NLP模型一统推荐系统?谈新型推荐系统建模范式
今天跟大家推荐一篇Arxiv上的全新文章:Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5) [1]。标题非常吸引人。将推荐系统问题用自然语言处理框架来建模,提出了一种通用的建模框架,包含:预训练(Pretrain)、个性化提示学习(Personalized Prompt)、预测(Predict)的范式(Paradigm),简称为P5。

链接:https://arxiv.org/pdf/2203.13366
看到这篇文章标题的第一眼,笔者有如何疑问:
-
Q1:推荐系统问题复杂多样,如何用统一的NLP框架来建模?所有类型的推荐系统问题都能建模吗? -
Q2:用NLP的方式统一建模相比于现在的主流推荐系统有什么优势?作者的研究动机是啥? -
Q3:如何将推荐系统的样本user侧、item侧特征转成NLP模型的输入,user/item特征交互如何建模?个性化Prompts长什么样,该怎么用? -
Q4:下游应用时,如何将NLP模型用于推荐系统的预测和推断? -
Q5:在工业界具体场景中有哪些使用方式?能产生哪些可预见的收益?
笔者第一时间做了精读,且听下文分析。
更多关于推荐系统和NLP融合/借鉴的前序知识还可参见:
1.研究动机
推荐系统任务多样,例如:评分预测、点击率预估、转化率预估、序列推荐、推荐理由、对话系统等。不同的推荐系统任务通常需要特定的架构和学习目标进行建模。但不同任务之间实际上是有关联的,通常共享user或item集合,且上下文特征存在较大的重叠,割裂的建模方式导致不同任务之间蕴含的通用知识无法互相迁移,限制模型泛化到未知任务或样本的能力。
语言可以描述万物,当然也可以作为描述推荐系统任务的中间桥梁。受到近期关于多任务prompt学习的影响[2,3,4],本文提出了一种通用的text-to-text的框架,称为:Pretrain, Personalized Prompt, and Predict Paradigm(P5),将推荐系统问题用统一的基于prompt学习的sequence-to-sequence框架进行建模。
在P5中,推荐系统中的user-item交互行为数据、item的元数据、用户特征(如评论数据)被转成通用的"自然语言序列"格式,集成到个性化prompt模板中,作为模型的输入。在预训练阶段,P5使用统一的模型和目标来进行多任务预训练,因此拥有适用不同下游推荐任务的能力。
下游应用时,使用自适应的个性化prompts来实现“千人千面”,能够在下游任务中实现零样本或少样本泛化,省去微调工作。
P5的核心优势在于:
-
将推荐模型置身于”NLP环境“中,在个性化prompt的帮助下,重新形式化各类推荐系统任务输入为NLP语言序列。由于NLP模型在文本prompt模板特征上能够充分挖掘和表达语义,使得推荐系统可以充分捕获蕴含在训练语料中的知识。 -
P5将各类推荐系统问题融合在一个统一的Text-to-Text Encoder-Decoder架构,建模成条件文本生成问题,并使用相同的语言模型损失来预训练,而不是每个任务用特定的损失函数。 -
训练时使用instruction-based prompts,使得模型在下游应用时可以实现零样本或少样本泛化,比如泛化到其它领域或未见过的items,一定程度解决推荐系统的冷启动问题。
本文的核心贡献在于:
-
是第一个提出将各类推荐系统任务用统一的pretrain,prompt,predict的条件语言生成框架来建模。
-
提出了一系列个性化prompts,涵盖五类推荐系统任务。
-
在五种的推荐系统benchmarks,作者做了实验来阐明该方法的有效性。既能在训练时已知的prompt上表现很好,也具备零样本泛化的能力,在新的个性化prompt或新item上实现高质量的泛化。
作者表明希望本文的工作能够引领新一代推荐系统技术,通过本文提出的P5框架催生新的通用推荐引擎,并推动关于推荐系统问题看作自然语言处理过程以及相关的个性化基础模型的研究。
这个部分就能回答开篇的Q2问题:用NLP的方式统一建模相比于现在的主流推荐系统有什么优势?作者的研究动机是啥?
