【深度】视觉的层次化处理过时了吗?

本文得到
CCF-CV专委会授权发布,公众号「CCF计算机视觉专委会」
计算机视觉是人工智能的“眼睛”,是感知客观世界的核心技术。进入21世纪以来,计算机视觉领域蓬勃发展,各种理论与方法大量涌现,并在多个核心问题上取得了令人瞩目的成果。为了进一步推动计算机视觉领域的发展,CCF-CV组织了RACV2019,邀请多位计算机视觉领域资深专家对“视觉的层次化处理过时了吗?”进行研讨。
本期专题为“视觉的层次化处理过时了吗?”。各位专家从计算机视觉的目标、Marr视觉理论、广义层次分析方法、可解释性神经网络及脑皮层处理机制等多方面展开了深入的探讨。
主题组织者:查红彬,鲁继文,马占宇
讨论时间:2019年9月28日
发言嘉宾:胡占义;贾云得;邬霞;张拳石;郑伟诗
参与讨论嘉宾[发言顺序]:林宙辰,山世光,查红彬,赖剑煌,王亦洲,纪荣嵘,邬霞,胡占义,林倞,陈熙霖,何旭明,王涛,毋立芳,徐凯
文字整理:明悦
审校:山世光
各位老师早上好,我们这个研讨会现在开始。这个分会的主题是:视觉层次化处理过时了吗?这个题目,本来是贾云得老师提出来的,但是因为贾老师工作繁忙,世光就把这个任务推到我头上了。很幸运,我们有鲁继文老师、马占宇老师的大力支持,还请了五位我们认为应该对这个主题有很多感受的老师来做报告,今天非常荣幸能跟大家一起讨论有关这方面的想法。
视觉的层次化处理,这是个老题目,应该说在计算机视觉发展这么多年当中,只要是研究计算机视觉的人大概都有点关联,我想将来再过一段时间还会有很大的关联。但是这个东西就像三国演义里面害死了杨修的那个叫鸡肋骨一样的东西,你把它扔掉吧又舍不得,你想啃它吧又啃不出肉来,所以这玩意就是有点让你很难受的那种感觉。刚才世光说让我们享受周围的风景,后边这两个小时我们就一边看风景,一边啃鸡肋骨。好吧,下面我们请胡占义老师先做报告。
二、主讲嘉宾发言实录
1. 胡占义
查老师让我来向大家介绍一下我对这个议题的观点,山老师反复强调不要介绍自己的研究成果,我最近这两年对计算机视觉了解的不够,我已成了计算机视觉的一个interested outsider,感兴趣,但没有多少研究。所以说要求不要介绍自己的工作,这个要求对我来说比较容易做到,因为我本来就没有自己的工作值得给大家介绍。
对这个议题,第一个我先说说我对提出这个议题的可能初衷。为什么大家会提出“视觉中的层次化处理是否过时了”这个议题呢?我觉得可能是因为最近这几年的深度学习。因为深度学习框架下,从图像到特定视觉任务,人们通常通过端到端的学习完成,这样大家就觉得传统的从图像去噪、物体分割、特征提取、物体表达、物体识别的层次化处理步骤就不需要了,这种框架也过时了。

我觉得对这个议题的讨论,我们首先需要探讨一个什么是计算机视觉。计算机视觉为什么叫计算机视觉,而不是模式识别,图像处理呢?这是因为我们计算机视觉的核心科学问题与其它相关领域不同。所以,我觉的对“层次化处理是否过时了”这个议题的讨论,需要至少回答下面三个问题:第一:计算机视觉的目标是什么?第二:计算机视觉是一门科学吗?第三:计算机视觉是不是还需要300多年来一直沿用的由笛卡尔和牛顿建立起的科学分析方法。
关于计算机视觉的目标是什么这个问题,我觉得计算机视觉你不管做什么,其实它最重要的还是想构建一个通用灵活的视觉系统。通用性和灵活性是最主要的两个特点。关于计算机视觉的目标以及我们现在讨论的议题,我昨天晚上也说过,其实和90年代初,大家对Marr计算视觉理论提出的质疑和批评差不多。
