报名 | CSIG“图像视频理解”学科前沿讲习班

图像视频的自动理解是人工智能的核心问题之一,在深度学习技术的有力推动下,近年来得到了快速发展,一方面传统任务的技术方法不断迭代,性能指标屡创新高;另一方面新思想和新任务也不断涌现,对如何解决此问题的认识也日益深入。当前,图像视频理解正在和知识表示、逻辑推理、语言处理等其他人工智能相关技术产生深层次的关联,呈现出多领域交叉的态势。图像视频理解的输出结果已不仅是有限的几个概念,而是更加知识化、结构化和语言化。从历史的角度来看,图像视频理解技术虽然蓬勃进步,但仍处在变革发展期,其科学问题、关键挑战、技术方案等还在不断演化,还有很大的研究空间。
第12期CSIG图像图形学科前沿讲习班(Advanced Lectures on Image and Graphics,简称IGAL)将于2019年7月30日-31日在清华大学举办,本期讲习班主题为“图像视频理解”,由中科院计算所陈熙霖研究员担任学术主任,邀请计算机视觉、多媒体与人工智能领域的一线青年专家作特邀报告,使学员在了解学科前沿、提高学术水平的同时,增强与国内外顶尖学者的学术交流。
组织单位:中国图象图形学学会
承办单位:CSIG多媒体专业委员会 清华大学
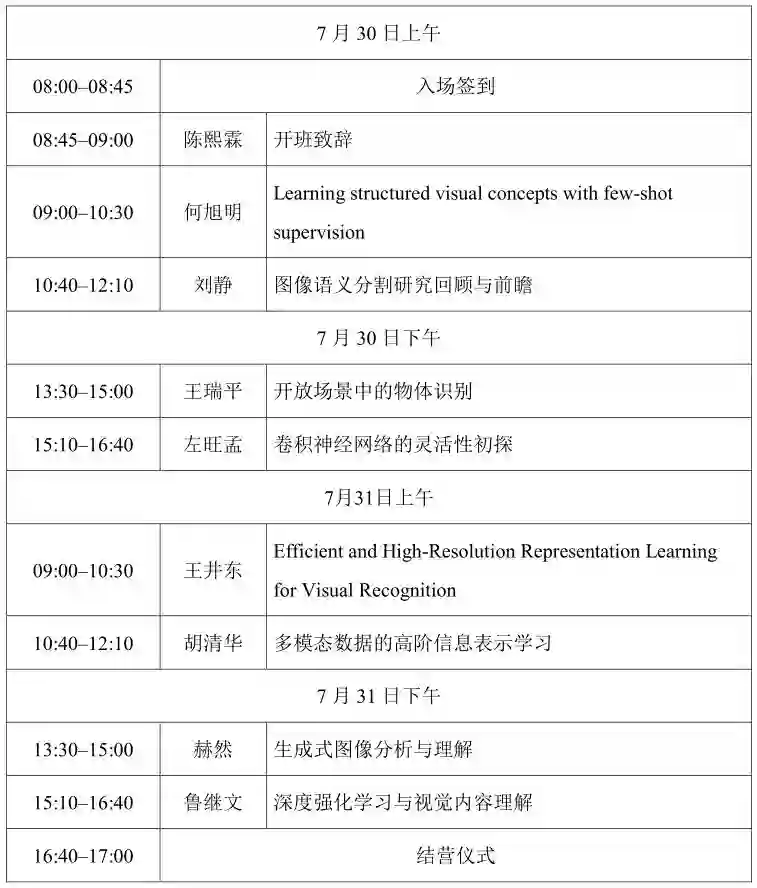
2019年7月30日-7月31日
清华大学罗姆楼三层报告厅

陈熙霖
中科院计算所研究员、博导
IEEE /IAPR Fellow
个人简介:陈熙霖,中科院计算技术研究所研究员,IEEE /IAPR Fellow、中国计算机学会会士。主要研究领域为计算机视觉、模式识别、多媒体技术以及多模式人机接口。目前是IEEE Trans. on Multimedia的AE和Journal of Visual Communication and Image Representation的Senior AE、计算机学报副主编和模式识别与人工智能副主编,任FG2013 / FG2018 General Chair、CVPR 2017/2019/2020, ICCV 2019等Area Chair。先后获得国家自然科学二等奖1项,国家科技进步二等奖4项。在国内外重要刊物和会议上发表论文200多篇。
(按讲者姓氏拼音排序)