2.P5模型
P5模型一言以蔽之,将5类推荐系统任务(序列推荐、评分预测、推荐理由、评论、topK推荐)的输入样本通过设计的个性化prompts模板进行输入转换,转成自然语言序列,作为encoder端的输入;再将样本的label进行prompt转换作为decoder端的输出,通过sequence-to-sequence的语言模型损失函数进行预训练。下游应用时,给定目标输入,通过zero-shot的prompts模板进行输入转换,输入到encoder端进行编码,通过预训练好的decoder端进行解码,得到预测值,比如:下一次交互的item、评分、推荐理由、topK item ID等。
总之,个性化prompts模板作为桥梁,沟通了推荐系统任务的原始样本(特征/label)到通用自然语言序列的转换。多任务预训练学习到了不同任务内特定的知识以及任务间的迁移知识。
这个部分回答了开篇的Q1问题:推荐系统问题复杂多样,如何用统一的NLP框架来建模?所有类型的推荐系统问题都能建模吗?
2.1 基于个性化prompts生成输入样本
P5统一建模的5类推荐任务(序列推荐、评分预测、推荐理由、评论、直接推荐)如下图所示:
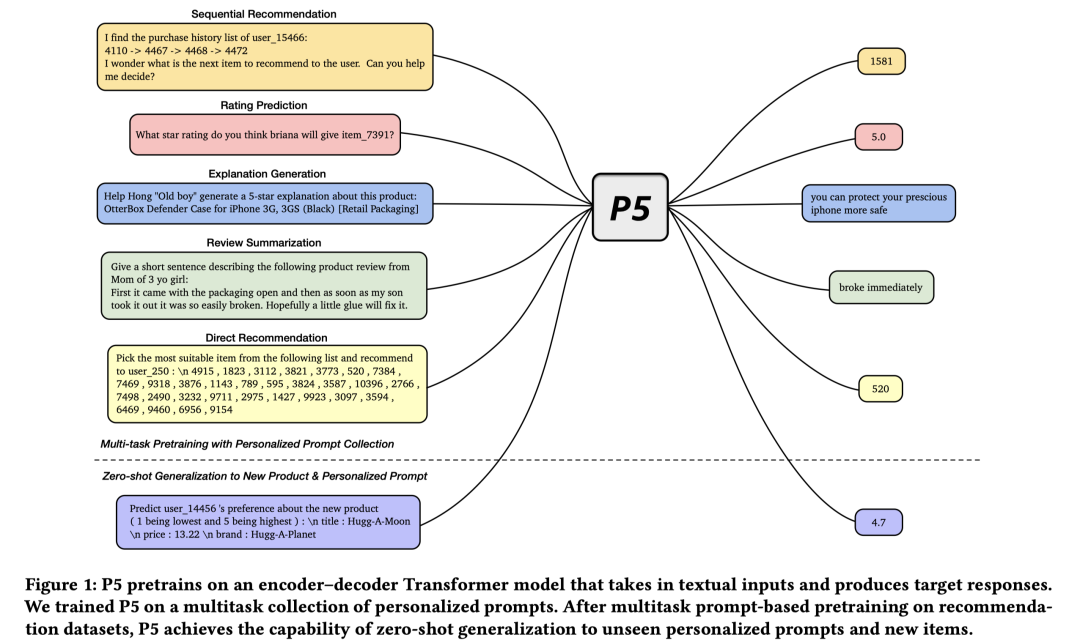
每类任务都有对应的个性化prompts模板,每个prompt包含如下三大要素:
-
输入模板(输入样本):input template,Encoder端输入。 -
目标模板(label):target template,Decoder输出。 -
关联的元数据(user/item特征):associated metadata,Encoder端{花括号}部分需要替换的内容。
所谓的个性化prompt是指prompt模板中融入了user/item的特征,不同的user,其prompt是不一样的。比如:user侧用ID、性别、年龄等特征来表达,这些特征取值不一样时,prompt就也不一样。同时,item特征变化时,模型的预测输出也会发生相应的变化,即:user对不同item的偏好是不一样的。
不同任务的prompts模板设计方式不一样,比如:
-
评分预测任务:包含3类,(a)给定关于user和item的信息,直接预测评分(1~5);(b)预测user是否会对item产生评分,即:yes or no;(c)预测user对item是否喜欢(>4分喜欢,否则不喜欢) -
序列推荐任务:包含3类,(a)直接基于交互历史,来预测下一次交互;(b)给定交互历史和候选item集合,从中选出某个item作为预测结果;(c)给定交互历史以及某个item,预测这个item用户是否下一次会进行交互。 -
推荐理由任务:包含2类,(a) 基于user和item的特征,直接生成推荐理由。(b) 将某个特征作为hint提示,生成推荐理由。 -
评论任务:包含2类,(a)对长评论进行摘要生成。(b)给定评论,预测对应的评分。 -
直接推荐:最常见的类型,类似TopK推荐。包含2类,(a) 预测是否要把某个item推荐给某个用户,yes or no。(b) 从候选集合中,选出某个item推荐给用户。
prompts原文附录共三页,考虑篇幅问题不贴在此,感兴趣可以直接去看原文,或直接公众号后台回复"prompts",发你3张截图速览。摘录几个例子:
-
评分预测任务:
Input template: Which star rating will user_{{user_id}} give item_{{item_id}}?
