2021 推荐系统领域最新研究进展

强化学习用于推荐
Arxiv 2021 | Locality-Sensitive Experience Replay for Online Recommendation
RL4RS : A Real-World Benchmark for Reinforcement Learning based Recommender System
跨域推荐
WSDM 2022 | Personalized Transfer of User Preferences for Cross-domain Recommendation
联邦学习用于推荐
WSDM 2022 | PipAttack: Poisoning Federated Recommender Systems for Manipulating Item Promotion
序列推荐
WSDM 2022 | Sequential Modeling with Multiple Attributes for Watchlist Recommendation in E-Commerce
CTR
Arxiv 2021 | AEFE: Automatic Embedded Feature Engineering for Categorical Features
多模态推荐
Arxiv 2021 | MultiHead MultiModal Deep Interest Recommendation Network
对比学习用于推荐
ICDM 2021 | Learning Transferable User Representations with Sequential Behaviors via Contrastive Pre-training
预训练预言模型用于推荐
Arxiv 2021 | Finetuning Large-Scale Pre-trained Language Models for Conversational Recommendation with Knowledge Graph
DMS 2021 | Intent-based Product Collections for E-commerce using Pretrained Language Models
冷启动推荐
TOIS 2021 | Learning to Learn a Cold-start Sequential Recommender
重排序 Reranking
Arxiv 2021 | Context-aware Reranking with Utility Maximization for Recommendation
learning-to-rank
Arxiv 2021 | A scale invariant ranking function for learning-to-rank: a real-world use case
推荐系统Debias
Arxiv 2021 | Revisiting Popularity and Demographic Biases in Recommender Evaluation and Effectiveness
Arxiv 2021 | Toward Annotator Group Bias in Crowdsourcing
其他
WSDM 2022 | Show Me the Whole World: Towards Entire Item Space Exploration for Interactive Personalized Recommendations
Arxiv 2021 | Learning to Recommend Using Non-Uniform Data
