聊聊机器翻译界的“灌水与反灌水之战”!

文 | Willie_桶桶
编 | 智商掉了一地
针对机器翻译领域如何提高和判断实验可信度,这篇ACL2021的oustanding paper迈出了关键的一步!(来读!全文在末尾)
作为不停读论文和调参炼丹的科研党,也许在我们的身边总会出现这样类似的对话:
案例1: xxx博士不讲武德,竟然让我把一部分测试集加入到训练集里面去,这是在公然蔑视学术道德?
案例2: 嘿嘿,调了调句子的最大长度,评测性能终于刷上去了。
案例3: 哇靠,那个人在作弊,baseline用BERT,自己的模型竟然用BERT-Large。
案例4: 就这个指标比SOTA好,其他几个指标都不行,要不就贴好的指标吧,老天保佑reviewer不要发现这个漏洞。
案例5: 单模态的性能也太强了吧,这让多模态效果怎么发论文?还是随便跑跑baseline,把性能调低点。
案例6: 调了一上午的参数,这次效果终于比SOTA强了,赶紧记录一下,顺便保存好checkpoint。
案例7: 这论文写的评测代码竟然是错的,我说性能怎么比我复现的好那么多。
案例8: 刚刚发邮件询问作者为啥引用我的实验效果那么低,他竟然说抄错了。
随着AI领域的持续火热,越来越多的同学在"想方设法"地设计算法来刷新任务性能,并产出了一篇篇精妙绝伦的论文。相关领域会议投稿量呈现出爆炸式地增长,然而投稿论文的质量参差不齐,作为一个普通投稿人,如何设计实验以更加有说服力地证明提出方法的有效性;以及作为一个审稿人,如何快速判断这篇论文提出的算法是否可(guan)信(shui),是值得深思的问题。针对机器翻译领域如何提高和判断实验可信度,下面这篇ACL2021的oustanding paper迈出了关键的一步!
论文标题
Scientific Credibility of Machine Translation Research: A Meta-Evaluation of 769 Papers
论文链接
https://aclanthology.org/2021.acl-long.566.pdf
![]() 1 背景
1 背景![]()
 1 背景
1 背景过去10年间涌现了大量提升机器翻译性能的算法,这些算法通过与前人的模型对比自动评测指标,比如BLEU分数值,来凸显其性能。随着论文报告的分数值越来越高,我们不禁要问,这些论文的评测方式真的有说服力吗?算法真的有效吗?整个社区是朝着良性的方向发展,还是灌水之风日渐严重?
为了回答以上问题,本文评估了过往10年间(2010 ~ 2020)发表在ACL相关会议的769篇机器翻译领域论文,着重对论文评测进行了分析,包括:
-
评价指标的多样性 -
统计显著性检验 -
直接复制前人实验结果 -
数据划分和预处理
基于分析结果,本文揭露了造成可疑评估的一个个陷阱,反映出当前社区正在朝着令人担忧的方向发展。
![]() 2 令人失望的评估结果
2 令人失望的评估结果![]()
通过对769篇论文的评估,作者揭露了当前机器翻译评测中令人担忧的4个陷阱。
2.1 称霸机器翻译的BLEU
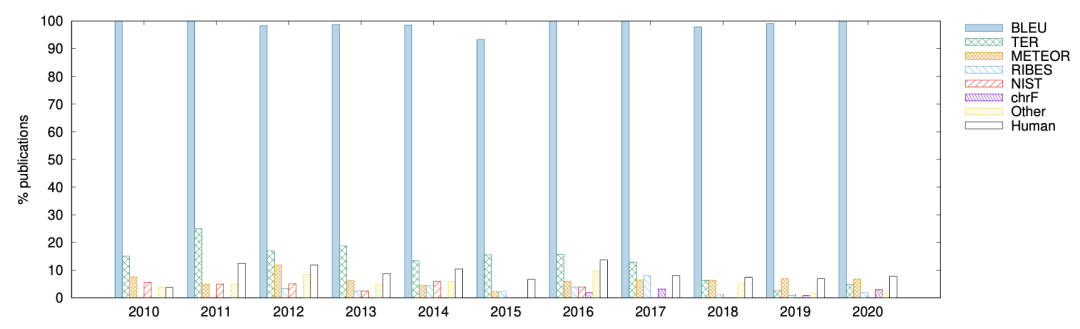
上图展示了10年间各种评价指标在机器翻译论文中所占的比重,BLEU以压倒性的优势成为了最热门的评价指标,几乎99%的论文都用它来衡量算法的优越性,而其他改进的评测指标则逐渐被学者们忽视。众所周知,BLEU作为一种自动评价指标存在一些缺陷,它仅仅能反应出模型某些特定方面的优势,所以有很多工作致力于研究更加合理的自动评测指标。
然而,一个很讽刺的现象是:过去10年间有超过108种改进的评测指标,其中很多更容易使用并且表现出比BLEU更加契合人类的评测模式,比如chrF,但大部分从未被人使用过;长此以往,这些自动评测的研究还有存在的意义吗?
