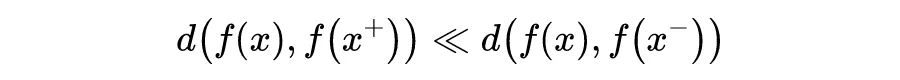![]()
©PaperWeekly 原创 · 作者 | 小马
单位 | FightingCV公众号运营者
研究方向 | 计算机视觉
背景
目前随着数据量爆炸式的增长,靠人工去标注更多数据是非常昂贵,并且也不太现实的。因此预训练的方式就出现了,也逐渐成为了一种主流的方法。那到底什么是预训练呢?简单地说,预训练就是:“使用尽可能多的训练数据,从中提取出尽可能多的共性特征,从而能让模型对特定任务的学习负担变轻。”
预训练将学习分成了两步:
1)首先将大量低成本收集的训练数据放在一起,经过某种预训方法去学习其中的共性知识 ;
2)然后,再使用相关特定域的少量标注数据进行微调,模型就可以从共性知识出发,学习这些特定领域数据的特性知识 。
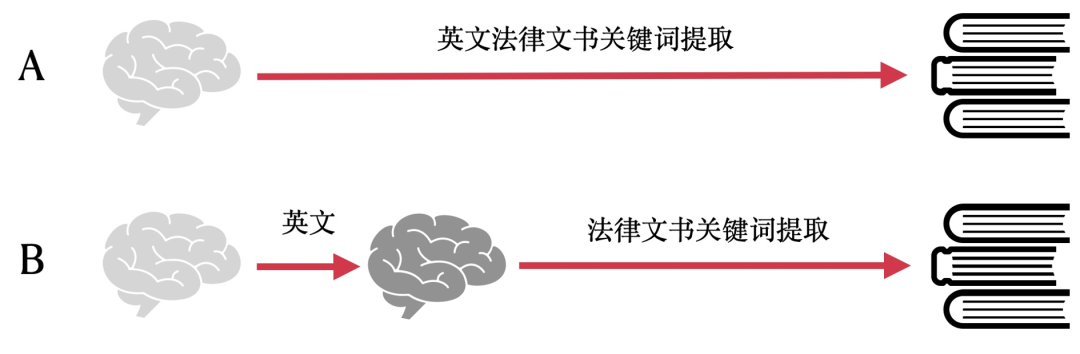
![]()
举个例子,如上图所示,比如我们要学习“英文法律文书关键词提取”这个任务,最直接的方法就是 A 中的学习步骤一样,直接从这些已经标注好的英文法律文书关键词的数据集上进行学习,这也就是深度学习里面最常见的一种学习方法——监督学习 ;还有一种方法就是,我们先在大量不需要标注的英文资料和法律资料上进行学习,然后再在标注好的“英文法律文书关键词”数据集上进行学习,由于我们在学习大量英文资料和法律资料的时候已经具备了一定的知识基础,所以在学习特定任务的时候就会有更高的效率,这就是“预训练+微调”的思路。通常情况下,“预训练+微调”的方法能够比传统监督学习的方法具有更快的拟合速度和更高的性能上限 。
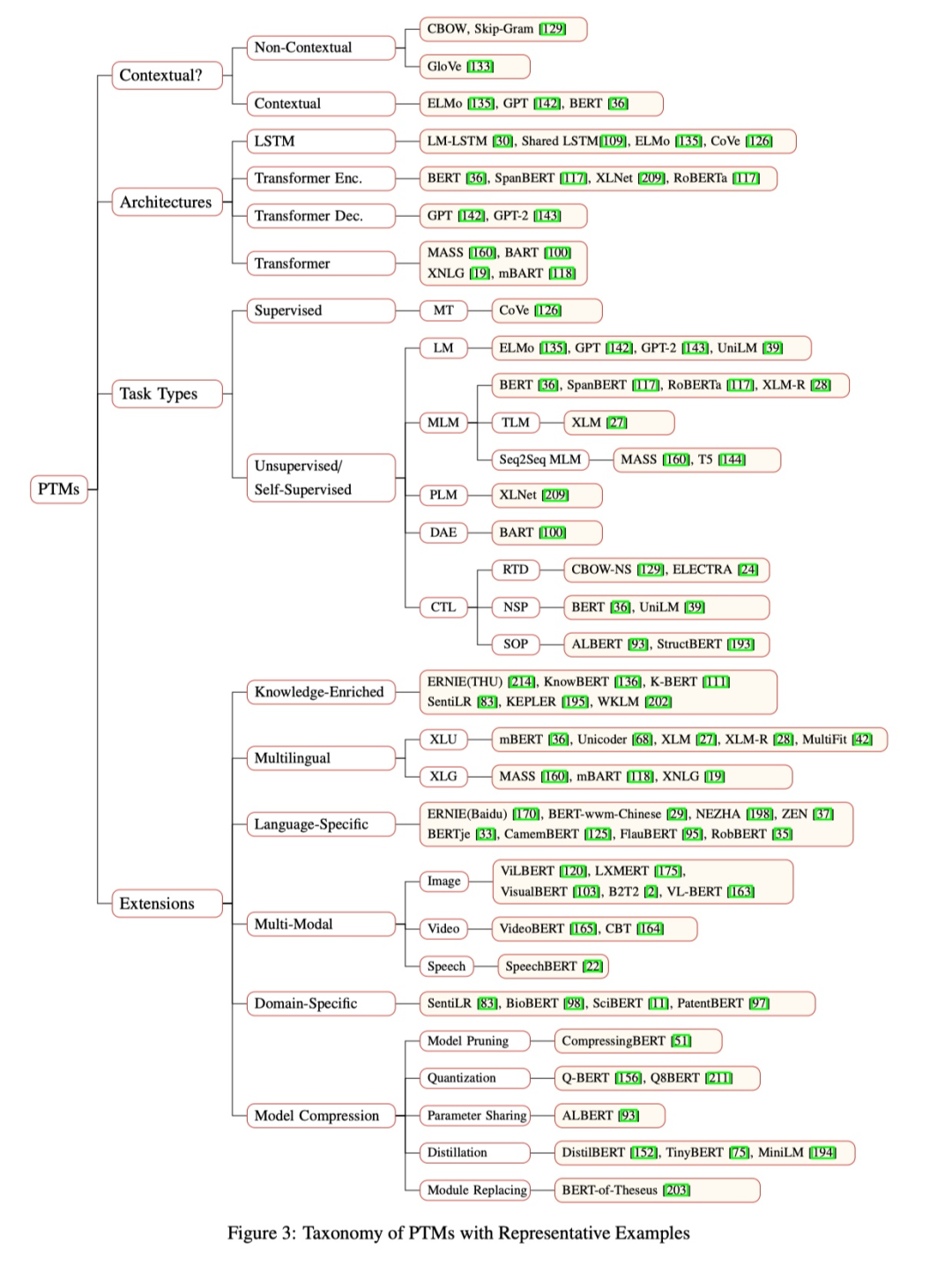
![]()
在多模态预训练模型出现之前,预训练首先是在 NLP 中出现的,上图展示了 NLP 任务中预训练近几年的发展。因为过去几年,文字数据是非常多的,所以不少研究者爬取了大规模的本文数据,基于这些大规模的文本数据,用一些简单的预训练任务进行预训练,然后在下游任务上进行微调,实现了非常好的效果。
下面简单的介绍一个 NLP 预训练中比较经典的模型——BERT:
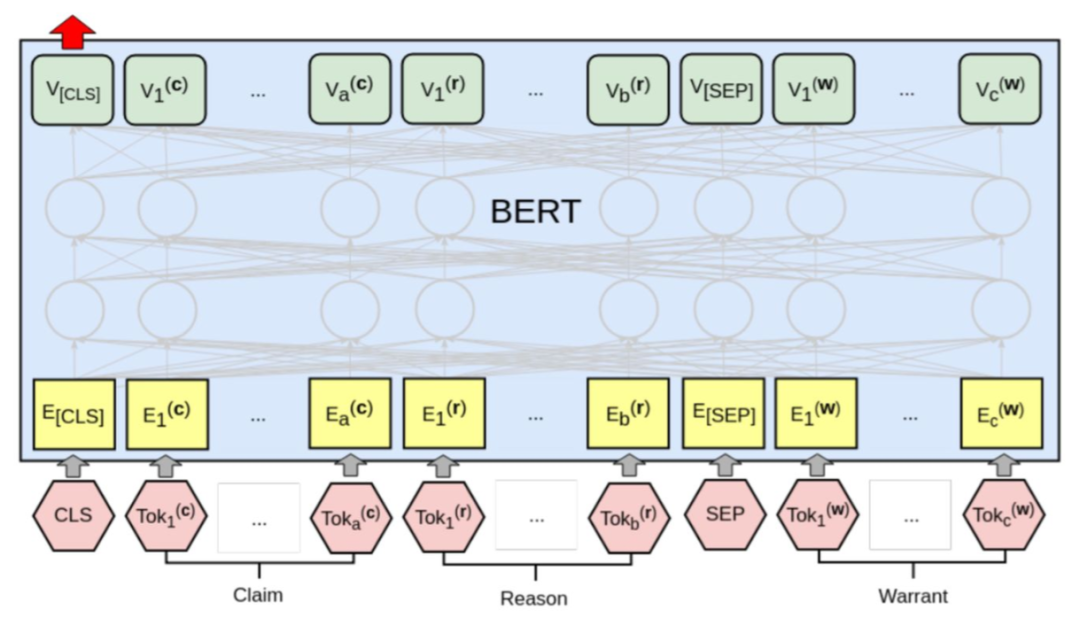
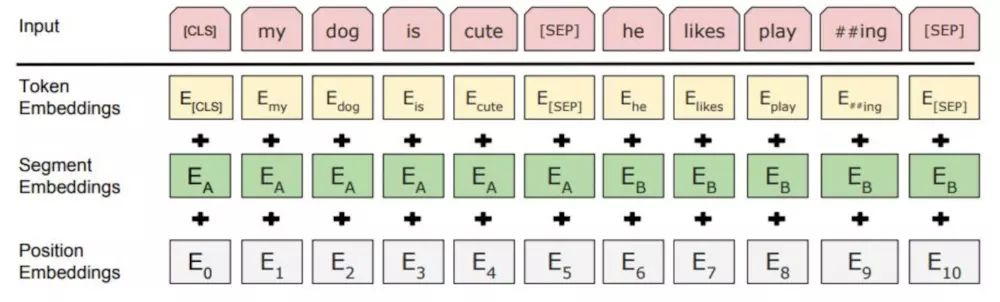
![]()
Token Embedding:对输入的句子采用 WordPiece embeddings 之后的结果。
Segment Embedding:相邻句子采用不同的标志分隔,形如 111111111100000011111100000。
