近日,自然语言处理顶会 EMNLP 2019 在中国香港落下帷幕。
在本次大会中,中国被接收的论文数量在所有国家和地区中位居第二,哈尔滨工业大学刘挺教授有 10 篇论文被接收。
在闭幕式上,大会颁发了最佳论文奖等多个奖项。
来自约翰·霍普金斯大学的研究团队摘得最佳论文奖,其一作为华人学者。
![]()
本次大会吸引了国内外众多自然语言处理领域的专家学者参加,参会人数达到了 1920 多人。
大会共举办了 18 场 Workshop、多个 Tutorial 和多场主题演讲,涵盖自然语言处理、社会计算学、计算机社会科学、AI 系统和深度学习等话题。
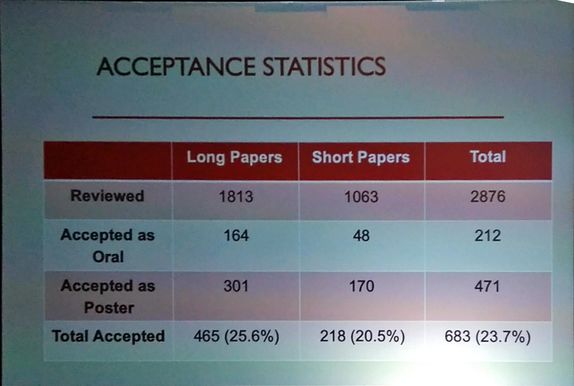
从论文投稿整体接收情况来看,本届大会共收到有效投稿 2876 篇,接收 683 篇,接收率为 23.7%。
其中,被接收的长论文有 465 篇,包括 164 篇口头报告和 301 篇 Poster 论文;
短论文共有 218 篇,包括 48 篇口头报告和 170 篇 Poster 论文。
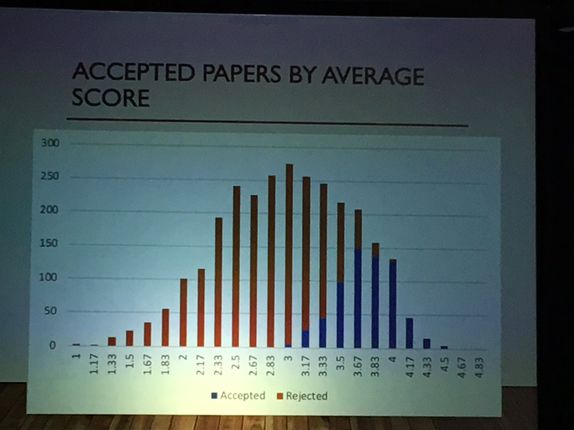
从论文投稿得分情况来看,得分在 3.67 以上才能保证有很大的概率被接收。
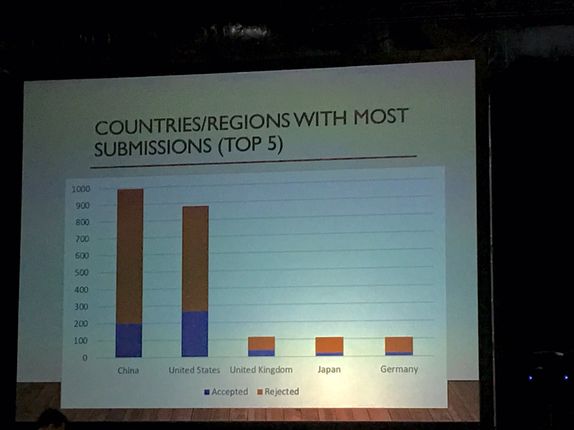
从论文投稿国家/地区来看,中美两国的投稿量远远大于其他国家,其中中国提交了近 1000 篇,美国也近 900 篇。
虽然中国的投稿量多于美国,但美国依然是接收论文最多的国家。
下图是论文投稿量排名前五的国家:
投稿量前五名分别为:
中国、美国、英国、日本和德国。
另外,机器之心还参考了学术头条关于本届EMNLP大会的报道,它们从投稿领域、入选论文所属机构等多方面对本届大会进行了分析。
以下是有关这两方面的具体分析:
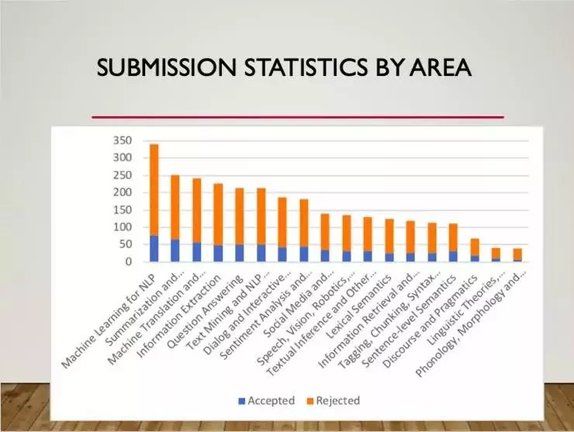
从论文投稿领域来看,投稿量排名前三的领域依次是:
用于自然语言处理(NLP)的机器学习、摘要和生成(Summarization and Generation)和机器翻译与多语化(Machine Translation and Multilinguality)。
这三个领域的接收论文都超过了 50 篇。
据学术头条统计,从入选论文所属机构来看,国外学界和工业界中,卡内基梅隆大学、艾伦人工智能研究所、爱丁堡大学、加利福尼亚大学、华盛顿大学等机构的论文入选数位居前列;
谷歌、Facebook、微软、IBM 等业界巨头依然占据霸主地位;