IRS KDD workshop 2021 | Two-stage Voice Application Recommender System for Unhandled Utterances in Intelligent Personal Assistant
机器学习领域部分文章
Arxiv 2021 | Graph Condensation for Graph Neural Networks
强化学习用于推荐
Arxiv 2021 | Locality-Sensitive Experience Replay for Online Recommendation
https://arxiv.org/pdf/2110.10850.pdf
在线推荐需要处理快速变化的用户偏好。深度强化学习(DRL)作为一种在与推荐系统交互过程中捕捉用户动态兴趣的有效手段,正在受到人们的关注。然而,由于状态空间大(如用户物品评分矩阵和用户档案)、动作空间大(如候选物品)和奖励稀疏,训练DRL代理具有挑战性。现有的研究鼓励实施者通过经验重放(ER)从过去的经验中学习。然而他们不能很好地适应在线推荐系统的复杂环境,而且不能根据过去的经验来确定最佳策略。为了解决这些问题,作者设计了一个新的状态感知经验重放模型,该模型使用位置敏感哈希将高维数据映射到低维表示,并使用优先奖励驱动策略以更高的机会重放更有价值的经验。本文的模型可以选择最相关和最显著的经验,并推荐策略最优的代理。在三个在线仿真平台上的实验证明了该模型的可行性和优越性。
RL4RS : A Real-World Benchmark for Reinforcement Learning based Recommender System
https://arxiv.org/pdf/2110.11073.pdf
https://github.com/fuxiAIlab/RL4RS
基于强化学习的推荐系统(Reinforcement learning based RS, RL-based RS)旨在从一批收集的数据中学习到一个好的策略,并将序列推荐应用到多步决策任务中。然而,目前基于RL的RS基准测试普遍存在较大的现实差距,因为它们涉及人工RL数据集或半模拟RS数据集,训练后的策略直接在仿真环境中进行评估。在现实世界中,并不是所有的推荐问题都适合转化为强化学习问题。与以往的RL学术研究不同,基于RL的RS存在外推误差,而且在部署前很难得到很好的验证。在本文中,本文介绍了RL4RS(推荐系统强化学习)基准——一个从工业应用中完全收集的新资源,用于训练和评估RL算法。它包含两个数据集、调优的模拟环境、相关的高级RL基线、数据理解工具和反事实策略评估算法。RL4RS套装可以在https://github.com/fuxiAIlab/RL4RS中找到。除了基于RL的推荐系统,作者希望此资源有助于加强学习和神经组合优化的研究。
跨域推荐
WSDM 2022 | Personalized Transfer of User Preferences for Cross-domain Recommendation
https://arxiv.org/pdf/2110.11154.pdf
https://github.com/easezyc/WSDM2022-PTUPCDR
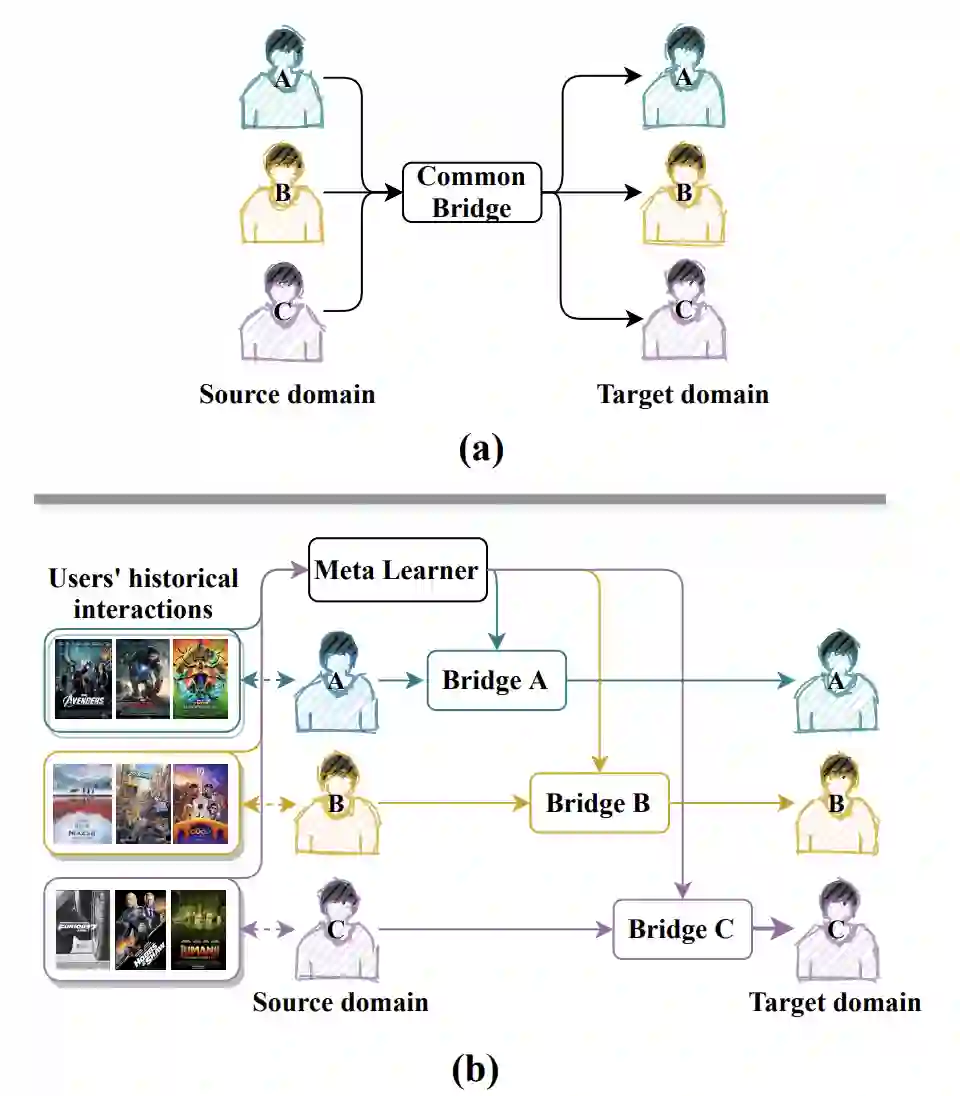
