从神经搜索到多模态应用
导读:本次分享的题目为从神经搜索到多模态应用,这里的神经搜索指的是在搜索系统中用神经网络模型。提到神经搜索就必然想到多模态数据,因为神经网络相比于传统搜索方式,其最大的优势就在于可以很方便地对不同模态的数据进行融合。
从神经搜索到多模态应用
多模态数据
多模态应用服务
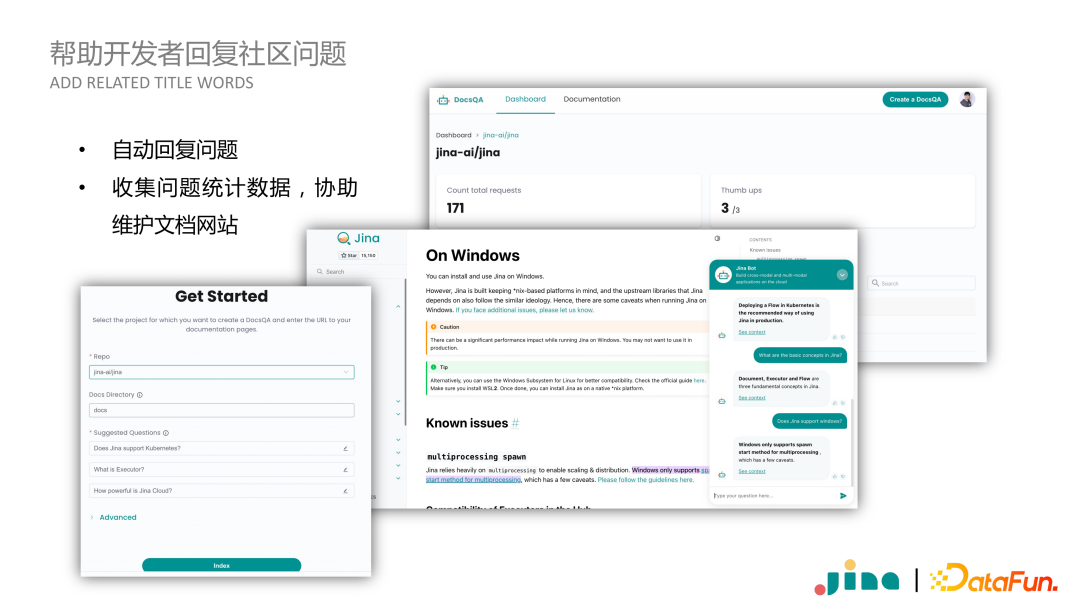
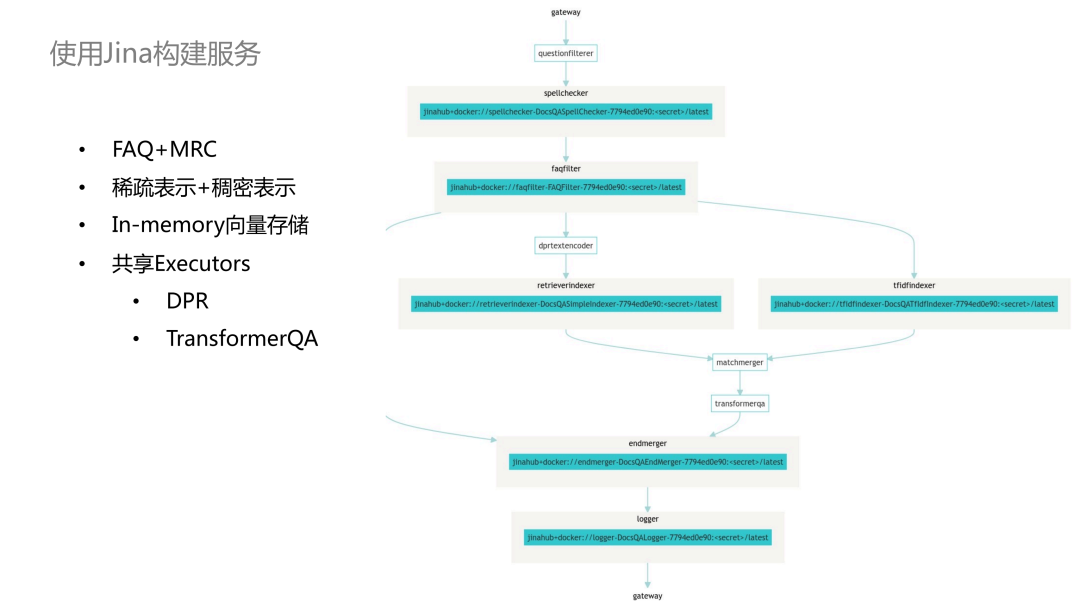
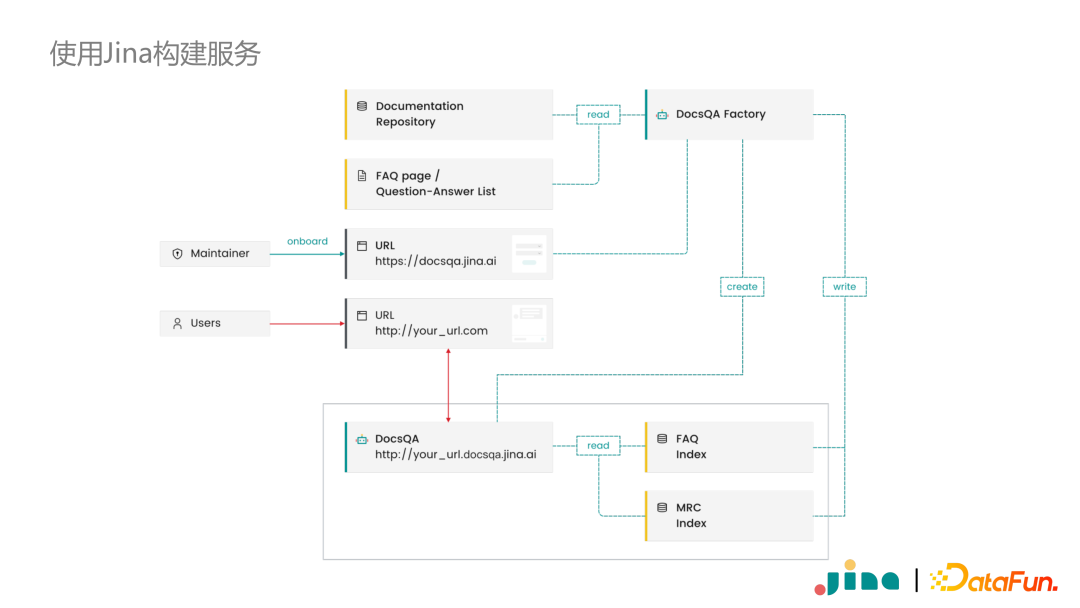