讨论计算机视觉的目标,不能不提及马尔计算视觉理论,因为我们计算机视觉研究长期以来还是在马尔计算视觉框架下进行的。其实我们今天的计算机视觉大多都还是计算视觉。马尔大家都知道,34岁建立了计算视觉,白血病去世以后,Marr的书<vision>1982年出版,他是81年去世的,他的书由他的学生帮他完成。上世纪90年代初,对马尔视觉提出批评的,最主要的是三个人物,一个就是马里兰大学的J. K. Aloimonos,一个就是密歇根州立大学的A. K. Jain,一个是宾夕法尼亚大学的R. Bajcsy。大家都知道,马尔的计算视觉由计算理论、表达与算法和算法实现三个层次组成。马尔觉得算法的具体实现方式对计算视觉不重要,所以,马尔的书主要讨论了前面二个问题,特别是重点讨论了“表达和算法”部分,即如何分步构建从primitive到2.5D,然后到3D的物体表达。大家对马尔层次化处理框架提出的批评,主要是说马尔视觉缺乏“目的性”和“主动性”,是一种bottom-up的被动过程。1994年在CVGIP:Image Understanding组织了一个专刊,这个刊物现在就是Computer Vision and Image Understanding,辩论关于“目的视觉”是不是一个视觉新框架,马尔计算视觉框架是否过时的问题。全世界30位专家发表了看法。辩论首先由耶鲁大学的心里学家Michael J. Tarr和计算机视觉专家Michael J. Black共同署名的文章“A Computational and Evolutionary Perspective on the Role of Representation in Vision”,对目的视觉提出了批评。指出计算机视觉的目的是建立像人类视觉系统一样具有“通用性和灵活性”的视觉系统。经过辩论,大家最终形成了比较一致的折中性意见,即目的视觉完全可以融入马尔的层次化处理框架下。马尔的层次化处理框架,并不排除“主动性”和“目的性”。
我记得2000年左右我在做一个talk时有一个学生问我,老师让他博士论文内容做主动视觉方面的工作,问我觉得前景如何。我建议他不要做,我当时觉得这方面不会有大进展。事实上主动视觉我自己觉得从94年到现在,25年过去了也没有像样的进展。回到我们的议题,计算机视觉的目标是什么,我觉得建立一个具有通用性和灵活性的视觉系统这个目标仍还是一个比较合适的目标。假如目标仅仅是建立一个人脸识别系统,从目前的深度学习来看,“端到端”的学习,不需要显式层次化加工步骤,就可以实现。但要构建具有“通用性和灵活性”的视觉系统,我觉的“层次化处理的框架和途径”还不能说过时,我甚至觉得是必不可少的。
第二个问题就是说计算机视觉是不是一门科学,我觉得一门科学至少有三个特点:探索未知、发现规律和指导应用。计算机视觉需要借鉴生物视觉,而生物视觉的信息加工过程是一个层次化加工过程。最近这10到15年,一直在学习生物视觉。即使对视网膜(retina)而言,已经经过从感光细胞(photoceptor)到双极细胞(bipolar cell)到神经节细胞(ganglion cell)的三层加工。神经节细胞的功能主要是去噪,进行对比度增强(contrast enhancement)。神经节细胞的输出经过外漆体(LGN)达到V1区。V1区主要进行边缘检测和运动方向检测,这是比较清楚的。视觉物体识别在IT区。事实上,根据我的学习和理解,从V2,到V4,再到IT区,神经领域有些研究结果,但目前缺乏系统性研究结果。大家如果对生物视觉的神经机理想了解一下的话,我建议大家去看看MIT的DiCarlo2012年在《Neuron》上发表的文章:How Does the Brain Solve Visual Object Recognition? DiCarlo对猴子的快速物体识别,即100多毫秒能完成的识别的神经加工机理进行了介绍。