冷启动问题在推荐系统中仍然是一个非常具有挑战性的问题。幸运的是,辅助源域中的冷启动用户之间的交互可以帮助目标域中的冷启动推荐。跨域推荐(Cross-domain Recommendation, CDR)是解决冷启动问题的一种有效方法,如何将用户的偏好从源域转移到目标域是关键问题。大多数现有方法建模一个公共偏好桥接器(preference bridge),为所有用户迁移偏好。从直观上看,由于用户的偏好不同,不同用户的偏好桥梁也应该不同。在此基础上,本文提出了一种新的跨域推荐用户偏好个性化转移框架(Personalized Transfer of User Preferences for Cross-domain Recommendation,PTUPCDR)。具体来说,学习一个元网络,以用户的特征嵌入为输入源,生成个性化的偏好迁移函数,实现每个用户的个性化偏好转移。为了稳定地学习元网络,作者采用了一个面向任务的优化过程。利用元生成的个性化桥函数,可以将源域的用户偏好嵌入转化为目标域,转化后的用户偏好嵌入可作为冷启动用户在目标域的初始嵌入。使用大量的真实数据集,本文进行了大量的实验来评估PTUPCDR在冷启动和暖启动阶段的有效性。
联邦学习用于推荐
WSDM 2022 | PipAttack: Poisoning Federated Recommender Systems for Manipulating Item Promotion
https://arxiv.org/pdf/2110.10926.pdf
由于越来越多的隐私问题,去中心化在个性化服务中迅速出现,尤其是推荐。此外,最近的研究表明,集中式模型很容易受到攻击,危及其完整性。在推荐系统的环境中,这种攻击的典型目标是通过干扰训练数据集和/或过程来促进对手的目标物品。因此,一种常见的做法是将推荐系统纳入到去中心化的联邦学习范式下,这使得所有用户设备能够协同学习全局推荐,同时保留所有敏感数据。在不向最终用户公开推荐人和整个数据集的全部知识的情况下,这种联合推荐被广泛认为是对中毒攻击“安全的”。在本文中,作者提出了一个系统的方法,后门联邦推荐系统的目标物品推荐。核心策略是利用数据驱动推荐中普遍存在的固有的popularity bias。由于热门商品更容易出现在推荐列表中,作者创新设计的攻击模型使目标商品在嵌入空间中具有热门商品的特征。然后,通过在模型更新期间通过少数恶意用户上传精心制作的梯度,我们可以有效地增加联邦推荐中目标(不受欢迎)物品的曝光率。对两个真实世界的数据集的评估表明:1)本文的攻击模型以一种隐秘的方式显著提高了目标物品的曝光率,而不会损害推荐的准确性;2)现有的防御措施不够有效,这就突出了针对联邦推荐系统的本地模型攻击的新防御措施的必要性。
序列推荐
WSDM 2022 | Sequential Modeling with Multiple Attributes for Watchlist Recommendation in E-Commerce
https://arxiv.org/pdf/2110.11072.pdf
在电子商务中,watchlist使用户能够随着时间的推移跟踪商品,并已成为一项主要功能,在用户的购物过程中发挥着重要作用。watchlist物品通常有多个属性,其值可能随时间而变化(例如,价格、数量)。由于许多用户在他们的watchlist中积累了几十个物品,而且由于购物意图会随着时间的推移而改变,在给定的环境中推荐最重要的watchlist物品可能是有价值的。本文研究了电子商务中的watchlist功能,并引入了一种新的watchlist推荐任务。我们的目标是通过预测用户将点击的下一个物品,来确定用户下一步应该注意哪些watchlist物品的优先级。我们将此任务转换为一个专门的序列推荐任务,并讨论其特征。我们提出的推荐模型Trans2D构建在Transformer架构之上,其中我们进一步提出了一种新的扩展注意机制(Attention2D),它允许从具有多个物品属性的序列数据中学习复杂的物品-物品、属性-属性和物品-属性模式。使用来自eBay的大规模watchlist数据集,我们评估了我们提出的模型,在其中我们展示了它与多个最先进的基线相比的优越性,其中许多基线适用于这项任务。