Jina全家桶在DocsQA中的实践
分享嘉宾|王楠博士 Jina AI 联合创始人兼CTO
编辑整理|宋世伟 vivo
出品平台|DataFunTalk
01
从神经搜索到多模态应用





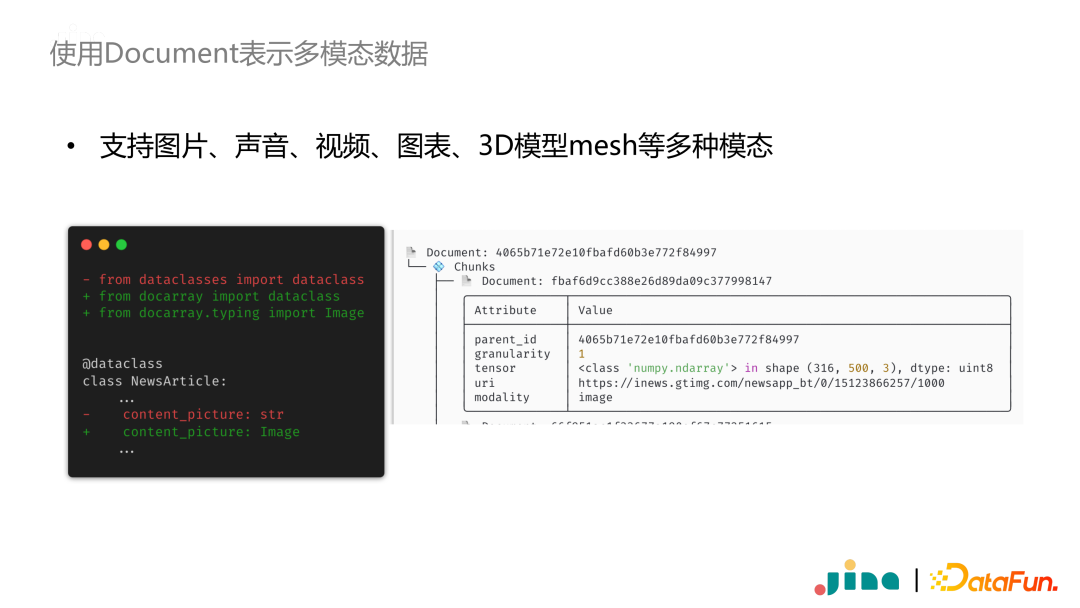

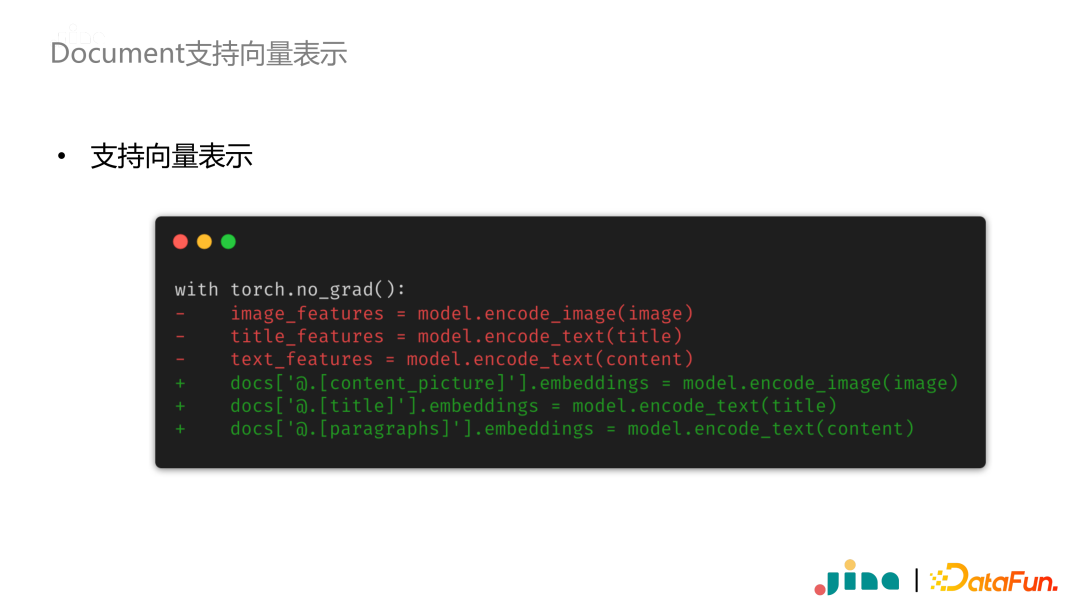
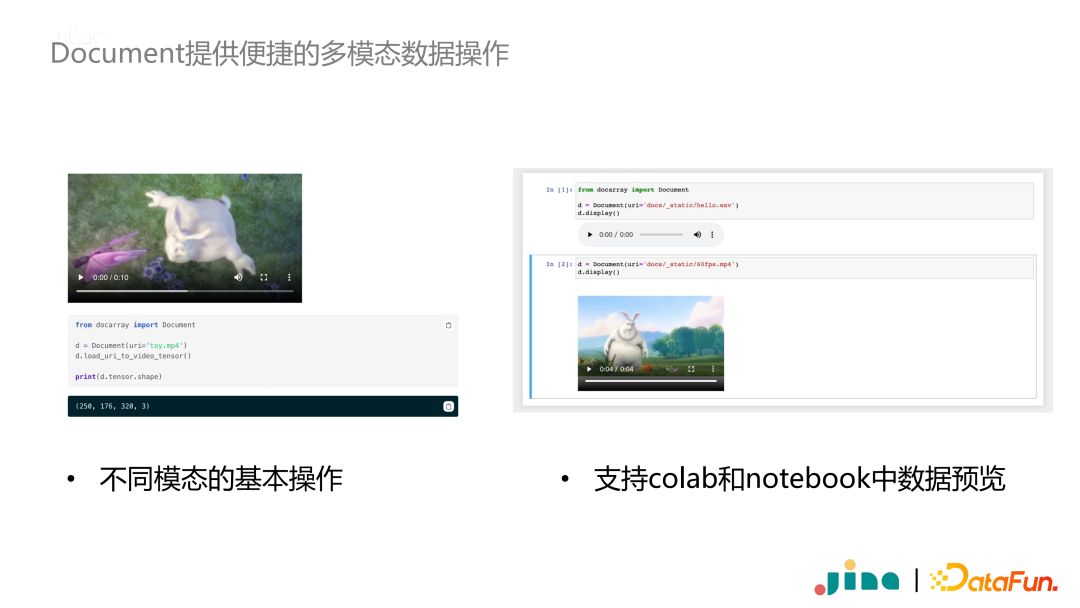




-