国内高校中,北大、清华、哈工大、北航、浙大、中山大学、北理工的论文录取数量位居前列,阿里巴巴、腾讯等业界巨擘表现不俗。
在本届大会所有接收的论文中,机器之心经整理发现,哈尔滨工业大学教授、哈工大人工智能研究院副院长刘挺教授有 10 篇论文被接收。
机器之心根据所有的投稿论文标题制作了词云,从中可以看出,生成、神经网络等是本次大会的重点关注领域。
本次 EMNLP-IJCNLP 大会颁发了最佳论文奖、最佳资源奖、最佳 Demo 奖等多个奖项,以下是具体的获奖信息。
今年的最佳论文奖颁给了约翰·霍普金斯大学的研究团队,他们的论文题目是《Specializing Word Embeddings(for Parsing)by Information Bottleneck》,其一作 Xiang Lisa Li 是约翰·霍普金斯大学的大四学生,是一位华人学者,其导师是著名 NLP 学者 Jason Eisner。
论文链接:
http://cs.jhu.edu/~jason/papers/li+eisner.emnlp19.pdf
摘要:
预训练词向量,如 ELMo 和 BERT 包括了丰富的句法和语义信息,使这些模型能够在各种任务上达到 SOTA 表现。
在本文中,研究者则提出了一个非常快速的变分信息瓶颈方法,能够用非线性的方式压缩这些嵌入,仅保留能够帮助句法解析器的信息。
研究者将每个词嵌入压缩成一个离散标签,或者一个连续向量。
在离散的模式下,压缩的离散标签可以组成一种替代标签集。
通过实验可以说明,这种标签集能够捕捉大部分传统 POS 标签标注的信息,而且这种标签序列在语法解析的过程中更为精确(在标签质量相似的情况下)。
而在连续模式中,研究者通过实验说明,适当地压缩词嵌入可以在 8 种语言中产生更精确的语法解析器。
这比简单的降维方法要好。
EMNLP-IJCNLP 2019 最佳论文第二名
今年最佳论文奖的第二名颁给了斯坦福大学的研究团队,他们的论文题目是《Designing and Interpreting Probes with Control Tasks》。
作者为 John Hewitt、Percy Liang。
论文链接:
https://www.aclweb.org/anthology/D19-1275.pdf
摘要:
训练有素的监督模型可以根据表达形式(如 ELMo)预测属性(如词性),探测器在一系列语言任务上均具有很高的准确性。
但这是否意味着这些表达形式对语言结构进行了编码,或者只是探测器已经学习了语言任务?