Target template: {{star_rating}} -
序列推荐任务:
Input template: Given the following purchase history of user_{{user_id}}:{{purchase_history}} predict next possible item to be purchased by the user?
Target template: {{next_item}} -
推荐理由任务:
Input template: Generate an explanation for user_{{user_id}} about this product: {{item_title}}
Target template: {{explanation}} -
评论任务:
Input template: Write a short sentence to summarize the following product review from user_{{user_id}}:{{review}}
Target template: {{summary}} -
直接推荐:
Input template: Will user_{{user_id}} likely to interact with item_{{item_id}}?
Target template: {{answer_choices[label]}} (yes/no) -
下游Zero-Shot泛化:(很强!)
Input template: Given the facts about the new product, do you think user {{user_id}} will like or dislike it? title: {{item_title}} brand: {{brand}} price: {{price}}
Target template: {{answer_choices[label]}} (like/dislike) – like (4,5) / dislike (1,2,3)
给定上述的prompts,很容易将推荐系统的原始输入数据转成input-target pairs,举几个从原始数据生成输入样本的例子。
如下图所示,最左侧是原始输入数据,包含user、item特征和推荐任务的label。中间是prompt模板,可以将花括号{}用具体的输入样本特征来替代,生成训练input-target pairs。右侧是target,用输入数据中的label来替换花括号。这样就能生成NLP任务encoder-decoder架构的输入-输出数据对。
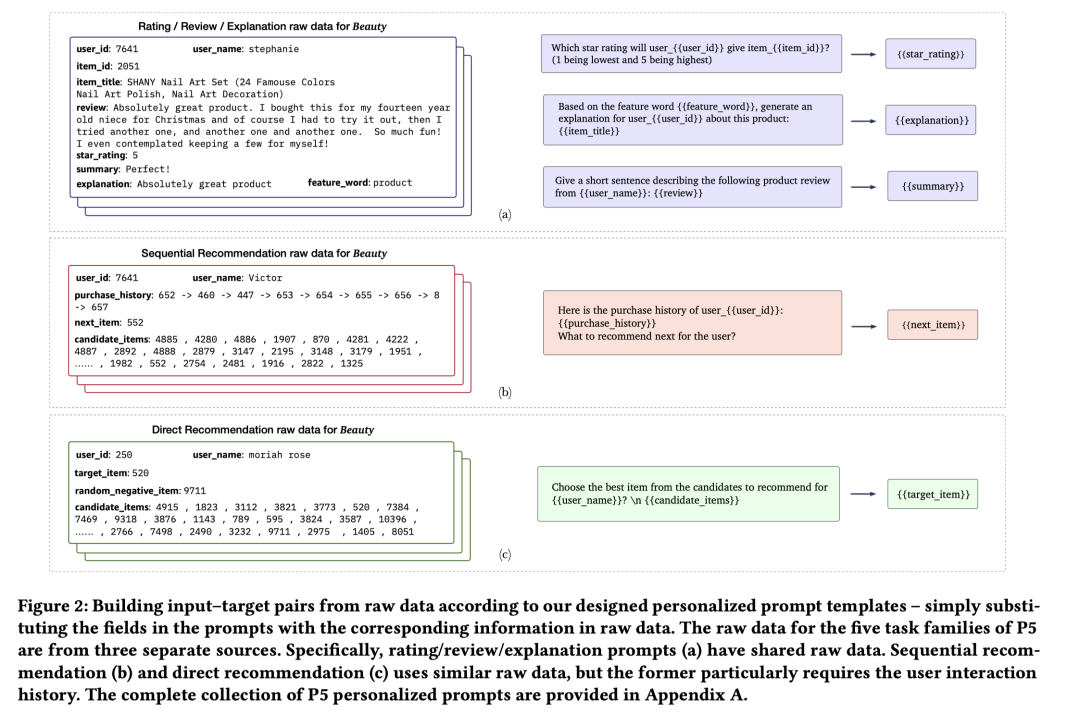
这个部分回答了开篇的Q3问题:如何将推荐系统的样本user侧、item侧特征转成NLP模型的输入,user/item特征交互如何建模?个性化Prompts长什么样,该怎么用?