CTR
Arxiv 2021 | AEFE: Automatic Embedded Feature Engineering for Categorical Features
https://arxiv.org/abs/2110.09770
在电子商务应用中,如推荐系统(RS)和点击率(CTR)预测等数据挖掘问题的解决面临的挑战是如何在保持方法可解释性的前提下,从大量类别特征中构建组合特征来进行推理。在本文中,作者提出了自动嵌入式特征工程(Automatic Embedded Feature Engineering, AEFE),一个表示类别特征的自动特征工程框架,它由自定义范式特征构建和多个特征选择等组成。通过智能地选择潜在域对(field pairs)并生成一系列可解释的组合特征,该框架可以提供一组不可见的生成特征,以提高模型性能,并帮助数据分析人员发现特定数据挖掘任务中特征的重要性。在此基础上,通过任务并行、数据采样和基于矩阵分解字段组合的搜索模式实现了AEFE的分布式实现,优化了框架的性能,提高了框架的效率和可扩展性。在一些典型的电子商务数据集上进行的实验表明,该方法优于经典的机器学习模型和最新的深度学习模型。
多模态推荐
Arxiv 2021 | MultiHead MultiModal Deep Interest Recommendation Network
https://arxiv.org/pdf/2110.10205.pdf
随着信息技术的发展,人类每时每刻都在不断地产生大量的信息。如何从海量的信息中获取用户感兴趣的信息,已经成为用户乃至企业管理者非常关注的问题。为了解决这一问题,从传统的机器学习到深度学习推荐系统,研究者不断完善优化模型并探索解决方案。由于研究人员对推荐模型网络结构的优化较多,对丰富推荐模型特征的研究较少,仍有深入的推荐模型优化空间。在DIN模型的基础上,增加了多头多模态模块(MultiHead MultiModal),丰富了模型可以使用的特征集,同时增强了模型的交叉组合和拟合能力。实验表明,多头多模态DIN提高了推荐预测效果,在各项综合指标上优于现有的先进方法。
对比学习用于推荐
ICDM 2021 | Learning Transferable User Representations with Sequential Behaviors via Contrastive Pre-training
https://fajieyuan.github.io/papers/ICDM2021.pdf
从顺序的用户-物品交互中学习有效的用户表示是推荐系统(RS)的一个基本问题。近年来,针对pre-training用户表示的非监督方法得到了广泛的研究。一般来说,这些方法采用了类似的学习模式,首先破坏行为序列,然后使用某些物品级预测损失函数恢复原始输入。尽管它的有效性,我们认为在物品级优化目标和用户级表示之间存在着重要的差距,因此,学习的用户表示可能只会导致次优泛化性能。在本文中,我们提出了一个新的自监督的预训练框架,称为CLUE,它使用对比学习建模序列级用户表示。CLUE的核心思想是将每个用户行为序列作为一个整体,通过数据增强(data augmented, DA)对原始用户行为进行转换,构建自监督信号。具体来说,我们使用两个Siamese(权重共享)网络来学习面向用户的表示,其中优化目标是最大化这两个编码器对同一用户的学习表示的相似性。更重要的是,我们从更全面的角度,仔细研究了视图生成策略对用户行为输入的影响,包括使用显式数据增强策略处理顺序行为和使用dropout作为隐式数据增强。为了验证CLUE的有效性,我们在几个不同规模和特征的用户相关任务上进行了大量的实验。我们的实验结果表明,在多个评估指标下,CLUE学习到的用户表示超过了现有的物品级基线。