赫然
中科院自动化所研究员、博导
国家优青
报告题目:生成式图像分析与理解
报告摘要:视觉是人类感知外部世界的主要途径,视觉数据生成主要通过视觉认知机理感知图像或视频数据的内容或表观,进而由概率生成模型进行学习与拟合。它通过对视觉数据进行重组、渲染或再生,进而创造出在内容或表观上完全不同的视觉数据。从影视、文化、艺术和安全等领域,到人们的日常生活,视觉数据生成都在其中具有广泛应用,并扮演重要角色。由于视觉数据具有维度高、体量大、内容复杂等特点,因此生成高维、真实的视觉数据一直是机器学习和计算机视觉等领域的重要研究内容和长期研究目标。本报告主要介绍与视觉数据生成相关的视觉信息采集、视觉认知机理和概率生成模型,并从生成式机器学习角度分析图像视频理解的行业需求以及对人工智能发展的影响。

何旭明
上海科技大学副教授
报告题目:Learning structured visual concepts with few-shot supervision
报告摘要:Despite recent success of deep neural networks, it remains challenging to efficiently learn new visual concepts from limited training data. To address this problem, a prevailing strategy is to build a meta-learner that learns prior knowledge on learning from a small set of annotated data. However, most of existing meta-learning approaches rely on a global representation of images or videos which are sensitive to background clutter and difficult to interpret. In this talk, I will present our recent work on learning structured visual representations for few-shot recognition. The first topic is on few-shot action localization, in which given a few annotated examples per action class, we aim to find the occurrences of these action classes in untrimmed videos. Towards this objective, we introduce a meta-learning method that utilizes sequence matching and correlations to learn to localize action instances. In the second half of the talk, we will discuss a new few-shot classification method based on two simple attention mechanisms: one is a spatial attention to localize relevant object regions and the other is a task attention to select similar training data for label prediction. We will demonstrate the efficacy of our methods on several real-world datasets, including THUMOS14, ActivityNet and MiniImageNet.

胡清华
天津大学教授、博导
国家优青
报告题目:多模态数据的高阶信息表示学习
报告摘要:文本图像语音视频等数据被广泛用于表达语义信息,这些多模态数据互为补充、有时又相互矛盾,不同模态间蕴藏着复杂的高阶关联。近些年提出了多种高阶表示以挖掘和利用多模态数据之间的复杂关联,实现有效的多模态数据融合。本报告将介绍多模态数据的应用场景、多模态数据的高阶表示以及基于高阶表示的多模态数据的高效融合策略。

刘静
中科院自动化所研究员
报告题目:图像语义分割研究回顾与前瞻
报告摘要:图像语义分割是一种像素级的分类任务,其目标为精确确定图像中物体的位置和类别,可被广泛用于无人驾驶、医疗诊断、图像编辑、人机交互等不同领域。基于全卷积网络(FCN)的图像语义分割作为一项里程碑式工作,开启了基于深度学习的图像语义分割的研究探讨,并在近几年取得了飞速的发展。针对图像语义分割中遇到的分割边缘粗糙、容易丢失较大或较小目标等问题,研究者们提出了一系列的改进应对策略。本报告将回顾继FCN之后,通过增加模型感受野、反卷积网络、融合全局上下文与多尺度信息等不同改进方式的各项研究工作进行综述,同时介绍本人近期的相关研究工作,最后对图像语义分割未来值得探讨的研究问题进行简单讨论。

鲁继文
清华大学副教授、博导
国家优青
报告题目:深度强化学习与视觉内容理解
报告摘要:深度强化学习是人工智能领域的研究热点,被认为是人类迈向通用人工智能的重要手段之一。深度强化学习通过将深度学习的感知能力与强化学习的决策能力相结合,以端对端的方式实现从原始输入到高层语义的感知与决策,在许多视觉内容理解任务中均取得了重要进展。报告首先简述深度强化学习的基本概念与原理,然后将重点介绍近年来面向视觉内容理解所发展的多个深度强化学习方法,包括多智能体深度强化学习、图深度强化学习、和结构化深度强化学习等,以及它们在物体检测与识别、目标跟踪与检索、行为预测与识别、图像与视频编辑、和深度模型压缩等多个视觉内容理解任务中的应用。

