好。当描述的任意正则项被应用时,平均隐藏态激活减少(如图3所示)。
5.4 LANGUAGE MODELING FAIR COMPARISON(语言模型比较)
正如4.1小节所述,由于Melis等人(2017)的影响,我们要确保fraternal dropout能够超越现有的方法不仅仅是因为广泛的超参数网格搜索。因此,在我们的实验中,我们保留了原始文件中提到的绝大多数超参数,即嵌入和隐藏状态大小,梯度裁剪值,权重衰减以及用于所有dropout层的值(词向量上的dropout,LSTM层间的输出,最终LSTM的输出和嵌入dropout)。
当然,也进行了一些必要的变化:
AR和TAR的系数必须改变,因为fraternal dropout也影响RNN的激活(如5.3小节所述) - 我们没有进行网格搜索来获得最好的值,而是简单地去除了AR和TAR正则项。
由于我们需要两倍的内存,所以batch的size被减小了一半,从而让模型产生大致相同的内存量需求,并且可以安装在同一个GPU上
最后一项变动的地方是改变ASGD的非单调间隔超参数n。我们在n∈{5,25,40,50,60}上进行了一个网格搜索,并且在n取最大值(40,50和60)的时候获得了非常相似的结果。因此,我们的模型使用普通SGD优化器的训练时间要长于原始模型。
为了确保我们的模型效果,我们在PTB数据集上通过使用不同种子的原始超参数(不进行微调)运行了10个学习程序来计算置信区间。平均最佳验证混淆度为60.64±0.15,最小值为60.33。测试混淆度分别为58.32±0.14和58.05。我们的得分(59.8分验证混淆度和58.0分测试混淆度)比最初的dropout得分好。
由于计算资源有限,我们在WT2数据集对fraternal dropout运行了一次单独的训练程序。在这个实验中,我们使用PTB数据集的最佳超参数(κ= 0.1,非单调间隔n = 60,batch size减半)。
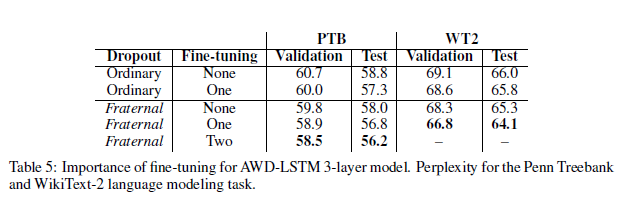
我们证实使用fine-tuning会对ASGD有好处(Merity等,2017a)。然而,这是一个非常耗时的做法,因为在这个附加的学习过程中可能会使用不同的超参数,所以通过广泛的网格搜索而获得更好的结果的可能性更高。因此,在我们的实验中,我们使用与官方存储库中实施的相同的fine-tunin程序(甚至没有使用fraternal dropout)。表5中列出了fine-tuning的重要性。
我们认为,运行网格联合搜索所有超参数可能会获得更好的结果(改变dropout率可能是尤其有利,因为我们的方法就明确地使用了dropout)。然而,我们这里的目的是排除仅仅因为使用更好的超参数而表现更好的可能性。
6 结论
在论文中,我们提出了一个叫做fraternal dropout的简单RNNs正则化方法,通过作为正则项来减少模型在不同的dropout mask上预测结果的方差。通过实验证明了我们的模型具有更快的收敛速度,同时在基准语言建模任务上取得了最先进的成果。 我们也分析研究了我们的正则项和线性期望dropout (Ma 等,2016)之间的关系。我们进行了一系列的ablation 研究,从不同的角度评估了模型,并从定性和定量的角度将其与相关方法进行了仔细比较。
论文链接 Fraternal Dropout
https://arxiv.org/abs/1711.00066

限时干货下载
Step 1:长按下方二维码,添加微信公众号“数据玩家「fbigdata」”
Step 2:回复【2】免费获取完整数据分析资料「包括SPSS\SAS\SQL\EXCEL\Project!」