预训练预言模型用于推荐
Arxiv 2021 | Finetuning Large-Scale Pre-trained Language Models for Conversational Recommendation with Knowledge Graph
https://arxiv.org/pdf/2110.07477.pdf
https://github.com/Lingzhi-WANG/PLM-BasedCRS
本文提出了一种基于预训练语言模型(pre-trained language model, PLM)的会话推荐系统(conversational recommender system, CRS),称为RID框架。RID对大规模的预训练语言模型(如DialoGPT)进行微调,并结合预训练的关系图卷积网络(Relational Graph Convolutional Network,RGCN)来编码面向物品的知识图谱的节点表示。前者基于PLM强大的语言生成能力,生成流畅多样的对话响应,后者通过学习结构知识库上更好的节点嵌入,促进物品推荐。为了将对话生成和物品推荐两个模块统一到基于PLM的框架中,作者扩展了PLM的生成词汇表,增加了额外的物品词汇表,并引入了词汇表指针来控制何时在生成过程中推荐目标物品。在基准数据集ReDial上的大量实验表明,在对话评估和推荐方面,RID显著优于最先进的方法。
DMS 2021 | Intent-based Product Collections for E-commerce using Pretrained Language Models
https://arxiv.org/pdf/2110.08241.pdf
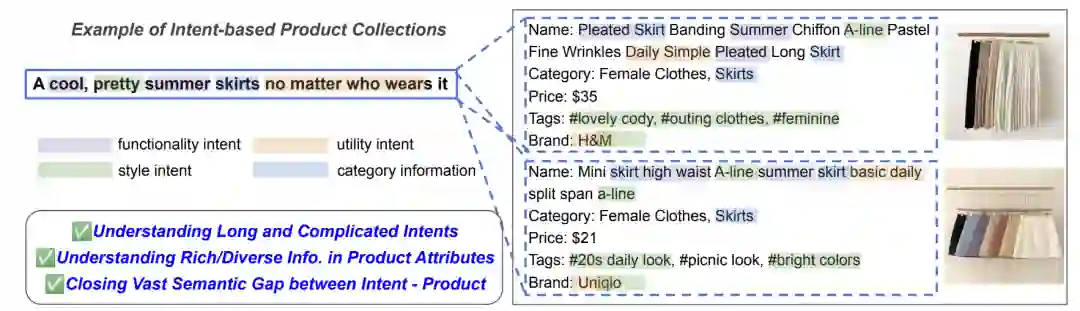
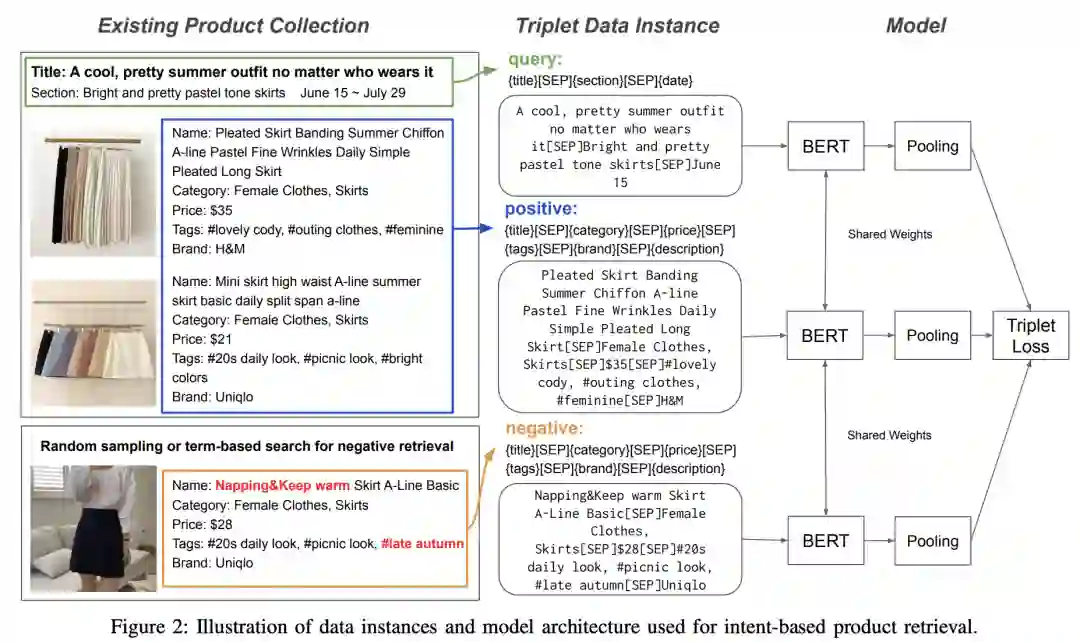
产品集合(product collection)通常是专家们通过手工的方式收集‘相关性高、多样、购物意向一致、一起展示效果好’的商品,如背包、笔记本电脑包、新生礼品包等。自动构建这样的产品集合需要机器学习系统来了解客户的意图和产品属性之间的复杂关系。然而,这存在一些难点,如1)意图句长而复杂,2)产品属性丰富而多样,3)它们之间存在巨大的语义鸿沟,这些都使得问题变得困难(如上图所示)。在本文中,作者使用预训练语言模型(PLM),利用电商物品的文本属性来制作基于意图的产品集合。具体来说,作者通过将意图句设置为锚,将相应产品设置为正例来训练具有triplet loss的BERT。此外,作者还通过基于搜索的负采样和相同类别的正样本对增强来提高模型的性能(如下图所示)。在基于意图的产品匹配的离线评估中,作者的模型显著优于基于搜索的基线模型。此外,在电子商务平台上的在线实验结果表明,与专家手工收集相比,基于PLM的方法可以构建具有更高CTR、CVR和order-diversity的产品集合。
冷启动推荐
TOIS 2021 | Learning to Learn a Cold-start Sequential Recommender
https://arxiv.org/abs/2110.09083