Position Embedding:Transformer 中的绝对位置编码,赋予句子中每个单词位置信息。
BERT 的结构如上图所示,首先就是将三类 embedding 的结果进行相加得到输入,然后利用基于 Transformer 的结构对输入的特征进行建模。在预训练过程中,主要执行两个任务:
1)Mask LM :在选择 mask 的 15% 的词当中,80% 情况下使用 mask 掉这个词,10% 情况下采用一个任意词替换,剩余 10% 情况下保持原词汇不变。MLM 的任务就是去预测这些被 mask 的词,这个任务让模型学习了单词之间的建模 。
2)NSP (Next Sentence Prediction ) :它将训练语料分为两类,一是将 50% 语料构建成正常语序的句子对,比如对于 A-B 句子对,B 就是 A 的实际下一个句子,那么标记为 isnext;二是将 50% 语料构建成非正常语序句子对,B 是来自语料库的随机句子,标记为 notnext。然后模型预测 B 到底是不是 A 句子的下一个句子,使模型具有句子级别的识别能力 。
通过这两个预训练任务,模型可以学习到语言领域上的一些通用知识,因此可以促进 NLP 领域下游任务的训练。
![]()
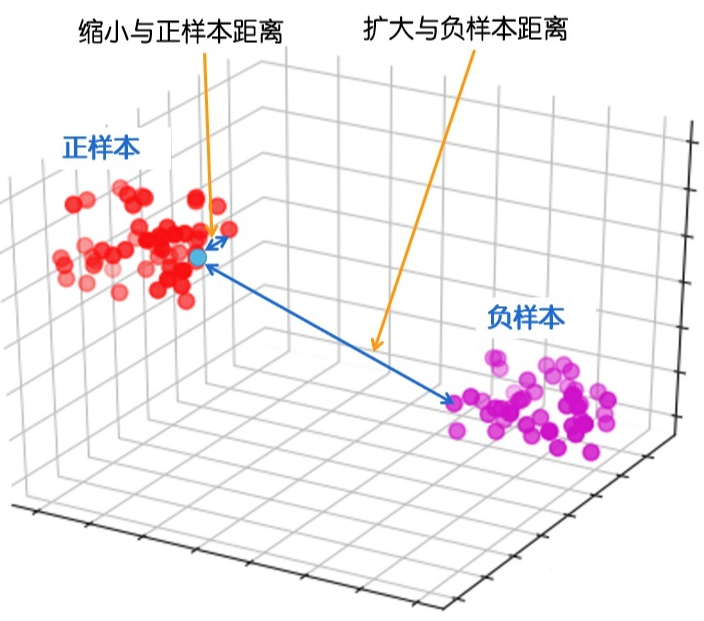
CV 领域中,和“微调+预训练”模式比较接近的方法,应该就是对比学习。对比学习同样用的是没有标注的数据,也就是说数据集里只有图片而没有标签。对比学习的目标是学习一个编码器,此编码器对同类数据进行相似的编码,并使不同类的数据的编码结果尽可能的不同 。也就是说对比学习本质上其实就是用了聚类的思想:缩小与正样本间的距离,扩大与负样本间的距离 。如下面的公式所示:
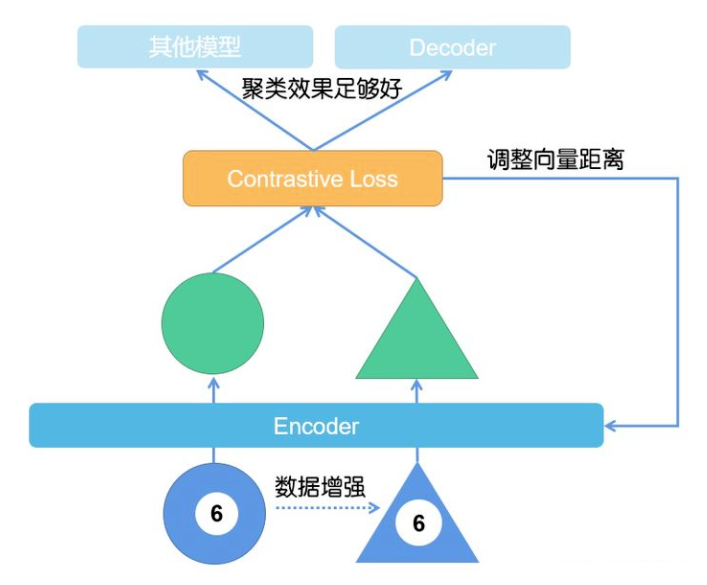
现在就能把问题转换成了,如何构建正负样本的问题。如上图所示,大多数都是通过数据增强的方法来创建正负样本的,即,同一张图片进行不同数据增强方法得到样本就是正样本,不同图片数据增强得到的样本就是负样本,然后根据上面聚类的思想来进行训练。因此,大部分对比学习的 pipeline 都如下图所示:
在多模态领域中,由于高质量的多模态标注数据较少,所以这几年也出现了基于 Transformer 结构的多模态预训练模型,通过海量无标注数据进行预训练,然后使用少量的标注数据进行微调即可。
多模态预训练模型能够通过在大规模数据上的预训练学到不同模态之间的语义对应关系,比如对齐文本形式的“狗”和图片中的“狗”的语义信息。
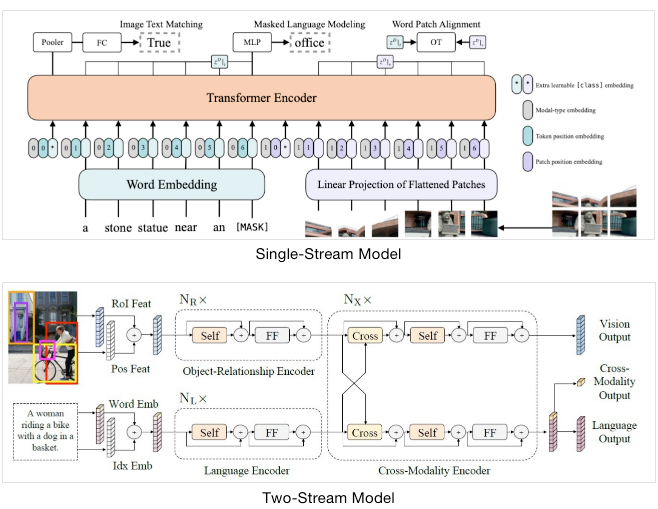