为了说明仅仅依赖一种评价指标来衡量翻译模型性能是不充分的,作者统计了多种提交至WMT20的模型,使用BLEU和chrF评测指标的排名情况,结果如下表所示。

从表中可以看出,使用BLEU作为评价指标时,NiuTrans系统是 → 赛道中排名第一的模型,而当使用chrF指标时,Tohoku-AIP-NTT系统要优于NiuTrans系统。这反映出仅使用BLEU是无法准确得出某个模型更优的结论,机器翻译社区应该鼓励使用更优的评价指标来作为BLEU的补充或者替代品。
2.2 被遗忘的统计显著性检验
统计显著性检验是一种确保实验结果并非巧合的标准方法。在机器翻译领域,统计显著性检验早已被用于自动评测指标中,即评估两个机器翻译系统之间评测分值的差异是否巧合。直观上,这个检测能更加有说服力地反映算法的有效性,但近十年来使用该检验的论文越来越少。
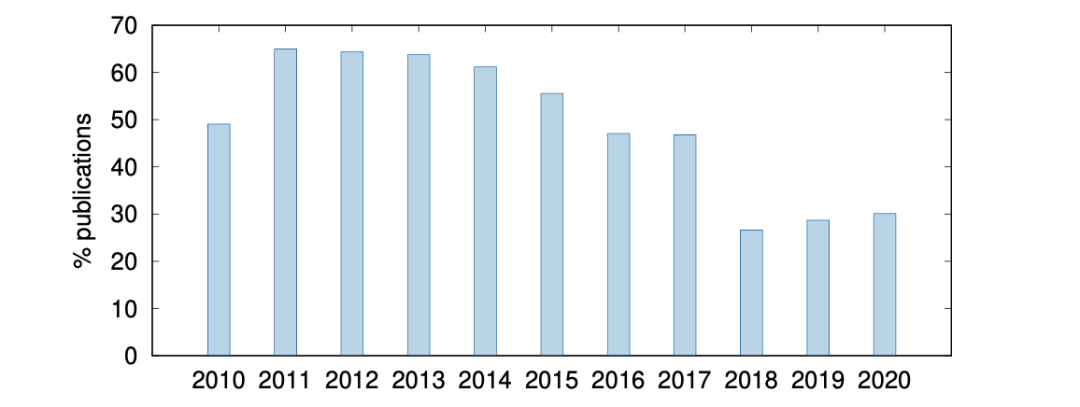
上图展示了各年ACL相关会议论文中使用统计显著性检验的比例。从图中我们可以发现,人们越来越不喜欢使用这个检验,即使它可以显著的提升论文可信度,导致这种现象出现的原因是有更好的提升可信度的方式,还是因为论文页数限制而无法添加多余实验(xin xu)呢?
此外,作者设计了另一组验证实验来说明,统计显著性检验结果与自动评测指标提升幅度没有直接的联系。在实验中,Custom 1操作指的是将模型输出中的最后一句替换为空白行,Custom 2操作对应将模型输出中最后一句替换为重复同一个词10k次的句子。
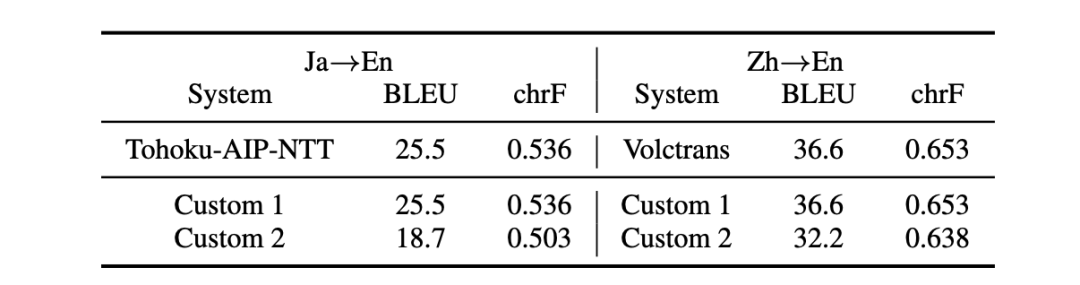
实验结果如上表所示,其中第一行表示各系统提交到WMT20的原始结果。观察表中结果可以发现,Custom 2操作会导致BLEU和chrF指标分值的剧烈下降,但在统计显著性检验实验中,并没有发现任何系统要明显优于其他的系统。
2.3 一直copy一直爽
