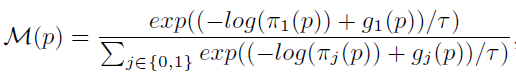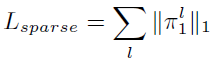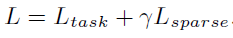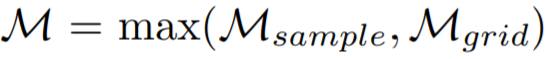同一张图像的不同区域空间冗余度是不一样的,背景部分的冗余度往往低于人物区域。如何利用这种特性来节省模型推理的计算量呢?在一篇 ECCV 2020 Oral 论文中,来自微软亚洲研究院等机构的研究者提出了一种随机采样与插值相结合的新方法,可以有效降低节省推理的计算量。
![]()
近年来,随着深度学习的不断发展,视觉领域出现了越来越多的高精度模型,但这些模型所需的计算量也越来越大。因此,如何在推理阶段避免冗余的计算在近年来成为研究热点。
为了解决这一问题,研究者提出了一系列相关算法,如模型剪枝(Model Pruning)、模型量化(Model Quantization)、提前终止(Early Stopping)和利用特征响应稀疏性(Activation Sparsity)等方法。
在本文中,来自微软亚洲研究院视觉计算组、清华大学以及中国科学技术大学的研究者们提出了一种利用图像的空间冗余特性来节省计算量的新范式——
利用随机采样与插值来进行动态推理
。在实验部分,研究者在物体检测(COCO2017)与语义分割(Cityscapes)两种任务上验证了该方法的有效性。
![]()
论文地址:https://arxiv.org/abs/2003.08866
图像的空间冗余是指:在图像中,空间上相邻的的位置对应的特征与内容通常也较为相似,因此,某一位置的特征可以通过其临近区域其他位置的特征进行插值得到。这种特性在自然图像里十分常见,是自然图像的一种内禀属性。
利用这种特性降低计算量在计算机视觉领域并不罕见,如通过缩小输入图片的尺寸,或在主干网络中通过 Pooling 或 Stride Conv 来降低特征图的分辨率就是两种常见的方法,而这两种方法均可以被看作在空间上进行均匀采样 (Uniform Sampling) 。
![]()
但是,图像冗余在空间上并不是均匀分布的,如 Fig. 1(a) 所示,人物、路灯等区域的冗余度较低,而地面、背景墙等区域的冗余度较高。因此,在空间中进行均匀采样并不能充分利用空间的冗余特性。更好的方式应当是自适应地决定采样位置。
![]()
提前中止法(Early Stopping)与利用特征响应稀疏性(Activation Sparsity)的方法均可被视为实现自适应采样的不同方式。在这些方法中,每个位置都对应一个分数,代表该位置的重要程度。如果分数大于一个阈值,该位置就会被采样。我们称这类采样方法为确定性采样(Deterministic Sampling),如 Fig. 2 (b) 左图所示。然而,由于空间冗余特性的存在,邻近的位置得分往往接近,因此,在确定性采样中,一片相邻的区域经常同时被采样到或者同时不被采样到(如 Fig. 1 (b) 所示)。