目前的多模态预训练模型按照网络的结构分类,大致可以分为两类,第一类为单流(single-stream)模型 ,第二类为双流(two-stream)模型 。如上图所示,单流模型中,视觉特征和文本特征一开始就 concat 在一起,然后直接输入到 Encoder 中;双流模型就是将视觉特征和文本特征首先在两个独立的 Encoder 中进行编码,然后再输入到 cross attention 进行多模态特征的融合。
预训练任务
多模态预训练的任务还是比较多的,也有不少文章会针对特定的 motivation 来提出精心设计的预训练任务。这里介绍几个比较常见的多模态预训练任务。
在 Masked Language Modeling(MLM)预训练任务中,需要在 sentence tokens 中随机 MASK 掉一些 token,然后模型基于其他的本文 token 和所有的图像 token 来预测这些被 mask 掉的 token。
在 Masked Region Classification(MRC)预训练任务中,需要在 region token 中随机 mask 掉一些 token,然后根据其他的图片 token 和所有的文本 token 来预测这些被 mask 的 token。具体来说就是,每个 region 都会有 Faster R-CNN 得到一个 label,模型需要预测 mask token 的类别,使之和 Faster R-CNN 的 label 相同。
在 Masked Region Classification-KL Divergence(MRC-KL)预训练任务中,同样是随机 mask region token,但是不同的这里不是做分类任务,而是需要计算 Faster R-CNN 特征和 Mask region 的分布差异,使得 Mask region 的分布和 Faster R-CNN 特征的分布尽可能相似,所以损失函数用的是 KL 散度。
Image-TextMatching(ITM)中,需要对输入的 Image-Text Pair 随机替换 Image 或者 Text,最后预测输入的 Image 和 Text 是否有对应关系,所以这是一个二分类的问题。
多模态下游任务
3.1 Visual Question Answering
![]()
VQA 就是对于一个图片回答图片内容相关的问题。将图片和问题输入到模型中,输出是答案的分布,取概率最大的答案为预测答案。
在 Visual Entailment 中,Image 是前提,Text 是假设,模型的目标是预测 Text 是不是“Entailment Image”,一共有三中 label,分别是 Entailment、Neutral 和 Contradiction。
