博鳌人工智能翻译乌龙后,你必须知道的机器翻译简史

作者:尹相志 / 秦朔朋友圈ID:qspyq2015
这是秦朔朋友圈的第1934篇原创首发文章

在今年的博鳌亚洲论坛中,除了主要议程外,最引人注目的热点是首次引进了人工智能同传技术进行会议中的实时翻译。然而,理想很丰满,但现实却很骨感,人工智能同传并没有出现原先大肆宣称的“让同传业界面对即将失业的威胁”,相反的,严重抽风的翻译结果,反倒让相关从业人员松了口气,看来这行饭还可以吃很久……


下文会对这次乌龙失误提供一些技术面的看法,但既然谈到机器翻译简史,就让我们先把“博鳌翻译事件”搁一边,先回溯至语言翻译的起点——巴别塔。
《圣经·旧约·创世纪》第11章记载,在大洪水退去后,这世界上的人类都是诺亚的子孙。大家说同样的语言、用同样的口音。那时人类开始通力合作,希望能够建造名为巴别塔的通天之塔,这个举动惊动了神,因此他让全世界的人类开始有了不同的语言,从此人类再也无法齐心合作,让造通天塔的计划以失败告终,语言差异也成为了人类沟通时最大的障碍。也许是血液中仍有想要重建巴别塔的梦想,因此翻译就成为人类在过去千百年历史不断演进的重点文化工程。
语言的隔阂并不是那么容易打破的,尤其是要跨语言来理解同样的概念,人类历史上第一次出现跨语言的平行语料,是制作于公元前196年的罗赛塔石碑(Rosetta Stone)上同时使用了古埃及文、古希腊文以及当地通俗文字,来记载古埃及国王托勒密五世登基的诏书。基于古希腊文的知识,语言学家可以很容易地根据这些平行语料理解原本艰涩难懂的古埃及文,这也是翻译的重大里程碑。



至于机器翻译的源头,基本上可以追溯至1949年,信息论研究者Warren Weave正式提出了机器翻译的概念。五年后,也就是1954年,IBM与美国乔治敦大学合作公布了世界上第一台翻译机——IBM-701。它能够将俄语翻译为英文,你别看他有巨大的身躯,事实上它里面只内建了6条文法规则,以及250个单词,但即使如此,这仍是技术的重大突破,那时人类开始觉得应该很快就能将语言的高墙打破。

可能是神察觉有异,又对人类重建巴别塔的计划泼了一桶冷水。1964年,美国科学院成立了语言自动处理咨询委员会(Automatic Language Processing Advisory Committee,简称ALPAC委员会)。两年后,在委员会提出的报告中认为机器翻译不值得继续投入,因为这份报告,造成接下来的十来年中,美国的机器翻译研究几乎完全停滞空白。
从IBM的第一台翻译机诞生到20世纪80年代,那时的技术主流都是基于规则的机器翻译,最常见的做法就是直接根据词典逐字翻译,虽然后来也有人倡议加入句法规则来修正,但是老实说,翻出来的结果都很令人沮丧,因为看起来蠢到极点,因此,到了80年代这样的做法就销声匿迹了。
为何语言没办法套用规则?因为语言是极其复杂且模糊的系统,从字的歧义到各种修辞,根本不可能穷举出所有规则。但有趣的是,不少现在近期投身于自然语言的新创公司,仍然很多企图用穷举规则来解决中文语义,总觉得自己的冰雪聪明能够完全覆盖语言规则体系,但这种想法铁定会是以失败告终的。

我在这举个例子来说明为何规则是不可行的,先别提翻译在两个语言转换的复杂性,光是从中文来说,“快递送货很快”这样的概念你能想到多少种讲法?10种?还是100种?在我们之前做过的自然语言统计数据来看,一共可能会有3600种讲法,而且这个数字应该还会随时间增加,光一个概念如此简单的句子就能有那么复杂的规则体系,若用到翻译恐怕规则量会是个惊人的天文数字,因此基于规则的机器翻译思路就成为了昨日黄花。

在全世界都陷入机器翻译低潮期,却有一个国家对于机器翻译有着强大的执念,那就是日本。日本人的英文能力差举世皆知,也因此对机器翻译有强烈的刚需。日本京都大学的长尾真教授提出了基于实例的机器翻译。也就是别再去想让机器从无到有来翻译,我们只要存上足够多的例句,即使遇到不完全匹配的句子,我们也可以比对例句,只要替换不一样的词的翻译就可以。这种天真的想法当然没有比基于的规则机器翻译高明多少,所以并未引起风潮。但是没多久,人类重建巴别塔的希望似乎又重见曙光。