本文提出使用随机采样(Stochastic Sampling)与插值相结合的方法来节省计算量。在随机采样中,每个位置的分数仅代表其被采样到的概率。分数越高,其被采样的概率越大,反之亦然。因此,对于一个拥有相同分数的区域,只要其概率不是 1,则仅会有一部分位置被采样到(如 Fig. 2 (b) 右图所示)。而未被采样到的位置,其特征可以借助邻近被采样到的点通过插值来近似。通过这种方法,可以在获得与确定性采样相似精度的情况下,使用更少的采样点进行计算(如 Fig. 1 (c) 所示),或使用一样多的采样点取得更高的精度(如 Fig. 1(d) 所示)。
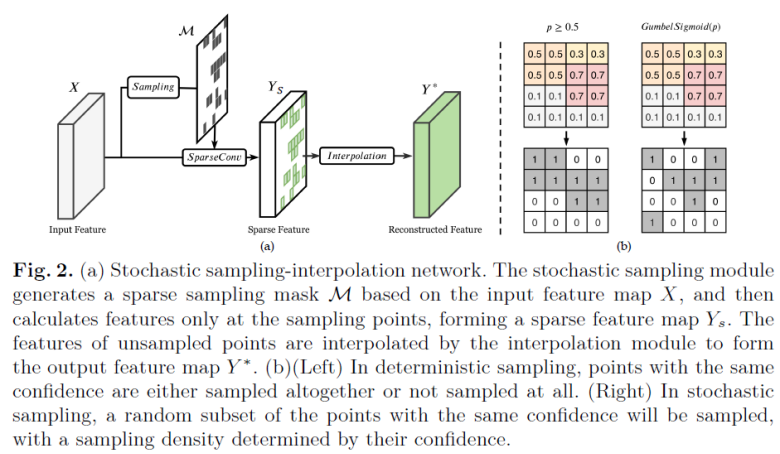
按照上述分析,本文提出了随机采样 - 插值网络(如 Fig. 2(a) 所示)。该网络包含采样模块、稀疏卷积与插值模块三个部分。
本文使用二类的 Gumbel-Softmax 来模拟离散采样的过程,其定义如下:
![]()
其中π表示采样概率,由一个3×3卷积和 Sigmoid 函数输出,g表示噪音项,这是 Gumbel-Softmax 随机性的根源。如果去掉噪音项g,则 Gumbel-Softmax 退化为一个确定性采样方法。τ则是温度项,当温度较高时,M是一个可微的连续函数,而当温度较低时,M退化为一个二值函数。温度项的初始值在训练开始时被设为 1,然后随着训练轮数的增加指数级下降,在训练结束时,τ接近于 0。通过这种方式,掩模M既可以在训练的中前期被充分训练,又能在训练后期使得M接近于一个二值化掩膜,从而保持与推理阶段一致的行为。同时,为了激励网络产生稀疏的采样掩膜,本文引入稀疏损失函数(Sparse Loss),其定义如下:
![]()
将其与下游任务的损失函数结合,就可以得到最终的目标损失函数:
![]()
其中,γ是稀疏损失的权重,通过调整γ我们可以获得不同程度的稀疏性。
在使用采样模块生成采样掩膜M后,我们可以利用稀疏卷积来得到稀疏的特征图Y_S,再通过插值模块对Y_S进行补全,得到完整的特征图Y^*。然而,补全特征所需要的最优插值形式是一个开放性问题。本文探索了三种不同的插值函数:RBF Kernel、Plain Convolution 以及 Average Pooling,并在实验中发现 RBF Kernel 表现优于其他两种函数,因此本文将其作为默认的插值方法。
同时,由于空间冗余具有局部性,因此我们可以使用滑动窗来实现高效的插值。为了避免在滑动窗内没有采样点的情况,本文额外使用了一个等间距均匀采样,但高度稀疏的掩膜M_grid与网络学习到的掩膜M_sample通过如下方式结合,得到最终使用的掩膜M:
![]()
利用这个技术,尽管最终性能并不受太多影响,但网络的训练过程可以变得更加稳定。
![]()
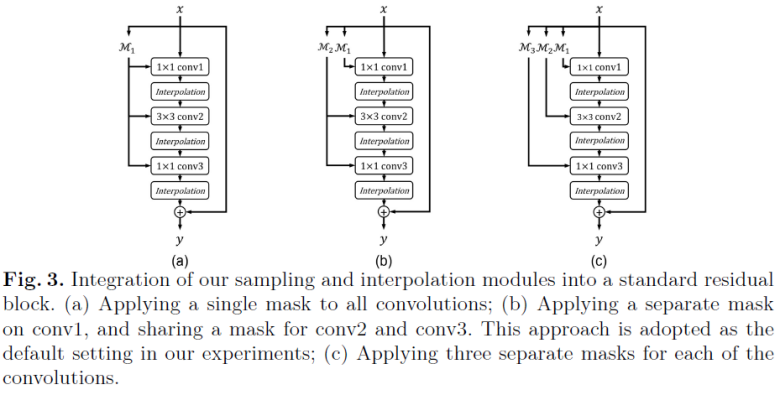