猴子的视觉系统,主要由物体视觉(object vision)和空间视觉(spatial vision) 系统组成。物体视觉就是识别物体,空间视觉就是用于操作物体的视觉,如抓取物体的视觉。当前深度学习主要在物体视觉方面取得了非常好的结果,但在空间视觉方面,有一些工作,但都与基于几何的方法无法媲美。所以,目前研究基于几何的三维计算机视觉的研究人员要有自信和信心。深度学习不是万能的,我觉的在3-5年内,深度学习在三维视觉方面要超过基于几何的方法是不可能的。三维视觉需要精度,看上去像的基于学习的三维视觉没有实质性用处。上面说明,视觉仍是一个迷,还需要不懈努力地去探索。视觉通道从解剖结构上看,是一个层次化结构。结构决定功能,所以,神经科学也旨在揭示这种层次化加工机理。目前也有解释深度网络的工作,但与我这里说的揭示视觉物体的加工机理不是同一个概念。
回到计算机视觉是不是一门科学这个问题的第二个问题,即发现规律。人类历史上伟大的发现,如万有引力定律,麦克斯韦电磁方程、质能方程等,都具有非常清晰的物理意义和简洁的描述。发现规律应该是我们科研人员的不懈追求。据我所知,在神经科学领域,也有很多人反对用“深度网络”对神经物体表达进行建模,他们觉得用一个“大脑”建模“另一个大脑”意义不大,提供不了真正意义上的模型解释。层次化处理方法,我们计算机视觉领域有非常优秀的工作:如马尔从primitive-2.5D-3D的层次化三维视觉。Hartley 和Faugeras 等的从射影重建->仿射重建->度量重建的分层三维重建理论(stratified 3D reconstruction)。我对计算机视觉研究也有30多年了,我认为计算机视觉方面的任何其它书籍,没有任何一本可以与Marr的vision相媲美。我觉的从事计算机视觉的研究人员,还是应该好好读读Marr这本书。Hartley靠分层三维重建工作获得澳大利亚科学院和工程院院士,Faugeras靠分层三维重建工作获得法国科学院院士。现在神经科学领域有些人认为,视觉物体识别系统是一个逆生成模型,Inverse generative model,我觉的这是一种非常好的猜测。逆生成模型,是一种典型的层次化加工模式。
关于计算机视觉是不是一门科学这个问题的第三个问题,即指导应用问题。目前的端到端的深度学习,很难给出解释,给出具有应用性指导的原理和途径。由于时间关系,这个问题我就不多聊了。
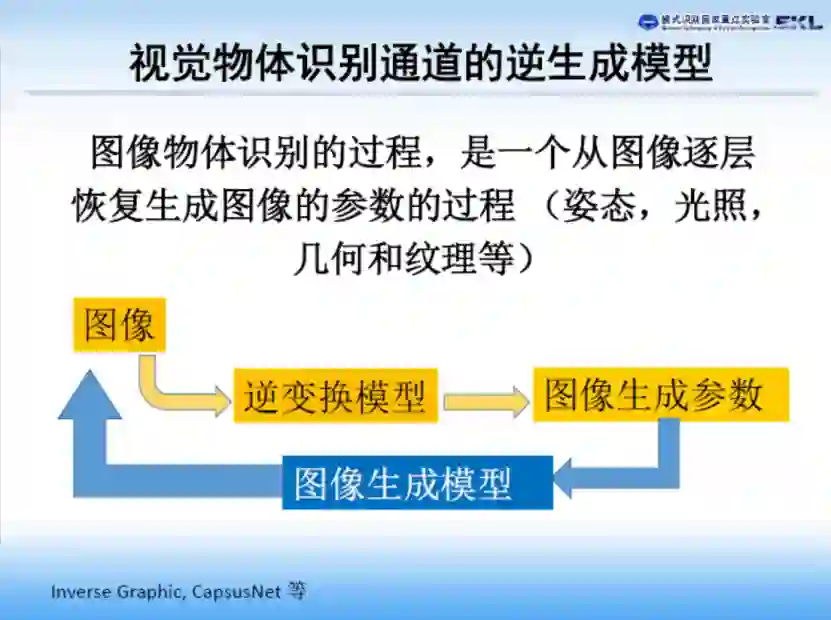
刚才胡老师从生物视觉的角度解释视觉分析的层次处理方法,非常受启发。胡占义老师近几年对生物视觉做了非常深入的研究,对生物视觉的理解具有独到之处,特别是一位从事计算机视觉资深研究的学者来研究生物视觉,得到的结论对研究计算机视觉具有特殊的促进作用。两年前专门请胡老师来给我的学生做了一场生物视觉报告,学生们的反应非常好。
现在常讲“牢记使命”,从事计算机视觉的学者使命就是解决计算机视觉发展的瓶颈问题、挑战性问题。看到有老师提出讨论“视觉层次处理方法过时了吗?”这一话题,一开始的反应是这个话题还需要讨论吗?不过既然有老师提出这样的问题,应该有特别的看法;出于对看法的期待,我好奇地投票,建议讨论这个问题。几天前,由于主报告人方方教授有事无法出席这次会议,查教授要我替补做主报告,心里一点准备都没有,也没有积累到那个厚度来做报告。经不住查教授一再邀请,感谢他给我这个机会,向大家汇报一下我对这个问题的粗浅看法。