冷启动推荐是当前在线应用中亟待解决的问题。它的目标是为那些行为稀疏的用户提供尽可能准确的推荐。许多数据驱动算法,如广泛使用的矩阵分解算法,由于数据稀疏而表现不佳。本文采用元学习的思想来解决用户的冷启动推荐问题。我们提出了一种基于元学习的冷启动顺序推荐框架(metaCSR),该框架包括三个主要组成部分:1)扩散表示,通过交互图上的信息扩散更好地学习用户/物品嵌入;2)序列推荐用于捕获行为序列的时间依赖性;3)元学习器用于提取和传播先前用户的可迁移的知识,并为新用户学习良好的初始化。metaCSR拥有从普通用户的行为中学习通用模式并优化初始化的能力,以便模型在一次或几次梯度更新后能够快速适应到新用户,以实现最优性能。在三个广泛使用的数据集上进行的大量定量实验表明,metaCSR在处理用户冷启动问题方面具有显著的性能。同时,一系列定性分析表明,所提出的元acsr具有良好的泛化能力。
重排序 Reranking
Arxiv 2021 | Context-aware Reranking with Utility Maximization for Recommendation
https://arxiv.org/abs/2110.09059
作为大型商业推荐系统的一项关键任务,重排序(Rerank)显示出通过发现物品之间的相互影响来改善推荐结果的潜力。重排序是对上一排序阶段的初始排序列表中的物品进行重新排序,以更好地满足用户的需求。然而,与其像大多数现有方法那样考虑初始列表的上下文,理想的重新排序算法更应该考虑反事实的上下文(重排序列表中物品的位置和对齐方式)。在本文中,作者提出了一种新的pairwise reranking框架,即上下文感知的推荐效用最大化重排序(CRUM),它能有效地最大化重新排序后的整体效用。具体来说,作者首先设计了一个面向效用的评估器,该评估器应用Bi-LSTM和图注意机制,通过反事实上下文建模来评估列表效用。然后,在评估器的指导下,作者提出了一个pairwise的重排序模型,通过交换错位的物品对来找到每个物品最合适的位置。在两个基准数据集和一个专有的真实数据集上进行的广泛实验表明,CRUM在基于相关性的指标和基于实用性的指标方面都显著优于最先进的模型。
learning-to-rank
Arxiv 2021 | A scale invariant ranking function for learning-to-rank: a real-world use case
https://arxiv.org/abs/2110.11259
目前,在线旅行社主要提供度假、商务旅行、住宿预订等服务。在许多涉及用户、商品和偏好的电子商务服务中,推荐系统的使用促进了市场的导航。在生产机器学习模型(在本例中是learning-to-rank的模型)的主要挑战之一是,不仅需要一致的预处理转换,而且还需要在训练和预测时保持类似规模的输入特征。然而,特性的规模在现实生产环境中不一定保持不变,这可能会导致意想不到的排序。特征标准化、批处理标准化和层标准化等标准化技术常用来解决缩放问题。然而,这些技术在现实世界的web应用程序中有时是不可行的。首先,成千上万项特征的标准化会显著影响网站延迟。其次,物品得分的实时推断通常分布在生产环境的多台机器上,因此要求所有物品的信息都可用的listwise操作很难实现。为了解决这一问题,本文提出了一种新的尺度不变排序函数(scale-invariant ranking function,SIR),该函数是通过深度神经网络和广域神经网络相结合来实现的。我们将SIR与五种最先进的learn-to-rank模型结合起来,并在一个包含来自这个Hotels.com网站的5600万酒店搜索的大数据集上,将组合模型与经典算法的性能进行比较。此外,我们模拟了四个真实场景,其中测试集的特征规模与训练集的特征规模不一致。结果表明,当预测时特征尺度不一致时,结合SIR的Learning-To-Rank方法在所有情景下都优于原始方法(性能差异高达14.7%)。而当训练集和测试集的特征尺度一致时,我们的算法达到了与经典算法相当的准确率。