随着NLP论文爆发式的增长,直接复制前人报告的实验结果进行对比,是一种省时又省力的方式,在机器翻译领域亦是如此。
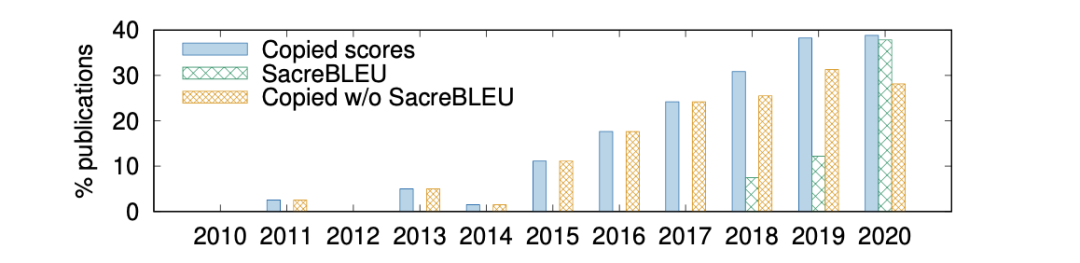
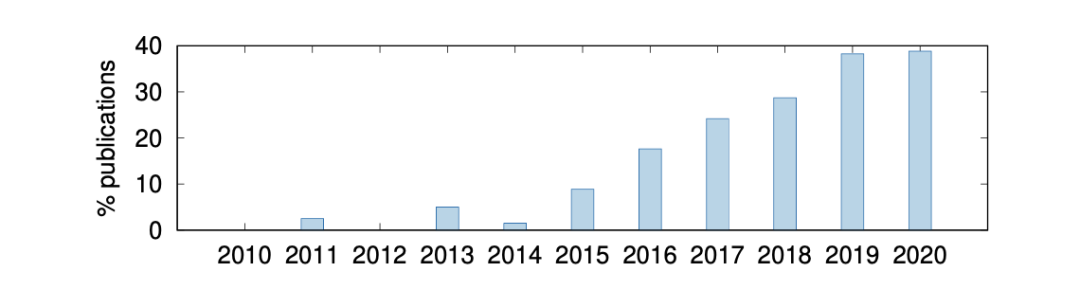
上图是近10年间,各年直接复制前人实验结果进行对比的论文比重。越来越多的论文更加倾向于直接复制实验结果而不是复现相关实验,这在2015年以后显得尤为明显;拷贝结果的确可以省时省力,但引发的问题是:那些论文是否提供了足够信息,以确保它取得的分值和前人报告的结果具有可比性。
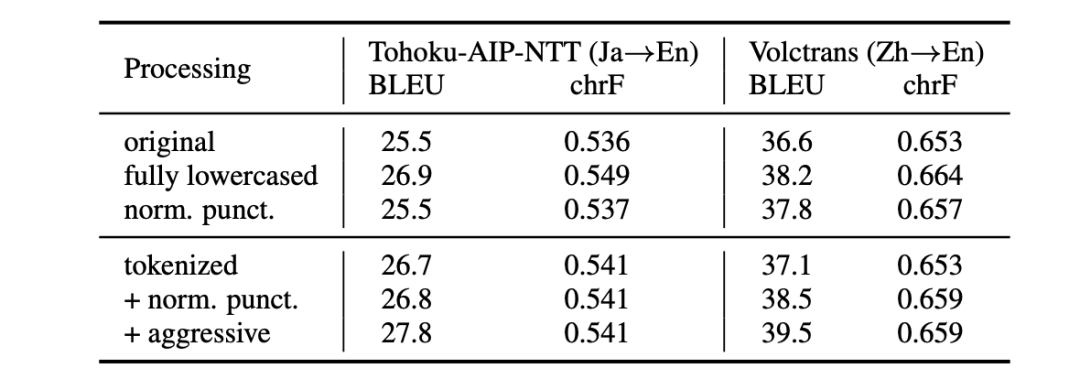
那么,稍微对模型输出进行处理会造成性能的差异吗?作者设计了一组实验,测试被科研人员广泛使用的后处理方式对性能的影响。针对模型输出结果进行后处理的操作包括:是否完全小写化、是否标点规范化、是否进行tokenize处理。实验结果如上表所示,不同的后处理方式对自动评测结果有很大的影响,比如进行完全小写化处理,可以将Tohoku-AIP-NTT系统在 → 赛道和Volctrans系统在 → 赛道的评测BLEU值分别提高1.4和1.6,这在翻译领域可谓是显著的提升。
2.4 评测中数据的"艺术"
数据集通常被分为训练集、验证集和测试集,以用于模型学习和评测,不同的数据预处理方式可以带来各种“期待”的结论。机器翻译领域论文大多提出新算法以提高翻译准确度(因变量),而评测新的算法对因变量的影响时,需要保持其他所有自变量(例如数据集)不变,否则无法保证算法性能的可信度。
那么实际情况又是怎样的呢?作者统计了近十年进行性能对比却使用不同数据的论文比例,结果如上图所示。十年来,越来越多的论文在进行对比实验时使用了不一致数据,在这种设定下,我们无法判断出性能的提升到底是因为算法的优越还是数据的"艺术"。
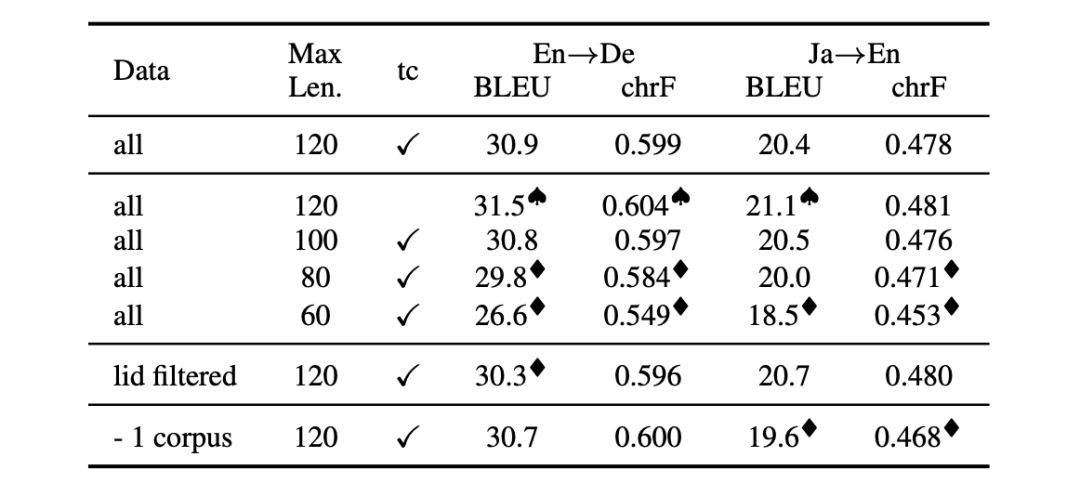