![]()
在 pipeline 中,我们将 Image 和 Text 输入到模型中,输出是三个 label 中的一个作为预测分类。
3.3 Natural Language for Visual Reasoning
![]()
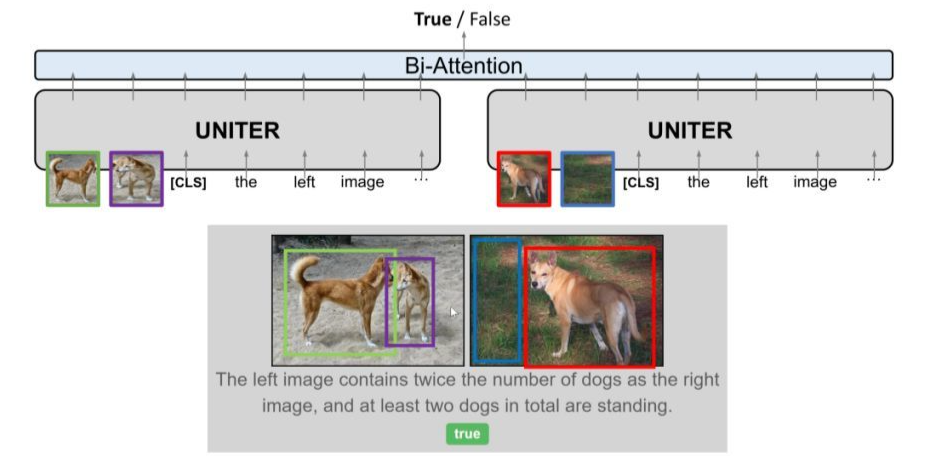
NLVR(Natural Language for Visual Reasoning)任务中,需要同时输入两张 Image 和一个描述,输出是描述与 Image 的对应关系是否一致,label 只有两种(true/false)。
在 pipeline 中,我们将 Images 和 Text 输入到模型中,输出是两个 label 中的一个作为预测分类。
3.4 Visual Commonsense Reasoning
![]()
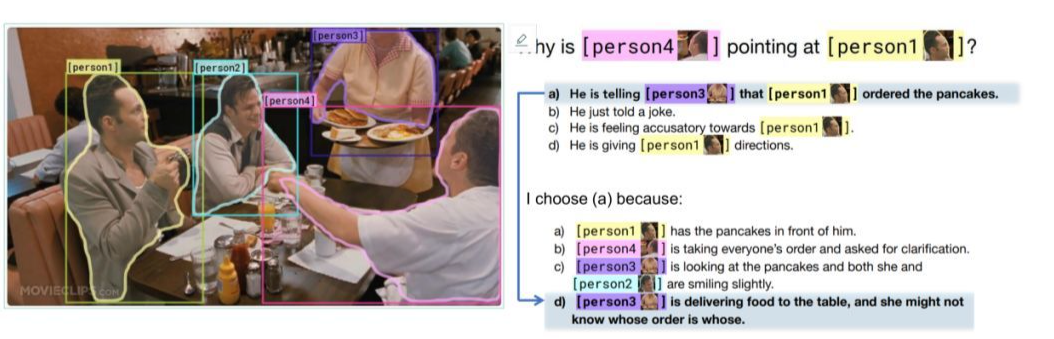
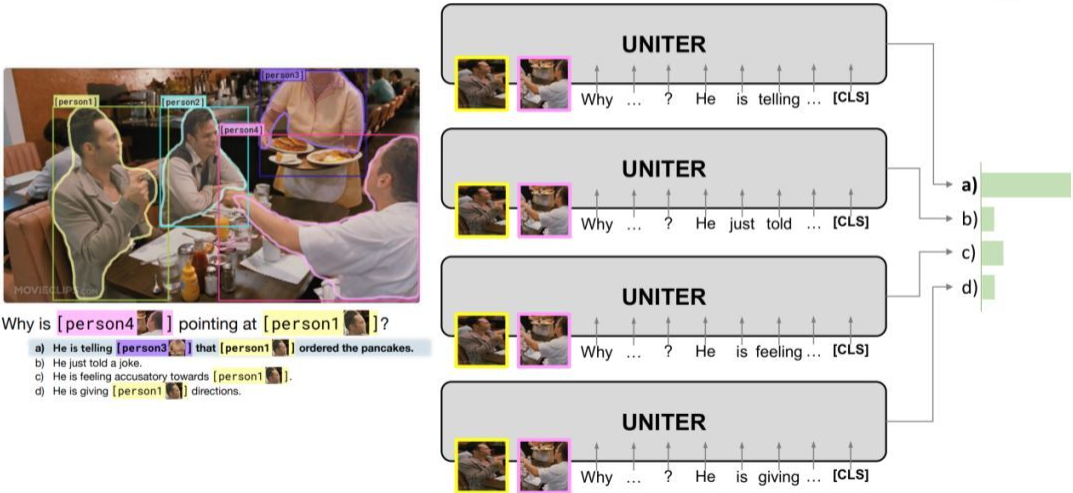
Visual Commonsense Reasoning 中,任务是以选择题形式存在的,对于一个问题有四个备选答案,模型必须从四个答案中选择出一个答案,然后再从四个备选理由中选出选择这个答案的理由。
在训练的过程中,我们将问题和四个备选答案连接到一起再分别与图片输入到模型中,输出为四个得分,得分最高的为预测答案。选择理由是过程也是类似。
3.5 Referring Expression Comprehension
![]()
Referring Expression Comprehension 任务中,输入是一个句子,模型要在图片中圈出对应的 region。
![]()
对于这个任务,我们可以对每一个 region 都输出一个 score,score 最高的 region 作为预测 region。
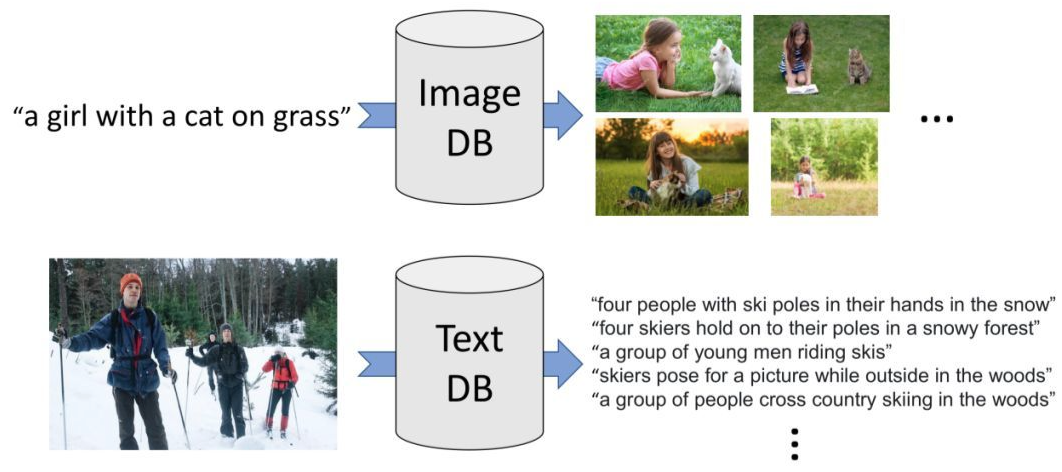
在 Image-Text Retrieval 任务中,就是给定一个模态的指定样本,在另一个模态的 DataBase 中找到对应的样本。
![]()
这个任务 Image-Text Matching 任务非常相似,所以在 fine-tune 的过程中就是选择 positive pair 和 negative pair 的方式来训练模型。
![]()
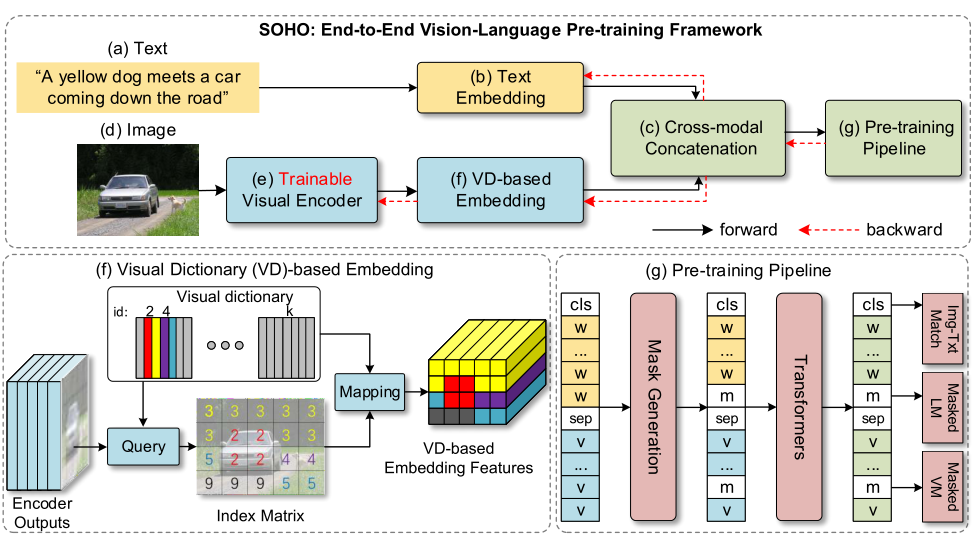
4.1 SOHO—CVPR 2021 Oral
![]()
论文标题:
Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning
收录会议:
CVPR 2021 Oral
论文链接:
https://arxiv.org/pdf/2104.03135.pdf
代码链接:
https://github.com/researchmm/soho
4.1.2 Motivation
![]()
使用 Faster R-CNN 提取的 region 特征会存在一些缺点:
2)提取的视觉特定会被局限在目标检测器预定义的类别中;
3)目标检测器依赖大规模标注数据,并且存在质量低、噪声大等问题。
因此,作者基于 grid 特征提出了一个预训练的模型 SOHO。
![]()
SOHO 是一个双流的预训练模型,预训练包括 ITM、MLM、MVM。这篇文章的重点是提出了一个视觉字典的概念,因为图片的像素特征非常多样,增加了模型学习的难度。因此作者提出了视觉字典 ,将每个 grid 的特征和视觉字典中的特征进行对应,相当于把每个 grid 的低级语义映射到了视觉字典中的高级语义,从而降低了优化的难度。在训练过程中,同时优化视觉字典和模型参数。
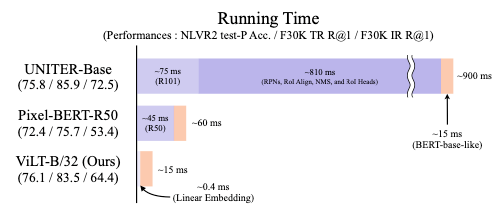
4.2 ViLT—ICML 2021
4.2.1 论文地址
![]()
论文标题:
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
收录会议:
ICML 2021
论文链接:
https://arxiv.org/abs/2102.03334
代码链接:
https://github.com/dandelin/vilt
4.2.2 Motivation
作者发现基于 Region 特征的预训练模型,98% 以上的时间都花在了提取视觉特征上;基于用 ResNet 提取的 grid 特征,75% 的时间都花在了提取视觉特征上。因此,作者希望用一种非常简单的方式来进行视觉特征的提取,从而来减少这个 overhead。
所以作者采用了 ViT 的 patch embedding 的方式来提取视觉特征,并且模型用 ViT 预训练好的参数进行初始化。此外,由于是直接对原图进行 embedding 的,所以作者在训练的时候也用到数据增强的方法来提高性能。
![]()
论文标题:
VinVL: Revisiting Visual Representations in Vision-Language Models
收录会议:
CVPR 2021
论文链接:
https://arxiv.org/abs/2101.00529
代码链接:
https://github.com/pzzhang/VinVL