王井东
微软亚洲研究院研究员
IAPR Fellow
报告题目:Efficient and High-Resolution Representation Learning for Visual Recognition
报告摘要:Convolution neural networks have been dominant solutions for visual recognition. I first introduce a novel framework: Interleaved Group Convolution (IGC). It uses the product of structured sparse kernels to compose a dense convolution kernel, removing the redundancy in convolution kernels and improving both computation and parameter efficiency. The IGC network, similar to concurrently-developed ShuffleNet, is superior to MobileNet.Then, I will present our high-resolution network framework (HRNet). The HRNet maintains high-resolution representations by connecting high-to-low resolution convolutions in parallel and strengthens high-resolution representations by repeatedly performing multi-scale fusions across parallel convolutions. The effectiveness is demonstrated in many visual recognition problems: human pose estimation, semantic segmentation, object detection, facial landmark detection, and ImageNet classification. It outperforms U-Net, Hourglass, and other state-of-the-art segmentation and pose estimation networks. The HRNet turns out to be a strong replacement of classification networks (e.g.ResNets, VGGNets) for visual recognition. We believe that the HRNet will become the new standard backbone.

王瑞平
中科院计算所研究员、博导
报告题目:开放场景中的物体识别
报告摘要:通用物体识别是视觉场景理解的基础核心任务之一,近年来得益于深度学习技术的发展和互联网大数据的繁荣,取得了显著的进步,当前主流方法在相对封闭场景的数据集上甚至超越了人类视觉系统的识别能力。本报告将首先简要回顾过去几年物体识别任务在数据构建、方法研究方面所取得的主要进展;接下来分析真实开放场景中面临的主要挑战,包括:海量物体类别间的复杂语义与视觉关联、开放场景中天然的长尾分布导致的标注数据稀缺、跨场景应用所面临的视觉识别模型推广与知识迁移等;之后将重点介绍本课题组近几年围绕开放场景识别所开展的一些探索,包括:属性与类别关联的多任务图像检索、属性辅助的零样本物体识别、开放环境下的增量物体识别、场景推理驱动的物体检测与关系分析等。

左旺孟
哈尔滨工业大学教授、博导
报告题目:卷积神经网络的灵活性初探
报告摘要:当前的计算机视觉解决方案中,往往需要对各种视觉任务设计相应的网络结构。对于一些底层视觉任务如图像去噪,甚至针对每一种典型的噪声水平都需要重新学习一个深度网络模型。报告将通过分析这一问题,主要结合底层视觉和图像转换介绍一些可行的解决思路。此外,对一些单一高层视觉任务,也可以通过引入类似的角度设计和学习深度网络来改善模型性能和适应性。报告将简介我们近年来在这些方面的一些探索和发现,希望能为大家从(1)条件变量的引入和编码、(2) 条件变量与输入的相互作用机制、(3) 条件变量估计等角度改善模型的自适应性,进一步发展和应用深度卷积网络起到抛砖引玉的作用。
1、本期讲习班限报200人,根据缴费先后顺序录取,报满为止。
2、2019年7月29日(含)前注册并缴费:
CSIG会员1600元/人,非会员报名同时加入CSIG 2000元/人(含1年会员费);同一单位组团(5人及以上)报名,1600元/人;
现场注册:会员、非会员均为3000元/人;CSIG团体会员参加,按CSIG会员标准缴费。
3、注册费包括讲课资料和2天会议期间午餐,其它食宿、交通自理。
登录活动系统:http://conf.csig.org.cn/fair/359 或扫描下方二维码在线报名缴费。

联系人:骆岩峰 / 黎新
联系电话:010-82544676 / 17812762235(微信同号)
邮箱:igal@csig.org.cn

扫描二维码添加工作人员微信

点击“阅读原文”进入报名系统


