北大等NeurIPS新作:非诚实拍卖中效用与均衡的学习问题
本文是NeurIPS 2020)入选论文”Learning Utilities and Equilibria in Non-Truthful Auctions”的解读。
该论文分析了在(非完美信息的)首价拍卖等非诚实拍卖中估计买家的效用的样本复杂性,即需要多少个来自买家的估值分布的样本才能(以精度

引言
形式化
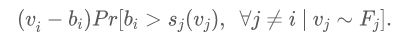
主要结果
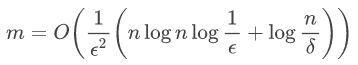
证明思路
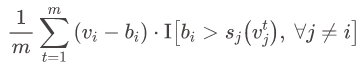
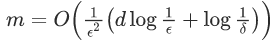 个样本,就能保证:以至少
个样本,就能保证:以至少
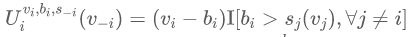 视为将其他买家的估值
视为将其他买家的估值
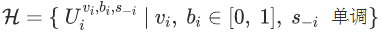 的 pseudo-dimension 不超过
的 pseudo-dimension 不超过
推论
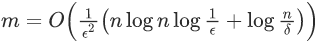 个样本,以
个样本,以
结论

点击阅读原文,直达NeurIPS小组!
登录查看更多
相关内容

Arxiv
8+阅读 · 2018年3月22日


相关VIP内容
相关资讯
相关论文
Arxiv
8+阅读 · 2018年3月22日