推荐系统Debias
Arxiv 2021 | Revisiting Popularity and Demographic Biases in Recommender Evaluation and Effectiveness
https://arxiv.org/pdf/2110.08353.pdf
推荐算法很容易受到流行度的影响:即使热门商品不能满足用户的需求,也会推荐它们。一个相关的问题是,推荐质量可能因人口群体而异。与其他算法相比,边缘化群体或训练数据中代表性不足的群体可能从这些算法中得到的相关推荐较少。在最近的一项研究中,Ekstrand[1]等人调查了推荐性能如何根据受欢迎程度和人口统计数据而变化,并在两个数据集中发现了性别在推荐效用上的显著差异,在一个数据集中发现了基于年龄的显著影响。在这里,本文重现了这些结果,并通过额外的分析扩展它们。本文发现,年龄和性别在推荐表现上存在显著差异。我们观察到,年长用户的推荐效用会稳步下降,女性用户的推荐效用低于男性用户。本文还发现,来自数据集中具有更多代表性的国家的用户的效用更高。此外,本文发现,总使用量和消费内容的受欢迎程度是推荐性能的强大预测指标,而且在人口统计学群体中也存在显著差异。
Arxiv 2021 | Toward Annotator Group Bias in Crowdsourcing
https://arxiv.org/pdf/2110.08038.pdf
Crowdsourcing已经成为一种流行的方法,用于收集带注释的数据,以训练有监督的机器学习模型。然而,注释者偏见可能会导致有缺陷的注释。虽然对个体注释者偏见的研究较少,但注释者的群体效应在很大程度上被忽视了。在本研究中,我们发现同一人口统计群体中的注释者倾向于在注释任务中表现出一致的群体偏见,因此我们对注释者群体偏见进行了初步研究。我们首先在现实世界的众包数据集中验证了标注者群体偏差的存在。然后,我们开发了一种新的概率图形框架GroupAnno来捕获注释者群体偏差,并引入了一种新的扩展的期望最大化(EM)训练算法。我们在合成数据集和真实数据集上进行实验。实验结果表明,该模型在标签聚合和竞争基线模型学习中的标注者群体偏差建模方面是有效的。
其他
WSDM 2022 | Show Me the Whole World: Towards Entire Item Space Exploration for Interactive Personalized Recommendations
https://arxiv.org/pdf/2110.09905.pdf
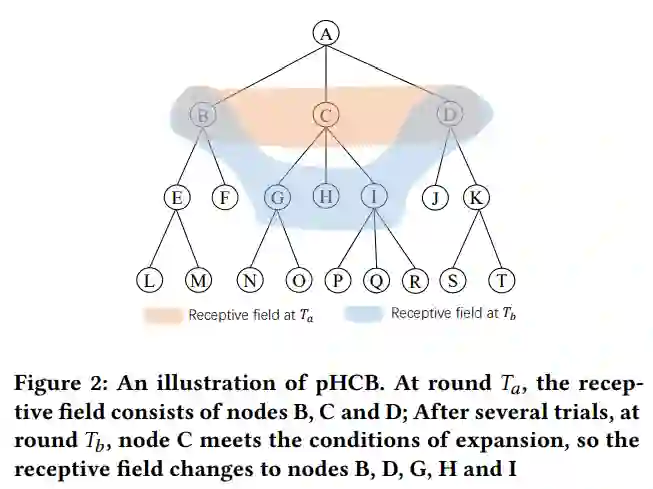
用户兴趣挖掘是推荐系统中一个重要且具有挑战性的课题,它缓解了推荐模型与用户-商品交互之间的闭环效应。Contextual bandit(CB)算法努力在探索和开发之间做出良好的权衡,以便让用户的潜在兴趣有机会暴露出来。然而,经典的CB算法只能应用于一个小的、抽样的物品集(通常是数百个),这使得推荐系统中的典型应用局限于candidate post-ranking, homepage top item ranking, ad creative selection, or online model selection (A/B test)。
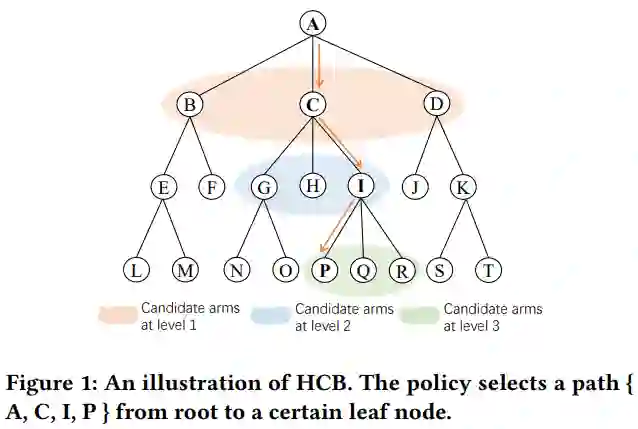