我的研究背景是武器系统工程,武器系统分析与设计非常讲究设计思想和设计方法,层次分析方法就是其中一种非常重要的设计思想。因此,这个层次分析方法给我的印象很深。早在1984年我的导师马宝华先生(我国著名武器系统专家)给我们讲授在国内刚刚兴起的层次处理分析法(Analytic Hierarchy Process,简称AHP),该方法是1975年美国运筹学者Saaty提出的;大家都熟悉,将决策分解成目标、准则、方案等层次,在此基础之上进行定性和定量分析。直到现在,这种分析思想对我的影响极深,影响方方面面。比如,招收研究生,有5个学生报考你的研究生,究竟选择哪一位,你不仅要看他的学习排名,还要看他的思考思辨能力、编程实践能力、学习研究态度、家庭环境等因素。Maslow的人类需求层级理论也是一种层级处理方法,这是示意图,每一层的界限非常分明的。Maslow的层级理论充分表明人类需求的普遍规律,是客观存在的。在日常生活和工作中,我们都会不自觉的对问题思考、分析、求解进行层次化处理,比如,中美关系有合作与竞争、制裁与对抗、排斥与战争的层次划分。目前的中美关系处于制裁与对抗层次,只要不发生战争,我认为我们国家仍然会发展的很顺利。还有许多例子,我们常常会用分层的思想去分析,或这个社会的结构就是分层的。
在工程设计领域,我们也常用分层设计思想。我学的是武器系统专业,我们设计的引爆与控制系统遵循层次设计思想。比如,引爆一颗原子弹,并不是直接用炸药引爆,而是一个分层非常精致的引爆控制系统,由电雷管、起爆药、猛炸药、核装药、热核装药。掌握了武器设计原理,包括层级原理,可以设计出简易高效的武器系统。
下面讨论计算机视觉领域的层次处理方法。1962年和1965年Hubel和Wiesel发表论文,提出人脑对视觉进行处理的层次过程,并提出了层次化加工过程(hierarchical process)这一概念。我们可以推测David Marr可能受到这一工作的启发。他1967年抑或1968年就做完关于小脑皮层理论的博士论文,在神经生理学领域引起轰动,被认为是该领域的一颗新星。据说他1970年才进行博士学位论文答辩,是因为他的研究兴趣由脑皮层理论转到生物视觉层次化信息加工理论,后来称为计算视觉理论。因此,根据年代推测,David Marr的数学和神经生物学基础,又受Hubel和Wiesel工作的启发,对生物视觉加工模型产生浓厚兴趣。他于1973年应邀进入MIT AI实验室领导一个以博士生为主体的研究小组,1977年提出了计算视觉理论(computational vision),这一理论完全不同于当时主流的"积木世界"分析方法。计算视觉理论成为计算机视觉研究领域中的一个十分重要的理论框架。这是刚才胡老师也讲过的视觉信息处理的三个层次,从计算理论到表示和算法再到硬件实现,这个PPT是2000年我给研究生上计算机视觉的课件。也是那个时候接受胡占义老师建议,David Marr的计算视觉理论作为我们博士生必读经典著作。
David Marr把计算视觉信息处理研究分为三个层次,这一点对我们的影响很深,目前大多数学者都在做第二个层次(表示和算法)的工作,可以说有99%的人在做这一层的工作,而研究视觉计算理论(第一层次)的人很少,做硬件实现(第三层次)的人也很少。我们曾经投入好几百万做立体视觉硬件系统,做了近10年,原理样机和原型样机都做出来了,但微软的Kinect出现了,Kinect做的很漂亮,性能非常好,但价格不到2000元,而我们的系统估计也得20000元,只好放弃立体视觉硬件。
Marr把视觉信息处理过程分为三个层次,底层视觉、中层视觉、高层视觉。由此也可以把计算机视觉的研究内容分为五层,即成像装置、底层视觉、中层视觉、高层视觉、视觉计算体系架构。第一层成像装置是视觉系统的输入设备,目前不少团队在研究新型成像装置,相信再过5年,会出现不少新的成像装置,如同kinect那样的三维多维多波段等低成本商用成像设备,特别是手机的广泛普及和快速升级的需求,会推动成像系统的快速发展。这样的硬件设计工作由高科技公司做更有优势。