2.2 模型结构
由于prompts的存在,所有任务的输入都巧妙地转换成了通用的自然语言序列,将各类任务之间的界限打破了,映射到统一的输入空间。在预训练的时候,将上述5种任务构造得到的input-target pairs全部混合起来喂给模型进行预训练。实际实现时,对每个raw data,会随机抽部分prompt模板进行输入样本的生成,保证泛化能力。在序列推荐和topK推荐的candidate items中,负样本会随机抽取。在这种多任务样本的预训练中,能够充分利用各类任务中蕴含的通用知识。下游应用时,即使是一些新颖、未见过的prompts或items,模型也能够很好地进行泛化和迁移。
模型架构上采用了家喻户晓的Encoder-Decoder结构,核心组成是Transformers。
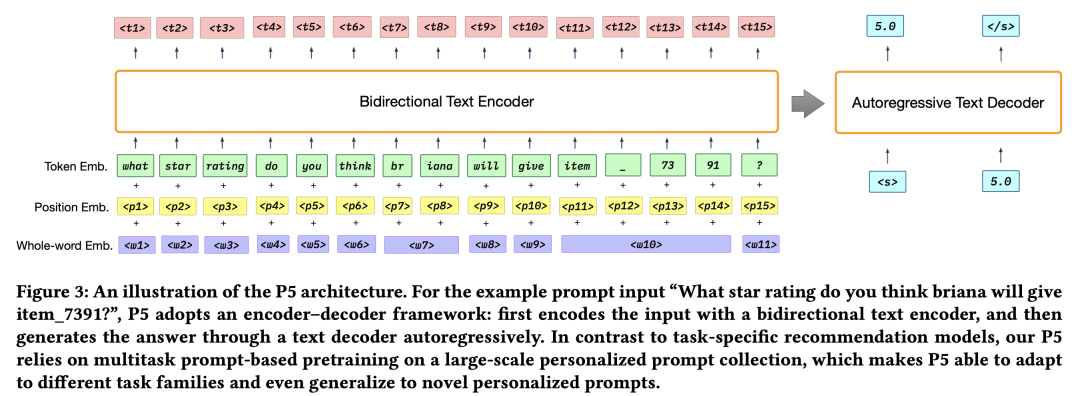
实际使用时,采用了T5预训练模型[5]。
2.2.1 输入层
Encoder的输入包括3个部分,token emb, position emb, whole-word emb,遵从类似BERT的输入范式。
-
token emb,输入token序列表示为: ,经过embedding。 -
position emb,位置嵌入,建模位置和次序信息。 -
whole-word emb,这个是文中提出的,主要为了解决可能把user/item侧的个性化特征切碎的问题,加入了整体的word表征。比如:item_7391是ID为7391的item,加个整体的embedding。实现上类似position emb,按顺序预留一个word idx embedding矩阵,根据输入中的需要进行查表。
三者加起来后作为Encoder的输入。这个部分实际上通过transformer来建模 中蕴含的user特征、item特征、user/item交互特征。
2.2.2 Encoder
采用的是transformers,可以对输入序列做双向attention。得到表征后的embedding序列,
2.2.3 Decoder
自回归decoder,允许对输入序列、已经解码的输出端序列做attention,并预测下一步的token。即:
2.2.4 预训练学习目标
预训练的学习目标是label tokens的负对数似然损失,训练样本是所有5种推荐任务混合起来的样本。
模型层面非常简洁,用one data format, one model, one loss来建模multi-task。
2.3 预测:下游推荐系统应用
预训练完后,可以直接应用在下游任务中,做zero-shot和few-shot。对于评分预测/推荐理由/评论任务,采用贪心算法进行解码即可。序列推荐和topk推荐通常需要输出一个item list,采用beam search来产生潜在topk结果。BeamSearch形式化如下:
BeamSearch输入为Decoder,Encoder的输出序列 和搜索的窗口大小B,输出预测的topk序列 。
具体使用时,还有一个很关键的是怎么得到输入序列 ?这里头就涉及到如何将原始的推荐系统测试样本映射到NLP模型的输入。
方法是仍然借用个性化prompts,以评分预测类任务为例:
-
一种是利用和训练时一样的prompts,将原始输入映射到训练时见过的prompts,
Input template: Does user_{{user_id}} like or dislike item_{{item_id}}?
