SampleRNN语音合成模型
SampleRNN语音合成模型
本文参考文献
Mehri S, Kumar K, Gulrajani I, et al. SampleRNN: An unconditional end-to-end neural audio generation model[J]. arXiv preprint arXiv:1612.07837, 2016.
被引次数:10
与wavenet类似,SampleRNN同样也是基于条件概率抽样得到音频采样点的数据,如下条件概率公式所示,每个采样点的数据是由之前所有采样点数据作为条件概率抽样生成。由于语音合成的工作难点是处理长期时序关联性,因为即使只有两秒的采样频率为16kHz的音频,也要处理32000个采样点,对于更长的音频,采样点则更多,之前我们在语言建模中输入到LSTM的采样时刻到几十个已经很多了,现在要处理的是几万甚至几十万个点,难度相当大,这就是为什么语音合成的流畅度不够好的原因,时序建模的跨度非常大。
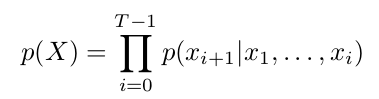
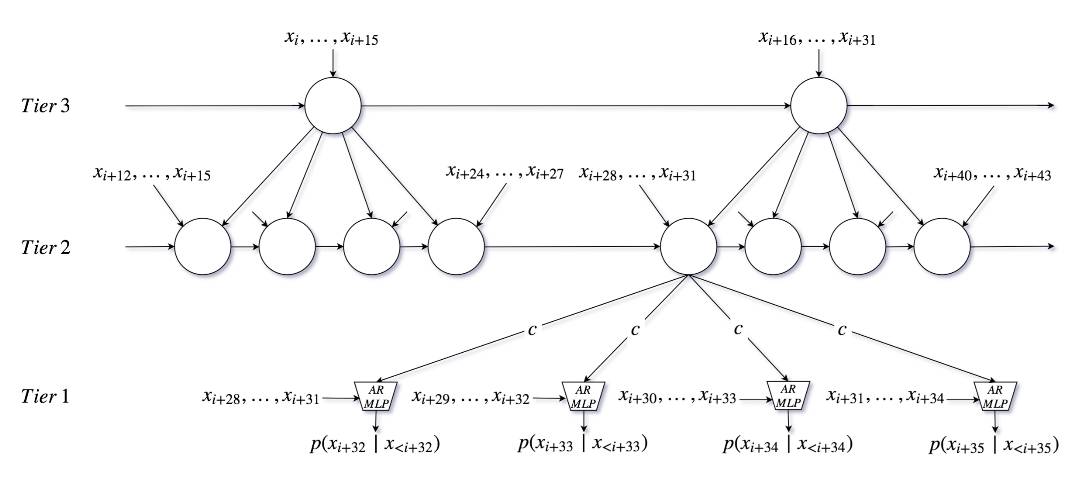
SampleRNN是一个具有启发性结构的RNN,其将不同的层归到”tiers”,每一个tier是一个循环神经网络,它的作用类似于seq2seq中的编码器,对所有输入进行编码得到一个编码后的特征向量。tier处理的时间窗大小可以人为设定,不同的tier操作着不同的时间尺度。tiers形成了启发性的结构,这意味着它可以通过多层连接实现对长程时序关系的建模。由下图可以看到,图中一共有三个tier,最下面一个tier接受最后4个样本以及中间tier的输出作为输入,中间的tier一方面为下面的tier提供输入,同时自身也接受最后4个样本以及最上面的tier的输出作为输入,最上层的tier一方面为中间层的tier提供输入,另一方面则接受最后16个样本作为输入。由此可以看出,SampleRNN是由启发性RNN和MLP构成,只有最底层的tier处理的是单个样本,越上层计算量越小,因此整体计算量较小,而wavenet则是每一层都处理的是样本级别。
除此之外,SampleRNN的抽样过程、数据离散算法都与wavenet类似,此处不再充分说明。
SampleRNN可以较好地处理语音合成这样非常长程的问题,那么将其应用到其他比较复杂的时序建模问题应该也是可行的。
题图:Crystal Liu
你可能会感兴趣的文章有:
详述DeepMind wavenet原理及其TensorFlow实现
Layer Normalization原理及其TensorFlow实现
Batch Normalization原理及其TensorFlow实现
Maxout Network原理及其TensorFlow实现
Network-in-Network原理及其TensorFlow实现
如何基于TensorFlow实现ResNet和HighwayNet
深度残差学习框架(Deep Residual Learning)
推荐阅读 | 如何让TensorFlow模型运行提速36.8%
推荐阅读 | 如何让TensorFlow模型运行提速36.8%(续)
深度学习每日摘要|坚持技术,追求原创