4.3.2 Motivation
![]()
与 ViLT 不同,这篇文章认为目前预训练模型的瓶颈在于,目标检测器提取的特征不够好。如上图所示,左边是 BUTD 的检测结果,右图是本文提出的检测器的检测结果。作者通过在更大数据集上训练更好的目标检测器,并用该检测器提取特征,来提升了预训练模型的性能。
![]()
原来的 BUTD 的目标检测器就是在 VG 数据集上训练,为了能够获得语义更加丰富的特征。作者将现有的四个目标数据集进行了合并,获得了一个信息量、数据量更大的目标检测数据集,并在这个数据集上训练目标检测器。然后基于这个模型提取的视觉特征来进行多模态预训练,从而提升了模型的性能。
![]()
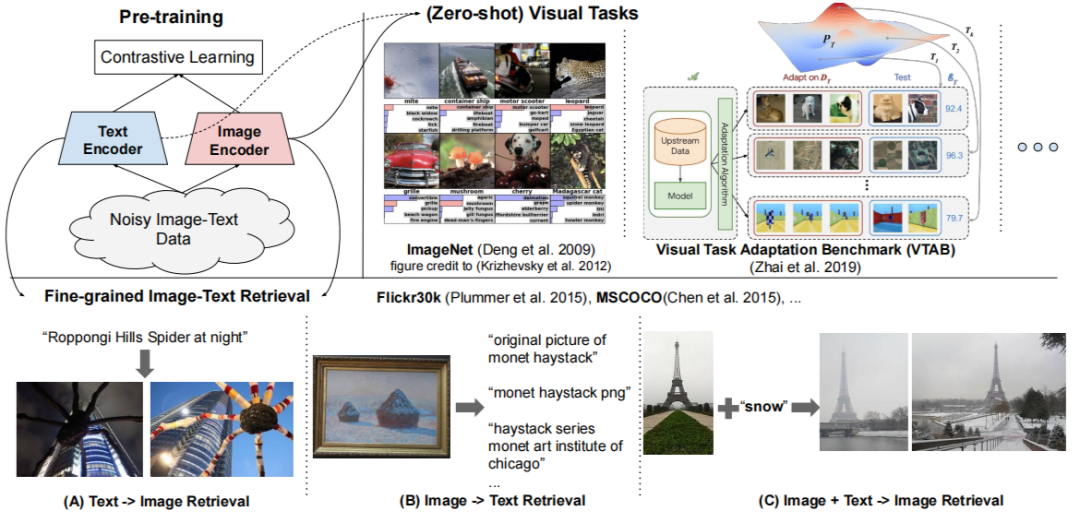
论文标题:
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
收录会议:
ICML 2021
论文链接:
https://arxiv.org/abs/2102.05918
4.4.2 Motivation
![]()
目前多模态预训练模型的数据集大多是图片-文本对,但是这些本文数据对通常是需要人工标注或者在网上爬取之后进行人工的筛选,这使得目前这类数据集中数据量的大小也就在 1000 万左右。因此,在这篇文章中,作者在网上爬取了大量图片,然后通过简单的机器筛选,剩下 10 亿个有噪声的图文对来进行训练,从而提升模型的性能。
作者采用了双编码器的结果对图片和文本分别进行编码,然后基于对比学习的损失函数来学习图文对是否匹配,从而在图文匹配任务上达到了 SOTA 的性能。
![]()
论文标题:
E2E-VLP: End-to-End Vision-Language Pre-training Enhanced by Visual Learning
收录会议:
ACL 2021
论文链接:
https://arxiv.org/abs/2106.01804
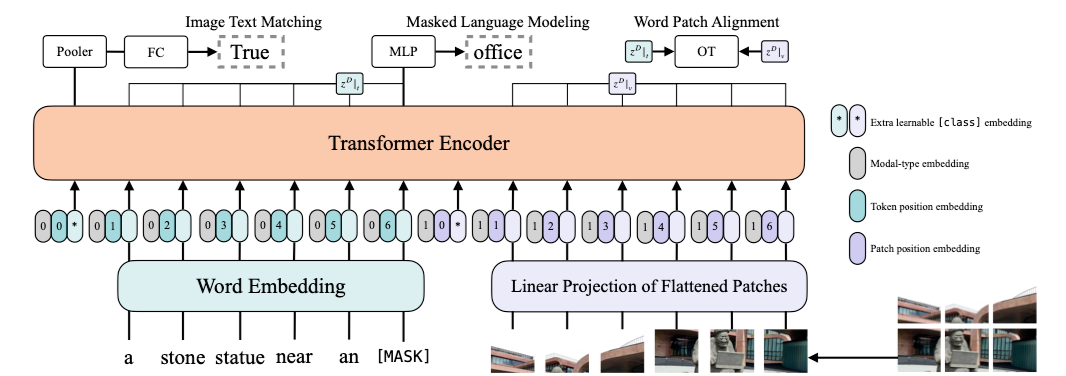
4.5.2 Motivation
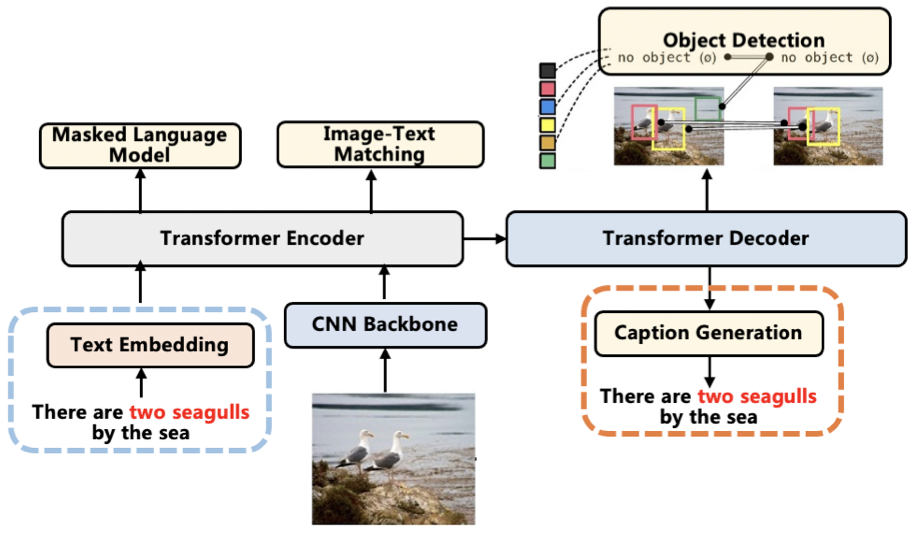
目标检测器得到 region 特征会存在一定的局限性,比如目标检测的知识受限、目标检测阶段非常耗时。因此,在本文中作者采用了一个端到端的模型“Backbone+Transformer”来进行预训练,从而避免这些缺点。但是有一个问题是,backbone 提取的 grid 特征无法获得对象级别的信息,因此作者在本文中提出了两个额外的预训练任务来解决这一个问题。
![]()