引爆这波统计机器翻译热潮的还是IBM,在1993年发布的《机器翻译的数学理论》论文中提出了由五种以词为单位的统计模型,称为“IBM模型1”到“IBM模型 5”。(好吧……技术人员真的不太爱花时间取个响亮的名字)。
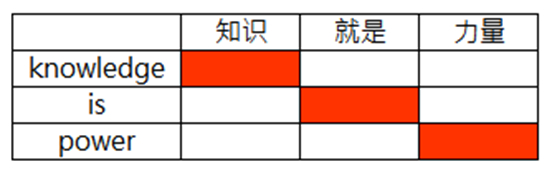
统计模型的思路是把翻译当成机率问题。原则上是需要利用平行语料,然后逐字进行统计,例如机器虽然不知道“知识”的英文是什么,但是在大多数的语料统计后,会发现只要有知识出现的句子,对应的英文例句就会出现“knowledge”这个字,如此一来,即使不用人工维护词典与文法规则,也能让机器理解单词的意思。
这个概念并不新,因为最早Warren Weave就提出过类似的概念,只不过那时并没有足够的平行语料以及限于当时计算器的能力太弱,因此没有付诸实行。现代的统计机器翻译要从哪里去找来“现代的罗赛塔石碑”呢?最主要的来源其实是联合国,因为联合国的决议以及公告都会有各个会员国的语言版本,但除此之外,要自己制作平行语料,以现在人工翻译的成本换算一下就会知道这成本高到惊人。
在过去十来年间,大家所熟悉的谷歌翻译都是基于统计机器翻译。听到这,应该大家就清楚统计翻译模型是无法成就通天塔大业的。在各位的印象中,机器翻译还只停留在“堪用”而非是“有用”的程度。但到了2014年,机器翻译迎来了史上最革命的改变——“深度学习”来了!

神经网络并不是新东西,事实上神经网络发明已经距今80多年了,但是自从2006年Geoffrey Hinton(即:深度学习三尊大神之首)改善了神经网络优化过于缓慢的致命缺点后,深度学习就不断地伴随各种奇迹似的成果频繁出现在我们的生活中。2015年,机器首次实现图像识别超越人类;2016年,Alpha Go战胜世界棋王;2017年,语音识别超过人类速记员;2018年,机器英文阅读理解首次超越人类。当然机器翻译这个领域也因为有了深度学习这个超级肥料而开始枝繁叶茂。
深度学习三大神中的Yoshua Bengio在2014年的论文中,首次奠定了深度学习技术用于机器翻译的基本架构,他主要是使用基于序列的递归神经网络(RNN),让机器可以自动捕捉句子间的单词特征,进而能够自动书写为另一种语言的翻译结果。此文一出,谷歌如获至宝,很快地,在谷歌供应充足火药以及大神的加持之下,谷歌于2016年正式宣布将所有统计机器翻译下架,神经网络机器翻译上位,成为现代机器翻译的绝对主流。
谷歌的神经网络机器翻译最大的特色是加入了注意力机制(attention),注意力机制其实就是在模拟人类翻译时,会先用眼睛扫过一遍,然后会挑出几个重点字来确认语义的过程,果然有了注意力机制加持后威力大增。谷歌宣称,在“英—法”,“英—中”,“英—西”等多个语对中,错误率跟之前的统计机器翻译系统相比降低了60%(可见之前问题多大)。
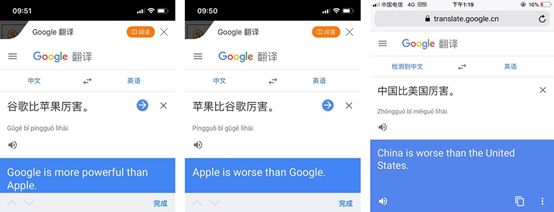
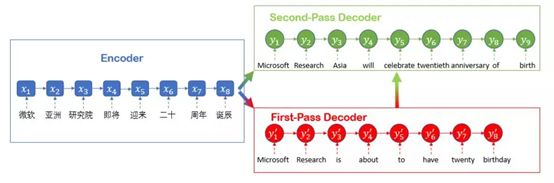
神经网络虽然可以根据现有的平行语料学习,理解句中细微的语言特征,但是它并非完美无缺,最大的问题来自于需要大量的语料以及它如黑盒子般的难以理解,也就是说,就算出了错也无从改起,只能够供应更多的正确语料来让“深度学习”改正。也因此同样一个句型,却可以有截然不同的翻译结果。(看看下图的三个翻译的例子,希望这只是谷歌内部的政治正确……)
今年2月,微软让机器语言理解超越人类后马上又有新举措,3月14日,微软亚洲研究院与雷德蒙研究院的研究人员宣布,其研发的机器翻译系统在通用新闻报道测试集newstest2017的中英翻译测试集上,达到了可与人工翻译媲美的水平。这自然是神经网络机器翻译的一大胜利,当然在架构上也有了不少创新,其中最值得注意的是加入了对偶学习(dual learning)以及推敲网络(Deliberation Networks)。
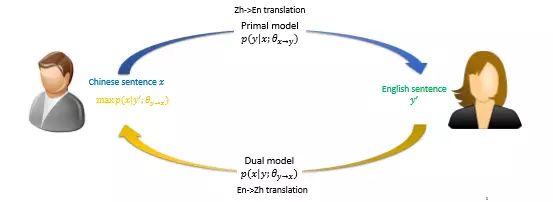
对偶学习要解决平行语料有限的问题,一般来说深度学习必须同时要提供给机器答案,这样机器才能够根据它的翻译结果与答案间的差异持续修正改进。
如果没有足够的平行语料,那机器该如何学习翻译呢?对偶学习给了个有趣的想法,以中英文翻译为例,那就直接把一个中翻英模型与英翻中模型铐在一起,一个中文句子先透过中翻英转换为英文,然后再把这句英文送进英翻中转换为中文,这时候只要两个模型齐心协力,让最终句子的中文输出与原来输入的中文句子相同,就表示两个翻译器都有正确的翻译能力。也因此,只要用平行语料训练有基本翻译能力的两个模型,接下来这两个模型就能够让对偶学习在没有平行语料的条件下持续精进。
至于推敲网络也是模仿人类翻译的过程,通常人工翻译会先做一次粗略的翻译,然后再将内容调整为精确的二次翻译结果,其实各位可以发现不管再聪明的神经网络,最终仍要参考地表上最聪明的生物,也就是身为人类的我们。