在本文中,作者引入了两种简单但有效的分层CB算法,使经典CB模型(如LinUCB和Thompson Sampling)能够探索用户对整个物品空间的兴趣,而不局限于一个小物品集。作者首先通过自底向上的聚类算法构造一个层次的物品树,以从粗到细的方式组织物品。在此基础上,提出了一种基于层次树的用户兴趣挖掘算法。HCB将探索问题作为一系列决策过程,目标是找到从根节点到叶节点的路径,并将反馈反向传播到路径中的所有节点。作者进一步提出了一种渐进分层CB (pHCB)算法,该算法逐步扩展可见节点,使其达到探索的置信度,以避免在顺序决策过程中对上层节点的误导行为。作者在两个公共推荐数据集上的大量实验证明了方法的有效性和灵活性。
<<< 左右滑动见更多 >>>
Arxiv 2021 | Learning to Recommend Using Non-Uniform Data
https://arxiv.org/pdf/2110.11248.pdf
根据用户过去的购买或评论来了解他们对产品的偏好是现代推荐引擎的基石。在这个学习任务中,一个复杂的问题是,有些用户更有可能去购买或评论产品,而有些产品相比别的产品更有可能被用户购买或评论。这种不均匀的模式降低了许多现有推荐算法的能力,因为它们假设观测数据是在用户-产品对之间均匀随机抽样的。另外,现有的关于建模不一致性的文献要么假设用户的兴趣是独立于产品的,要么缺乏理论理解。本文首先将用户产品偏好建模为具有非均匀观测模式的部分观测矩阵。其次,在低秩矩阵估计文献的基础上,引入一种新的加权迹范数惩罚回归来预测矩阵的未观测值。然后我们证明了我们所提出的方法的预测误差的上界。我们的上界是一个基于某个权重矩阵的参数的函数,该权重矩阵依赖于用户和产品的联合分布。利用这一观察,我们引入一个新的优化问题来选择一个权值矩阵,使预测误差的上界最小。最终的产品是一个新的估计器NU-Recommend,它在合成和真实数据集上都优于现有的方法。
IRS KDD workshop 2021 | Two-stage Voice Application Recommender System for Unhandled Utterances in Intelligent Personal Assistant
https://arxiv.org/abs/2110.09877
智能个人助理(IPA)支持语音应用程序,方便人们的日常任务。然而,由于语音请求的复杂性和模糊性,标准自然语言理解(NLU)组件可能无法正确处理一些请求。在这种情况下,像“对不起,我不知道”这样的简单回答会损害用户的体验,并限制IPA的功能。在本文中,作者提出了一个两阶段推荐系统,以匹配第三方语音应用(技能)到未处理的话语。在这种方法中,提出了一个技能筛选器,通过计算技能和用户请求之间的词汇和语义相似度,从技能目录中检索候选技能。作者还演示了如何使用从基于规则的基线系统中收集的观测数据来构建一个新系统,以及暴露偏差如何产生离线和人类指标之间的差异。最后,作者提出了两种可以处理不完整ground truth的relabeling方法,并减轻暴露偏差。作者通过大量的离线实验证明了提出的系统的有效性。此外,还提供了在线A/B测试结果,显示用户体验满意度显著提高。
机器学习领域部分文章
Arxiv 2021 | Graph Condensation for Graph Neural Networks
https://arxiv.org/abs/2110.07580
考虑到大规模图在现实世界应用中的普遍存在,训练神经模型的存储和时间已经引起了越来越多的关注。为了解决这些问题,作者提出并研究了图神经网络(gnn)的图压缩问题。具体来说,坐着的目标是将大的、原始的图压缩成一个小的、综合的、信息量大的图,这样在小图和大图上训练的gnn就有相当的性能。压缩通过优化梯度匹配损失,在原始图上模拟GNN训练轨迹来解决压缩问题,并设计了同时压缩节点特征和结构信息的策略。大量的实验证明了该框架在压缩不同的图数据集到信息更小的图上的有效性。