如上图所示,除了经典的 MLM 和 ITM 预训练任务之后,作者还在 Encoder 后面采用了一个 Decoder 来执行两个额外的预训练任务——object detection 和 image captioning。
对于目标检测,作者采用了 DETR 的方式,最小化 Decoder 生成结果和 Faster R-CNN 的生成结果之间的损失,这个预训练任务可以使模型进行对象级别信息的感知;对于 Image Captioning,也就是最小化生成句子和 ground truth 之间的损失,这个预训练任务可以促进模型对视觉信息和文本信息的对齐。
![]()
论文标题:
KD-VLP: Improving End-to-End Vision-and-Language Pretraining with Object Knowledge Distillation
论文链接:
https://arxiv.org/abs/2109.10504
4.6.2 Motivation
这篇文章的 Motivation 和 E2E-VLP 一样,也是为了解决端到端模型中的视觉 grid 特征,没法捕获对象级信息的问题。这篇文章的方法采用了知识蒸馏的思想,将目标检测的信息融合到预训练任务之中。
4.6.3 方法
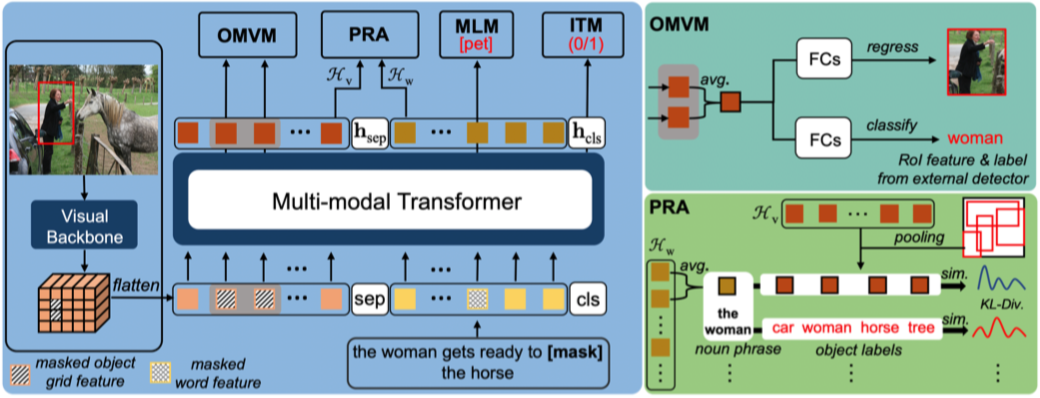
如上图所示,除了常用 MLM 和 ITM 预训练任务之后,作者还加了两个额外的预训练任务 OMVM 和 PRA 任务。
OMVM 任务就是每次采样一个对象,然后根据目标检测的区域信息,取出 Transformer 的特征中对应区域的特征并进行 avgpool,然后 OMVM 任务需要执行两个子任务:一个是通过回归,重建被 mask 之前的特征;另一个是分类,预测 mask 区域中目标的类别。这个任务能够帮助模型学习对象级别的信息。
PRA 的任务就是最小化“区域-标签”和“文本短语-标签”的 KL 散度。这个任务能够帮助模型学习对象级别跨模态的对齐。
![]()
论文标题:
MURAL: Multimodal, Multitask Retrieval Across Languages
收录会议:
EMNLP 2021
论文链接:
https://arxiv.org/abs/2109.05125
4.7.2 Motivation
目前的多模态任务大多都是基于英语的,本文希望在同时执行多模态和多语言的任务,因此作者将多模态和多语言任务同时放到了同一个模型中。此外,多模态多语言数据集里的语言数量往往非常有限,因此,作者还加了基于维基百科的多语言数据集来提升模型进行多语言多模态任务的能力。
4.7.3 方法