下面讨论传统视觉信息分层加工处理过程,即低层、中层、高层视觉加工过程。这中层级加工处理过程,刚才胡占义老师也讲了,是有神经生物学依据的。这是前几天从中科院上海神经所的一个新闻报道下载的一张图片。这是腹侧视觉通路,一种高效的视觉信息处理网络,由视网膜成像后通过视神经传到初级视皮层V1,完成诸如形状、颜色、位置等简单特征的检测,然后进入V2、V3、V4区,完成特征的组合,再进入下颞叶皮层(IT),完成目标识别,因此,这是一个从视网膜成像、特征、特征组合到目标识别四个层次的视觉加工过程。这也是计算机视觉处理视觉信息的生物学依据。
关于视觉层次处理的最新的很有意义的工作是MIT学者Yamins等人发表在PNAS 2019的论文。他们建立了一个层级模型来预测视觉皮层各个层级的神经响应,每一层都是一个由滤波器、池化、正则化构成的多层神经网络(CNN)。模型各个层级CNN输出和生物视觉信息处理的层级的响应有着非常高的相关性,这是一个很激动人心的结论。因此,不论是社会学领域、工程设计领域、还是计算机视觉以及生物视觉,层次化处理方法不存在过时一说。
最后,给出视觉信息处理层次化方法的延伸,可以称之为广义层次分析方法。一般来说,层次化结构是自下而上或自上而下的单向结构,每一层都包含有许多challenging问题,解决没有challenging问题有上千篇上万篇的论文,旧的问题没有解决好,新的问题又出来了,由此也是吸引了大批学者加入计算机视觉行列。但由于Marr视觉层次化处理结构是单方向架构,受到了许多学者的质疑,也就是说Marr视觉层次化框架没有反馈机制,无法含盖主动视觉机制。因此,除了每一层之间都是前向连接关系外,还可以增加反向通道,实现反馈机制,每一层都和反向通道连接,这样不仅实现局部反馈,也可以实现分层反馈直至全局反馈。
分层分析方法的另一种延伸策略是在原有基本层级结构的基础上,增加层级,即增加N+1层、N+2层…,比如,Marr层级中的最高层是视觉目标识别,可否增加一层属于推理层、理解层、意识层?Marr层级中的最底层是基本特征提取,可否增加-1、-2…层,比如,基本特征形成的像素或超像素是计算出来的。
总之,层次化处理方法不仅仅是视觉信息加工的基本架构,有着自然进化的生物学依据,也是工程设计和社会科学分析的基本方法。好的分析架构往往是解决问题的有力工具,层次化方法就是这样的工具,包括层次化架构+反馈机制以及层次化方法的延伸,有着许多挑战性问题,期待我们的中国学者,特别是青年学者投入更多的精力解决这些问题,在计算机视觉理论、算法、系统等方面做出能引领计算机视觉领域学科前沿的贡献。
点评(查红彬):
谢谢贾老师的报告,以上是我们这个研讨会的两个重量级报告,但是这并不意味着后面的三个报告一定是轻量级的。我相信后面三个年轻人他们一定会讲很新颖的内容,他们也具有很好的挑战能力来挑战前面的两位元老,从啃鸡肋骨的程序来说,我们刚刚啃了点鸡皮,对吧,后面就要从骨头里面去啃肉了。下面我们欢迎三位年轻的研究人员做报告,首先是邬霞老师。
大家上午好,我叫邬霞,来自北京师范大学。我是做脑信号信息处理的,也希望从我们研究人脑的这个角度来给大家提供一点点信息量。