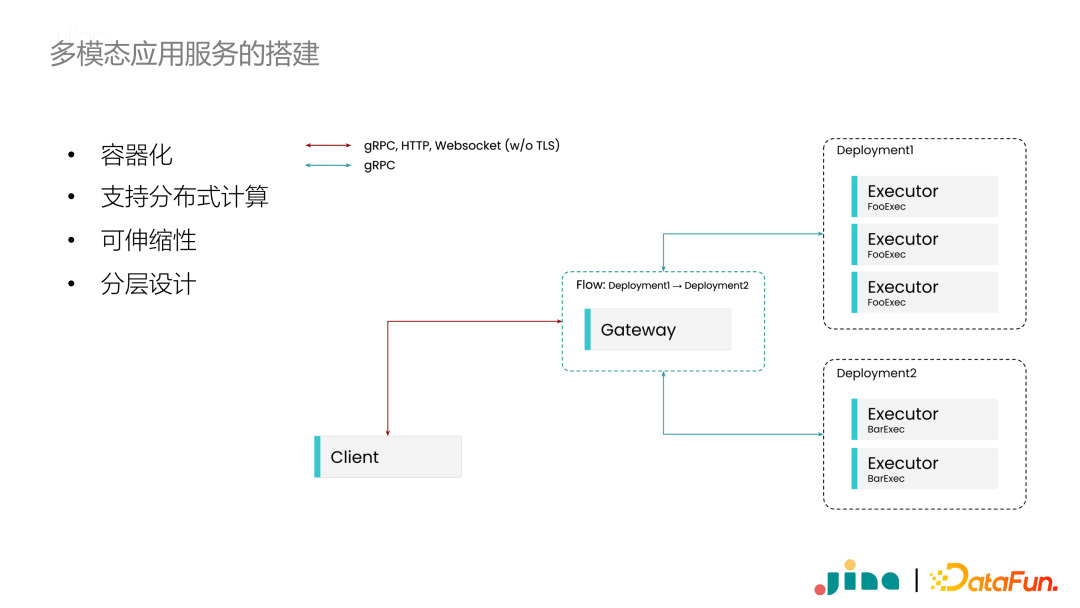
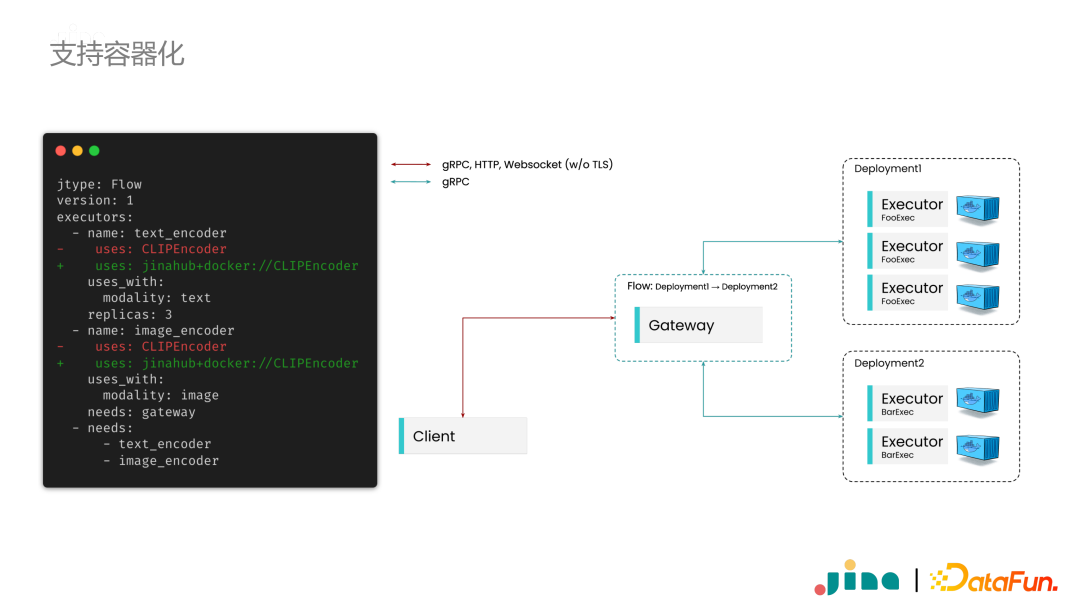
搭建多模态应用离不开神经网络模型,当上线神经网络模型时,经常遇到框架版本和开发环境不一致的问题。这是通常是需要使用容器化,同时保证不同容器之间正常通信。这在工程上是一个非常有挑战性的问题。 -
第二,因为需要对外提供服务,所以开发者往往需要自己搭建对外服务的接口。大家会使用 FastAPI,Flask 或者 GraphQL 等等,有时下游服务还可能要求用 gRPC,有的用 http,这些接口都需要去开发者去适配。 -