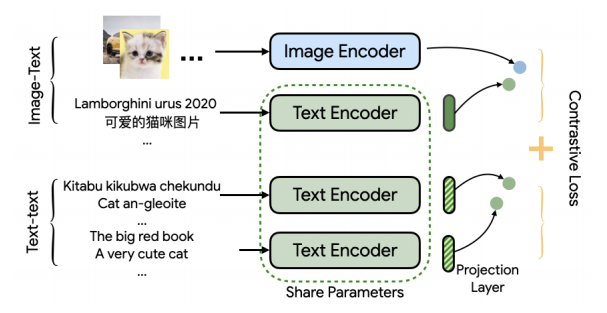
![]()
如上图所示,作者进行了两个对比学习的任务,即图文对的匹配和多语言对的匹配,同时不同语言的文本编码进行了参数共享,使得模型能够适应多语言的任务。作者在预训练过程中同时训练这两个任务,使得模型能够适应多模态、多语言的场景。
总结
本文简要介绍了 CV、NLP、多模态预训练的一些基础知识,以及 2021 年一些最新的多模态预训练工作的核心思想。多模态预训练模型能够通过预训练任务,在大规模容易获得多模态数据中学习一些共性知识,然后在下游任务中基于特定数据集、特定任务进行微调,学习特性知识,从而达到比直接学习下游任务更好的效果。
目前,多模态预训练模型的进步和研究主要来自三个方面:
1. 基于更好的预训练任务进行预训练 。因为预训练阶段学习的是一些模型的共性知识,所以预训练任务最好是基于更少的任务假设,来挖掘多模态数据共有的一些联系;
2. 基于更大规模的数据集进行预训练 。预训练的数据量越大,模型就能够学习更多样本之间的联系,学习更加通用的共性知识,从而提高模型的泛化能力。
3. 基于参数量更大的模型进行预训练 。随着预训练数据量的增加,一个简单的模型往往不能学习到大量数据集的知识,因此,一个参数量更多、建模能力更强的模型对于学习大规模数据的共性知识也是必要的。
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
https://zhuanlan.zhihu.com/p/159620066
https://zhuanlan.zhihu.com/p/76912493
Pre-trained Models for Natural Language Processing: A Survey
https://zhuanlan.zhihu.com/p/149904753
https://www.jianshu.com/p/801b472882b2
https://zhuanlan.zhihu.com/p/346686467
https://zhuanlan.zhihu.com/p/410442591
https://zhuanlan.zhihu.com/p/412126626
https://zhuanlan.zhihu.com/p/402997033
https://zhuanlan.zhihu.com/p/114069179
https://mp.weixin.qq.com/s/ondgiFryYqB6-sf-v4pLXQ
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()