Target template:{{answer_choices[label]}} (like/dislike) – like (4,5) / dislike (1,2,3) -
另一种是利用新的prompts,在训练时未见过,比如:
Input template: Given the facts about the new product, do you think user {{user_id}} will like or dislike it? title: {{item_title}} brand: {{brand}} price: {{price}}
Target template: {{answer_choices[label]}} (like/dislike) – like (4,5) / dislike (1,2,3)
后者实际上就对应着模型的强大泛化能力,比如给一个新的item和描述元信息,让模型来预测,实现item的冷启动;或者给定一个其它domain的测试样本做映射,让模型来预测,实现了跨域迁移学习。非常巧妙。
这个部分回答了开篇的Q4问题:下游应用时,如何将NLP模型用于推荐系统的预测和推断?
3.实验
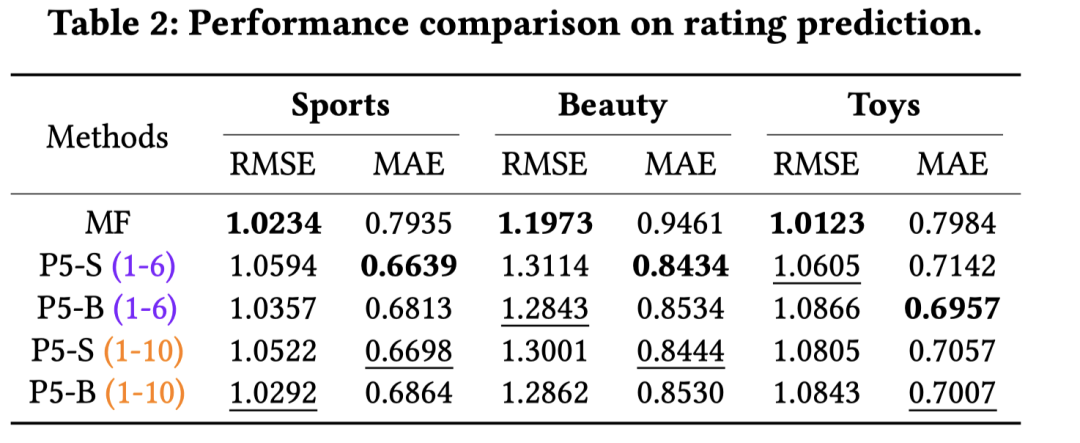
实验部分针对不同的任务,采用该任务下的SOTA模型进行对比。比如评分预测的MF、序列推荐的GRU4REC、BERT4REC等。预训练模型采用的是T5,包括base和small两个checkpoint,分别对应P5-B和P5-S。比如实验中的P5-S(1-6)代表用small T5版本的预训练模型做参数初始化,用第1~6种prompts做样本生成。各类任务对比实验指标如下:
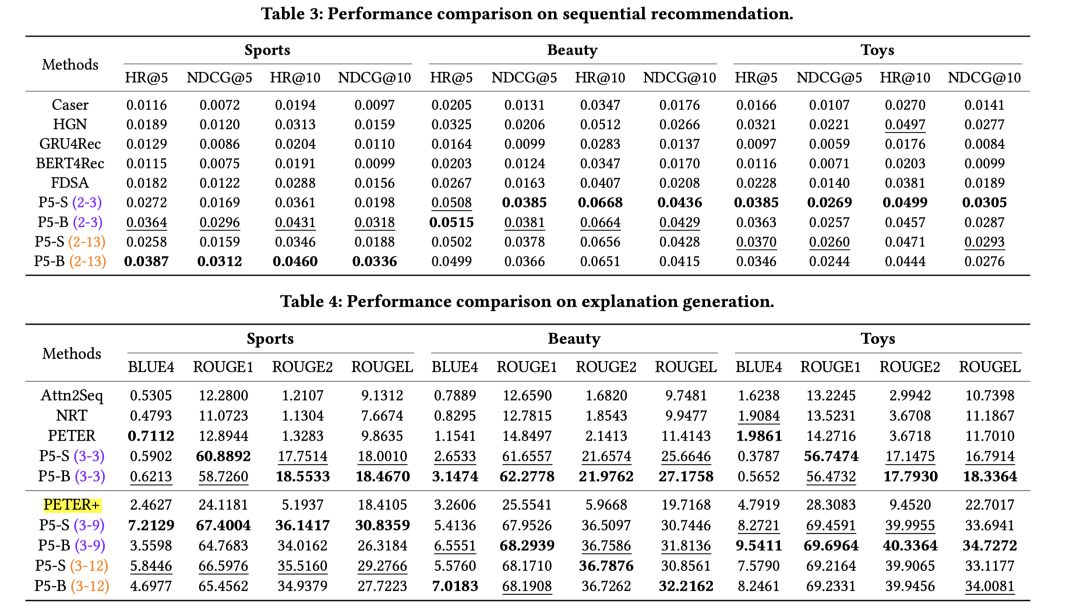
4.评价
总体而言,笔者觉得这篇文章非常有意思,很简洁,one data format, one model, one loss for multi-task。
这个部分主要想回答开篇的Q5:在工业界具体场景中有哪些使用方式?能产生哪些可预见的收益?
笔者认为这篇文章的工作可以启发不少推荐系统应用,包括:多任务学习、多领域迁移学习、表征学习、冷启动等。文章主要是使用了zero-shot和few-shot的应用方式,但实际上也可以做特征提取器或者微调。比如:
可以考虑为每种任务或领域设计适配的个性化prompts,然后用统一的NLP模型进行多任务预训练。下游应用时,既可以zero-shot或者few-shot做召回或冷启;也可以考虑提取encoder端的输出作为通用的知识表征,作为特定推荐系统任务的特征输入,或进行微调;也可以用于改进现有的多任务多domain模型,融入这种通用对齐的多领域语义特征。
当然,对于预训练和微调的边界的说明,笔者有疑问,本质上文中说的多任务预训练,实际上是通常的prompt tuning的过程。同时缺点在于要人工设计很多prompts模板,这些模板不一定是最优的。因此,作者也提到,未来优化方向上,也可以考虑PETER类似的连续prompt learning或prompts自动搜索生成等工作。
参考文献