机器翻译的发展并不意味着未来翻译界人士将会没有饭吃了。可以注意到的是,微软发布会曾强调“通用新闻报道测试集newstest2017”的“中英翻译测试集”上,数据集表现好未必能与通用性划上等号,这也就可以说明为何腾讯翻译君明明平常口碑不错,但是为何在博鳌同传却表现失准。
同传可以说是翻译任务的顶点,除了要有正确听力理解原句,还要在有限的时间内转换为其他语言,而且别忘了讲者不会给翻译任何等待的时间,所以等于语音识别与机器翻译必须同步处理,再加上现场杂音、讲者的表达方式、语气词感叹词等等干扰因素都有可能会造成机器的误判。
就笔者看来,腾讯翻译君,可被指责的点可能只是不够用功,没有把关键的专有名词录入,这才会发生“一条公路和一条腰带”这种“经典错误”。
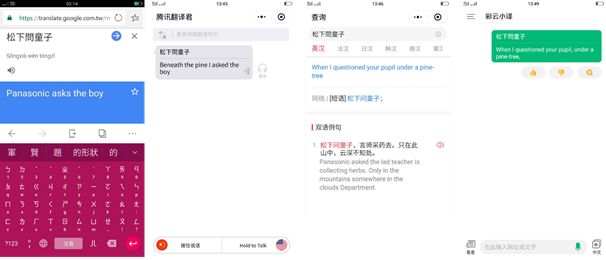
但是撇开同传,我用很经典的一个案例来测试谷歌翻译、腾讯翻译君、有道翻译官以及彩云小译,用了一句唐诗“松下问童子”。各位可以看到错误最明显的是谷歌,它翻译成了“松下电器问了童子”,而从翻译结果来看,腾讯翻译君与彩云小译都完全正确,有道翻译官只说对了一半,所以腾讯的翻译能力还是在业界水平之上的。
从这里也可以看到一个有趣的差异,为何西方机器翻译错得离谱,但是本国的机器翻译却几乎都能掌握原意?这是因为语言不能脱离人类的使用场景而存在,即我们语文学习中常强调的上下文(context),这来自于我们过去的文化、过去共有的记忆所构成的,没读过唐诗的谷歌自然无法理解这句诗的精髓。语言会是人工智能时代人类最后的壁垒,因为语言会因人类的使用不断地发生变化,这是机器很难完美替代的。
随着技术进步,终有一天,机器翻译会从“堪用”变成“有用”,再进化至“好用”,但就如同我过去几篇文章的论点一样,机器不会抢了人类的工作,能让人类失业的其实只有我们自己。如何善用人工智能成为自己的工具,把自己从无聊繁琐的工作中抽身,这才是面对未来的正确姿势。

作者为:Deepbelief人工智能科学家。华院数据科学家。2002年在中国台湾创立亚洲资采,台湾第一个大数据公司。

「 本文仅代表作者个人观点 」
「 图片 | 视觉中国 」



秦朔朋友圈微信公众号:qspyq2015
商务合作|请联系微信号:qspyqswhz
投稿、内容合作、招聘简历:friends@chinamoments.org

“阅读原文” 即可入学 “秦朔书院”
收听“中美商业文明通史”