我们在脑科学里面做视觉信息的提取也是一个比较大的方向,我们主要是做一些数据分析方法,所以对这个问题有一点点的了解。对于我们来看的话,这个层次化的研究,就在视觉上面,可能就像刚刚胡老师说的,可能在V1上是比较可靠的,至于其他的层次,目前应该说研究结果还不能支持我们认为已经按照这个顺序走。从我们研究人脑的结果来看,总体来看,在脑科学里面也仍然是支持这个看法:就是从原始数据视网膜进来的信号,在经过V1简单的特征提取之后会往后面进行传输,然后后面各层次的视觉皮层实现更高级的特征提取。但是,我们认为它可能不光是在视觉皮层上来做,比如后面的V2,MT,甚至V4,V5。我们认为到了更高级的皮层,比如到了前额叶这些地方。肯定不局限在枕叶上面,而且会有更多跟语义相关的脑区来负责。因此我们现在认为,除了V1能被计算机很好的建模以外,其他层次的脑皮层甚至是更高层次的话可能很难直接用一个函数来模拟它。这样就比较复杂,那么现在我们课题组也做一些基于磁共振数据的类似的工作,比如,基于枕叶皮层信号来重构我们看到的图像。比如,我们看到了文字,或者看到了这个画,或者是视频,发现只用枕叶上的脑信号来重构看到的图像是远远不够的,可能还需要其他皮层上的信号。
因此,我认为,就我自己的观点,我觉得如果需要从人脑分析上来构建模型,进而指导计算机视觉,或者说从研究人脑来做这个事情的话,可能不光只枕叶皮层或者视觉皮层,可能需要一些更高层次皮层上的信号来帮助我们。尤其是,我认为,计算机视觉不再只是把这个东西看出来,只是把图像勾勒出来,可能更多的还是在于要把它识别出来,那么这里面肯定会涉及到语义的表达。语义已经到了前额叶这个地方,我觉得可能需要把这些信号引入进来指导后面的识别,像刚才胡老师提到了这个背侧通道和腹侧通道。那么腹侧通道我们认为它是识别是什么,背侧通道可能更多的是告诉你它在哪里,其实还有一个时间。现在脑科学里我们还没有找到这样一个比较显著的脑区,是在腹侧还是背侧还不知道。我觉得可能更多的还需要有其他皮层甚至更高层的,来帮助我们确定。在提取特征的时候,或者是在看这个图像的时候,我个人觉得可能这个自底而上、自上而下的这样一个注意机制应该都会在参与其中,而不是一个被动的接受。现在我认为做计算机视觉就是收到图像以后就提取特征就是从下往上传,那我们人看物体的时候不是这样。大部分情况下你是带着你的目的来看的,你有一个自顶而下的注意力的来指导你来挑选。所以我想,如果计算机视觉要模拟人的这种机制,可能需要一层一层往下传可能会有一个反馈或者说有一个其他的来做这个东西。
第二个问题是说这个瓶颈问题,基于我们的理解,现在人脑在这个初级的V1皮层,是不同细胞是负责不同功能的,提取不同特征。我不知道在计算机视觉里面有没有一个不同的提取特征的方法来,比如说,看纹理的、看方向的,有不同的模块。人脑的细胞其实是分工的,这个是不是可以借鉴过来?第三个问题是这个计算机层次化处理机制。目前从脑科学的研究上来看,仍然是借鉴这个思路来做,就是也会采用层次化的思想来分析数据,只不过大脑里面可能更多的不同层次间的这样一个反馈,这个跟计算机的这个层次化结构,人脑有很多来自高级皮层对低级皮层的这个指导和挑选,这个和计算机这个等级森严的这个层次有所不同,不知道以后是不是可以借鉴。谢谢大家。

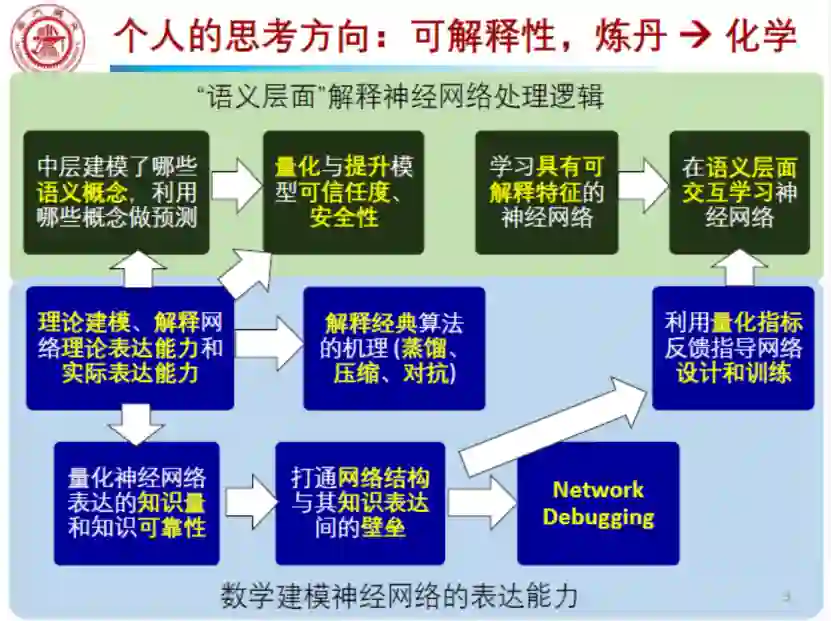
在语义层面解释神经网络具体包括这几个方面:首先,在语义层面,我们希望知道神经网络中层建模了哪些概念,并且利用哪些概念做预测。进一步,我希望量化与提升神经网络的可靠性和可信任度。再就是如何去学习具有可解释的中层特征的神经网络,最后是在语义层面交互式的学习神经网络。以上就是第一方面,也就是在语义层面解释神经网络,这是我之前的工作。