[1] Geng S, Liu S, Fu Z, et al. Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)[J]. arXiv preprint arXiv:2203.13366, 2022.
[2] Vamsi Aribandi, Yi Tay, Tal Schuster, Jinfeng Rao, Huaixiu Steven Zheng, Sanket Vaibhav Mehta, Honglei Zhuang, Vinh Q. Tran, Dara Bahri, Jianmo Ni, Jai Gupta, Kai Hui, Sebastian Ruder, and Donald Metzler. 2022. ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning. In International Conference on Learning Representations.
[3] Victor Sanh, Albert Webson, Colin Raffel, Stephen Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal Nayak, Debajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala Neeraj, Jos Rozen, Abheesht Sharma, Andrea Santilli, Thibault Fevry, Jason Alan Fries, Ryan Teehan, Teven Le Scao, Stella Biderman, Leo Gao, Thomas Wolf, and Alexander M Rush. 2022. Multitask Prompted Training Enables Zero-Shot Task Generalization. In International Conference on Learning Representations.
[4] Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V Le. 2022. Finetuned Language Models are Zero-Shot Learners. In International Conference on Learning Representations.
[5] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits Recommendation as Language Processing of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research 21, 140 (2020), 1–67. http://jmlr.org/papers/v21/20-074.html
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。