为了说明数据的"艺术"对性能的影响,作者设计了一组对比实验,评估各种被广泛使用的数据预处理方式对结果造成的影响,包括数据最大长度、是否Truecase处理、过滤其他语言文本噪音、删减1个语料。实验结果如上表所示,简单地改变数据集中句子的长度或者进行Truecase操作,都会导致各种评价指标和显著性检验结果剧烈波动,所以要真正凸显算法的有效性,保证数据一致性是不可或缺的。
![]() 3 反击灌水的攻与防
3 反击灌水的攻与防![]()
通过评估近10年769篇ACL相关会议论文,本文发现了当前机器翻译领域普遍存在的4个陷阱,并且给出了关于如何增强论文可信度以及判别论文结果的指导方案。
针对提高论文结果可信度,需要:
-
不应该仅使用BLEU作为评测指标,也需要结合其他更加合适的自动评测指标及人工评测。
-
无论自动评测指标分值提高有多大,都应该尽量进行统计显著性检验。
-
尽量不要直接拷贝别人的实验结果,如果不可避免,要保证结果具有可比性。
-
要保证所有的数据集以及预处理方式一致。
对于评估论文实验结果的可信度,可以通过回答以下问题进行打分(每个yes得1分,分数越高越可信):
-
是否使用了比BLEU更能与人类判断相关联的指标,或者进行了人工评估?(yes/no)
-
是否进行了统计显著性检验?(yes/no)
-
是否为论文计算了自动度量分数而不是从其他工作中复制?如果复制,是否所有复制的和比较的分数都通过确保其可比性的工具(例如 SacreBLEU)计算得出?(yes/no)
-
如果对比的机器翻译系统是为了凸显算法的优越性,那么系统间是否使用了相同的数据集及预处理方式?(yes/no)
![]() 4.总结
4.总结![]()
当前对于生成任务,评价指标仍然不甚完善,各种"艺术性"操作也经常层出不穷。看惯了身边谜之操作的你,是否愿意支持评测规范化,加入反击的阵营呢?
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【
后台回复关键词【