但是,为了将神经网络从炼丹变成一个science,我觉得未来更多要从数学层面建模神经网络内在的表达能力。那么归根到底就是建模几个方面:第一是理论建模跟解释神经网络的理论表达能力和实际表达能力;第二是解释经典算法背后的机理,如蒸馏、压缩、对抗算法的机理;第三就是量化神经网络中层表达的知识量和可靠性,打通网络结构与知识表达之间的壁垒。因为大家现在都在搜索神经网络结构,真正看一个网络结构是否好,归根到底是它所建模的知识是否是正确的、可靠的,所以说如何打通这两者之间壁垒是很重要的问题。当然这些问题我也在探讨中,我之前有做这样的工作,这个是非常具有挑战的。第四是network debugging,即,如何用小量的样本,像debug程序一样直接去修复神经网络的中层表达,这也是我最近在努力尝试的一个方向。最后是量化指标,并用这些量化指标去反馈指导神经网络的设计和训练,这样我们并不是依靠人的经验去指导神经网络的设计和训练,而是像化学方程式一样,有一些定量的指标去帮助指导神经网络的设计和训练。
我这个talk里面大概会提七个问题点。
第一个方面,是神经网络特征的冗余性和可靠性。之前有一个工作我觉得非常有意思,神经网络的输入只有一张图像,并且用来训练的label是任意给的label,网络依旧可以得到百分百的训练正确率。所以,当你的网络得到了一个很高的训练正确率,是否能保证网络建模了正确的知识,这个问题是非常重要的。例如,我们用大红圈表示你之前想要的知识表达,而对于你的这个训练数据集,最好的表达实际上是这个圈,但是这个数据集所能训练到的知识表达是来自这个范围。事实上,我们经常会遇到这样的问题,即,很多该学的知识没有学到。造成这个问题的原因可能有以下两点。一方面是知识盲点,比如说这个范围内的知识,就是blind spot知识盲点。由于数据集采样过程中的一些不可靠的特征,或者说一些bias,可能会导致存在知识盲点,因此有一些知识没法建模。另一方面是不可靠特征,就是说可能学到一些并不是对某个任务最直接相关的一些特征,而是一些间接的、不可靠的特征。那么如何去量化知识盲点与不可靠特征?这是一个很重要的问题。
还有一个很有趣的问题就是:当同一个model在相同结构的情况下训练七八次,那么每一次训练,它所建模的知识是否是相似的?这里需要强调一个概念,相似知识不一定有相似的特征,因为每一次model参数初始化可能是不一样的。所以我定义了知识同构性。比如说A跟B两个神经网络有两个特征,A神经网络特征如果经过一个线性变换直接能得到B神经网络特征,我就认为它是一个最强的知识同构性,是第零阶同构。但如果A特征要经过一个非线性变换才能得到B特征的话,我就认为是第一阶同构,非线性变换意味着存在一些猜测成分在里面,即,我去猜到B特征是什么。如果类似的,经过n次非线性变换得到第n阶同构。那么,对于B特征我能拆分成这么多的同构分量——第零阶同构分量,第一阶同构分量,一直到第K阶同构分量,包括不同构的分量。这样,我们就可以测量不同神经网络之间的一个知识同构性。那么,回到刚才的问题,一个神经网络在相同数据集上训练两次或三次,它所学的知识是否是同构的?在我的测试下,答案是否定的。就是说两个神经网络训练两次,不同构的特征分量占大部分。换句话说,一个神经网络训练两次或三次学的知识相互都是不一样的,但是都能保证百分之百的分类正确率。我这样做的目的是提出一个问题:我们如何去评价神经网络训练的可靠性,如何去量化评价知识盲点、不可靠特征,去探索我们需要获得多少知识才能对这个任务做到百分百准确率。