在本文中,研究者提出了控制任务,将词的类型与随机输出联系起来,以辅助语言任务。
按照设定,这些任务只能由探测器来学习。
因此选择一个合适的探测器(能反映该表达形式的探测器)很重要,以实现较高的语言任务准确性和较低的控制任务准确性。
探测器的选择性将语言任务的准确性与自身记忆词类型的能力相关联。
研究者提出了用于英语词汇标注和依赖边缘预测的控制任务,并且展示了基于表达形式上的探测器是不可选择的。
同时他们还发现,通常用于控制探测器复杂性的滤除对提高 MLP 的选择性是无效的,但是其他形式的正则化是有效的。
最后,他们发现,尽管 ELMo 的第一层探测器比第二层探测器的词性标注精度高一些,但是第二层上的探测器更具选择性。
引出了以下问题:
究竟哪一层可以更好地代表词性。
今年的最佳资源奖颁给了 Facebook、美国索邦大学和约翰·霍普金斯大学的研究团队,他们的论文题目是《The FLORES Evaluation Datasets for Low-Resource Machine Translation: Nepali–English and Sinhala–English》。
作者为 Francisco Guzmán、Peng-Jen Chen、Myle Ott、Juan Pino、Guillaume Lample 等
论文链接:
https://arxiv.org/pdf/1902.01382.pdf
项目地址:
https://github.com/facebookresearch/flores
摘要:
在机器翻译领域,很多语言对的可用对齐语料都非常稀少。
除了在技术上要面临有限制的监督学习挑战外,评估这些在低资源语言对上训练的方法也存在困难,因为可用的基准非常少。
在本文中,研究者介绍了一个用于尼泊尔语-英语、僧伽罗语-英语的 FLORES 评估数据集,该数据集基于维基百科上翻译过的句子。
与英语相比,这些语言在形态学和句法学上都存在很大差异。
对于这些语言,很少有领域外的平行语料可用,但它们的免费可用单语数据非常丰富。
研究者描述了收集和交叉验证翻译质量的过程,并使用几种学习方法报告基线性能,包括完全监督、弱监督、半监督和完全无监督。
实验表明,当前最佳的方法在这些基线上表现都非常差,这给研究低资源语言机器翻译的社区带来了很大挑战。
EMNLP-IJCNLP 2019 最佳 Demo 奖
今年的最佳 Demo 奖颁给了加州大学伯克利分校、艾伦人工智能研究所、加利福尼亚大学尔湾分校的研究团队,他们的论文题目是《AllenNLP Interpret: A Framework for Explaining Predictions of NLP Models》。
作者为 Eric Wallace、Jens Tuyls、Junlin Wang、Sanjay Subramanian、Matt Gardner、Sameer Singh 等人
论文链接:
https://arxiv.org/abs/1909.09251
项目地址:
https://allennlp.org/interpret
摘要:
神经 NLP 模型正变得越来越精确,但它们远非完美,而且是不透明的。
这些模型以违反直觉的方式崩溃,使得用户摸不着头脑。
模型解释方法通过为特定的模型预测提供解释来减轻它们的不透明性。
然而,现有的解释代码库使得这些方法在新模型和新任务中难以应用,这阻碍了从业者采用这些方法,同时也给可解释性研究带来负担。
为此,来自艾伦人工智能研究所等机构的研究者开发了一个灵活的 NLP 模型解释框架——AllenNLP Interpret。
它可以为所有的 AlenNLP 模型和任务提供解释原语(如输入梯度)、一系列内置解释方法一级一个前端可视化组件库。
参考链接:https://mp.weixin.qq.com/s/IKREAyWcTH-jp8plTcAR5A
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content
@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com