随机采样 - 插值网络可以被很容易地集成到常见的网络架构中,在此,本文以 Residual Block 作为例子进行介绍。如 Fig.3 所示,有三种不同的集成方法,作者通过实验发现 Fig.3 (b) 的效果最好,因此使用其作为默认设定。
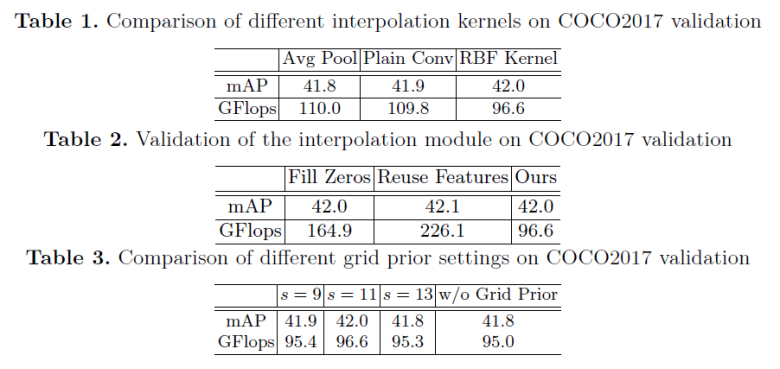
本文在 COCO2017 物体检测数据集上对其关键设计进行了验证。不同插值函数对结果的影响如 Table.1 所示:在 mAP 相当的情况下,RBF Kernel 使用了更少的计算量。Table. 2 则比较了去掉插值模块对结果的影响。其对应的两个基线模型:对未采样区域的特征进行补零(Fill Zeros)或使用复用特征(Reuse Feature)均明显劣于本文所提出的插值方法。Table. 3 则研究了 Grid Prior 对结果的影响。
![]()
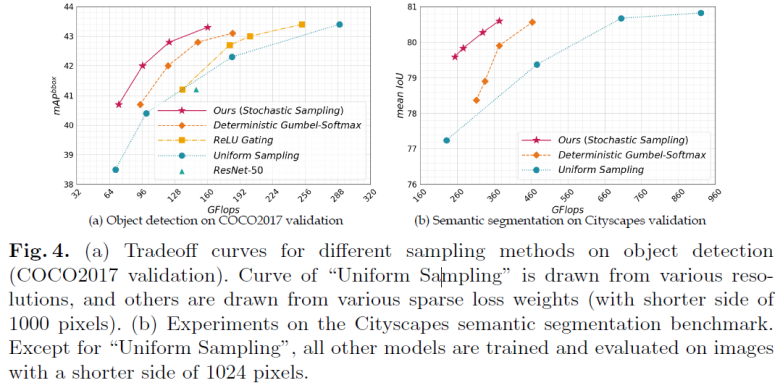
Fig.4 中展示了本文所提出的方法与其他方法在 Speed-accuracy trade-off 下的比较。相比于基于均匀采样的方法(即缩小输入图片的尺寸),该方法效果提升十分显著。而与其他确定性采样方法相比,该方法也具有明显的优势。
![]()
![]()
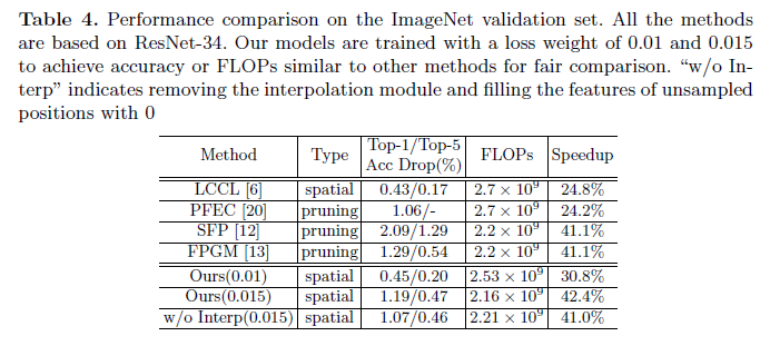
Table. 4 展示了图像分类中该方法与其他方法的比较。总的来说,本文所提出的方法在图像分类中并无显著优势。
作者猜测,这是因为图像分类专注于获取全局表示(Global Feature Representation),因此仅需保留一部分重要的区域就可以获得良好的性能,重构整个特征图对分类任务并无必要。
通过将插值模块移除,作者发现性能的确没有显著的变化,也验证了该猜想。
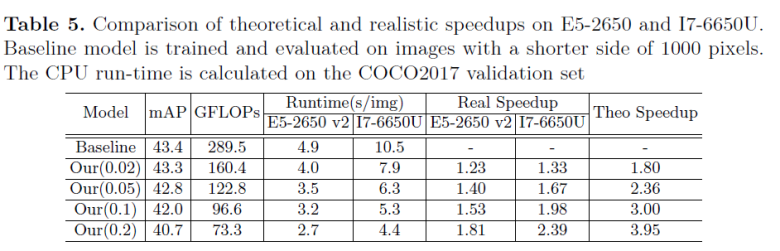
作者还验证了该方法在 CPU 上的实际加速比。为了展示在不同硬件条件下的情况,作者使用了 Workstation(E5-2650 v2) 以及 Laptop(I7-6650U) 两种不同的测试环境,结果如 Table. 5 所示。可以看到,该方法的实际加速比与理论加速比仍然具有较大的差距,但是在 Laptop 下的加速比要好于 Workstation,这也说明该方法也许更适合在低资源情况下应用,如移动端以及边缘计算设备。
![]()
![]()
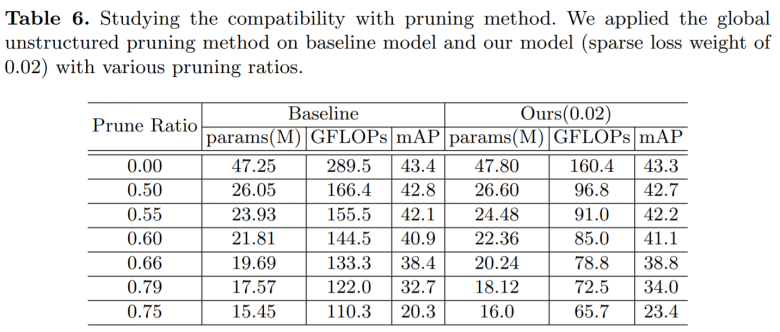
本文所提出的方法利用了图像的空间冗余特性,其机制与现有基于模型结构化的加速方法正交,因此两类技术理论上应该相互兼容,作者也对此进行了验证,结果如 Table 6 所示。可以看到,本文所提出的方法在不同的 Prune Ratio 上的表现均好于 Baseline,证明了该方法与 Model Pruning 技术的兼容性。
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com