第二个问题是,如何诊断神经网络知识盲点和不可靠特征。我们假设有两个神经网络,一个是很深层的神经网络,训练的特别好,准确率也非常高;第二个是比较浅层的神经网络。我们假设深层神经网络是ground truth,它是一个真实的、理想的表达,用它去诊断浅层神经网络的知识盲点和不可靠特征。简单来说,我们用浅层神经网络特征去重构深层神经网络特征,那些没有重构的地方就是浅层神经网络没有建模的知识,那就代表了浅层神经网络的知识盲点。而不可靠特征是指当我们用深层神经网络特征去重建浅层神经网络特征,那些不能重建的部分就代表深层神经网络没有建模的一些特征,但是浅层神经网络建模了,我就认为它是不可靠的。总之,我想提出一个如何去量化两个神经网络之间的知识同构性的指标,从而判断神经网络的知识盲点和不可靠特征。那么这是第一个方面,如何去量化神经网络特征的不可靠性和冗余性。
第二个方面,我们希望去量化神经网络的知识量,分析神经网络的特征到底建模了多少知识,而多少知识是不可能用语义去表达的。
第三个方面,就是information-bottleneck theory告诉我们,学习语境相关的知识,那么它到底如何量化不可靠特征,如何量化知识表达的多样性。这也需要提出一些量化指标,分析它建模了多少知识,
第四个方面,神经网络结构与效率的关系。目前,一个网络结构有一个准确率,我们希望知道每一种结构对应每一种作用效率的关系,这有助于建模更复杂的结构来提升鲁棒性,或者遗忘更多不相干的信息。总之,我们希望去建模每种结构的效率。
谢谢大家。
5. 郑伟诗
各位老师好,我主要从我所在的研究领域智能视频监控理解层次化。智能视频监控的一个重要目的是理解人在做什么,这往往涉及跨场景事件的理解。为实现这个目的,首先需要在单个场景检测人,理解个人的行为。如果再把这个理解逐渐扩展到更多摄像头下的理解,比如说20个摄像头的时候,那么这就是从单场景从多场景,形成由一到多、由点到面、由简单到复杂的层次化分析。如果再往复杂一点想的话,在智能视频监控中,需要考虑像多模态的、多粒度的融合,由于不同模态之间有显而易见的鸿沟,要实现不同模态之间、视频多帧时空之间的多对象交互,需要结合多层次、不同时间的、不同粒度的信息,并进行多源对象的交错关联建模。
具体的层次化分析是不容易的。以行为意图识别为例,研究发现一个行为并不是每个时刻信息都很重要,而是一个动作的中间信息,在中间发生的信息是最重要的,而动作的中后期信息已经不起决定性作用了。也就是说,研究发现当一个动作发生到中间的时候几乎可以判断出它是什么了。所以,就单一动作来说,在这种层次化建模的时候,时空信息就有偏好性。对于更复杂的事件,像长时间的行为,它不是单一的动作理解,而是连续动作的理解,那么究竟哪个时刻和哪个动作能够对后面时刻的哪个动作起着决定性的预测作用,这就变得更加复杂了。如果是理解一个更复杂的场景,这个场景下可能会有多人检测、动作识别等;如果要实时处理,还需要实现快速检测,并需要把人的检测和人动作识别融在一起;如果要更进一步理解群体行为,那么就需要形成了一种更复杂的交错关联处理。
作为一个小小的总结,我们可以从层次化分析方面去理解智能视频监控的任务,而且层次之间是有偏好性的,不同层次之间具有交错关联的特性。为解决这些问题,或许我们需要大量的标注,但是视频监控标注非常困难,而且代价高昂。因此,如果要把这种错综复杂的关系学好的话,我们需要做无监督、弱监督学习。另外,可能还需要考虑把常识建模嵌入进来,通过常识建模来减少数据量需求。这是我的一些想法。谢谢大家。
三、讨论嘉宾发言实录
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京/深圳
职务:以参与学术顶会报道、人物专访为主
工作内容:
1、参加各种人工智能学术会议,并做会议内容报道;
2、采访人工智能领域学者或研发人员;
3、关注学术领域热点事件,并及时跟踪报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:cenfeng@leiphone.com