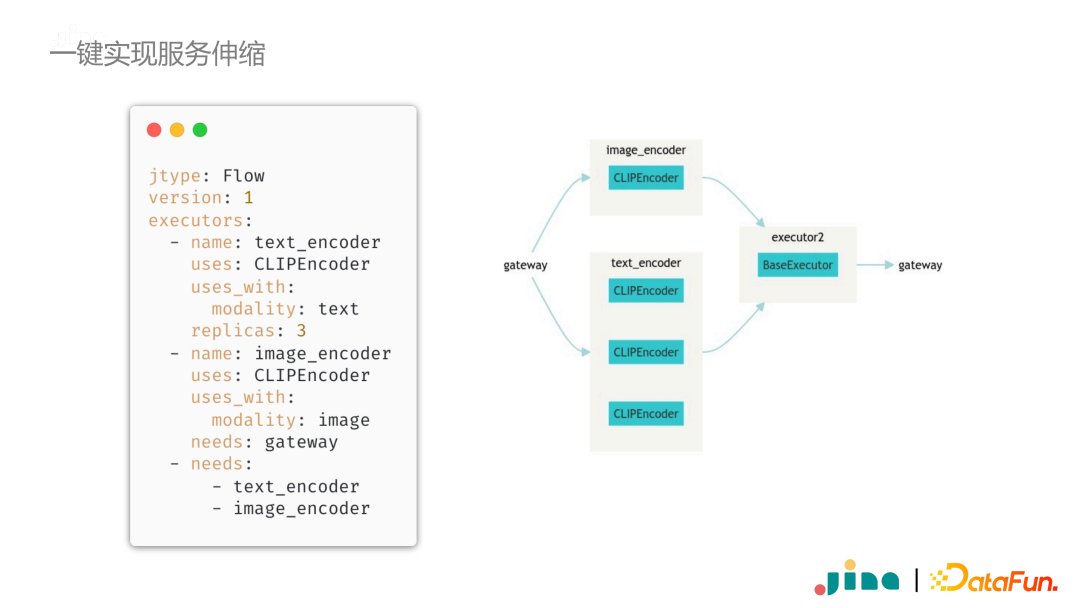
第三点就是因为多模态的数据和应用服务往往会涉及很多模块,每个模块对算力的要求差异非常大。因此搭建服务时通常都炫耀分布式的系统,保证不同的模块在不同的机器上运行,同时保证伸缩性,比如在计算量大的模块中使用多个副本进行并行处理。 -
第四点,现在生产环境都是在 基于 Kubernetes 的云原生环境。如果自己去完成,则需要对常用的监控、报警等工具有一定的了解。整个过程全部搭建完成,不包括模型调优的时间,也至少需要几个星期时间。










专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“多模态” 就可以获取《多模态专知资料合集》专知下载链接



登录查看更多
相关内容
Arxiv
15+阅读 · 2022年1月5日
Arxiv
26+阅读 · 2020年12月29日


相关VIP内容
相关资讯
相关论文
Arxiv
15+阅读 · 2022年1月5日
Arxiv
26+阅读 · 2020年12月29日