对比学习在NLP和多模态领域的应用
© 作者|杨锦霞
研究方向 | 多模态
对比学习可以应用于监督和无监督的场景下,目前在CV、NLP等领域中取得了较好的性能。本文对对比学习进行基础介绍,以及其在NLP和多模态中的应用
引言
对比学习的主要思想是相似的样本的表示相近,而不相似的远离。对比学习可以应用于监督和无监督的场景下,并且目前在CV、NLP等领域中取得了较好的性能。本文先对对比学习进行基础介绍,之后会介绍对比学习在NLP和多模态中的应用,欢迎大家批评和交流。
对比学习基础介绍
损失函数
1. NCE[1](Noise-contrastive estimation):是估计统计模型的参数的一种方法,主要通过学习数据分布和噪声分布之间的区别。下面给出NCE的原始形式,它包含一个正负样本对。在之后的许多研究工作中,包含多个正样本或负样本也被广义的称为NCE。下式中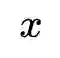
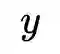
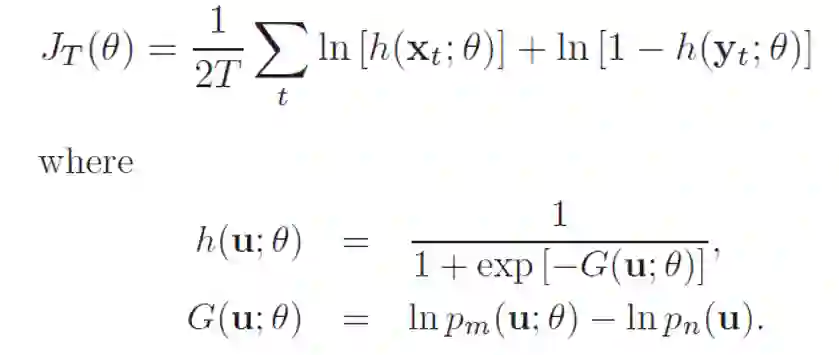
2. InfoNCE[2]:在CPC中提出,使用分类交叉熵损失在一组负样本中识别正样本。原论文给出的式子如下:
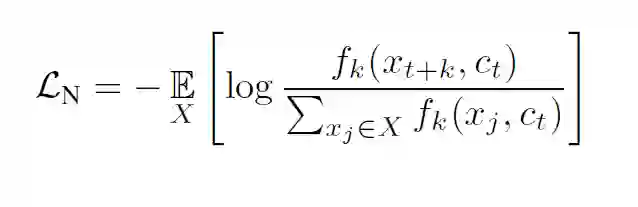
3. Triplet Loss:三元组损失,最初是由谷歌在FaceNet[3]中提出,主要用于识别在不同角度和姿势下的人脸。下式中加号在右下角表示max(x,0)。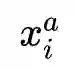
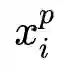
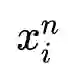
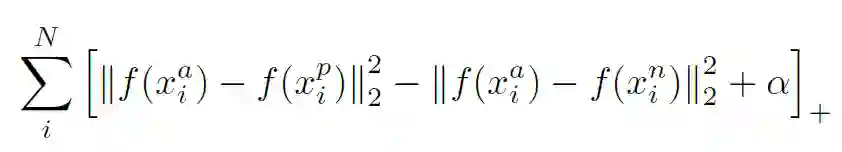
4. N-pair Loss[4]:Multi-Class N-pair loss,是将Triplet Loss泛化到与多个负样本进行对比。
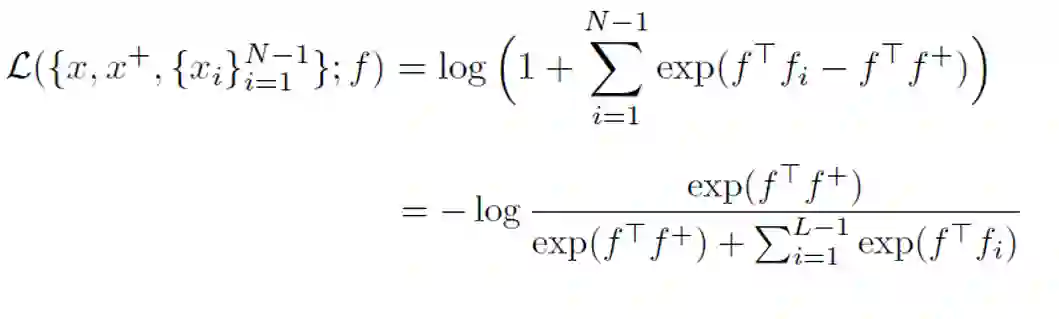
衡量标准
衡量指标由(Wang & Isola, 2020)[5]提出,文中说明了对比学习算法具有两个关键属性alignment和uniformity,很多有效的对比学习算法正是较好地满足了这两种性质。
alignment:衡量正例样本间的近似程度
uniformity:衡量特征向量在超球体上的分布的均匀性
文章同时给出了衡量两种性质的评价指标,并同时指出优化这两个指标会在下游任务上表现更好。
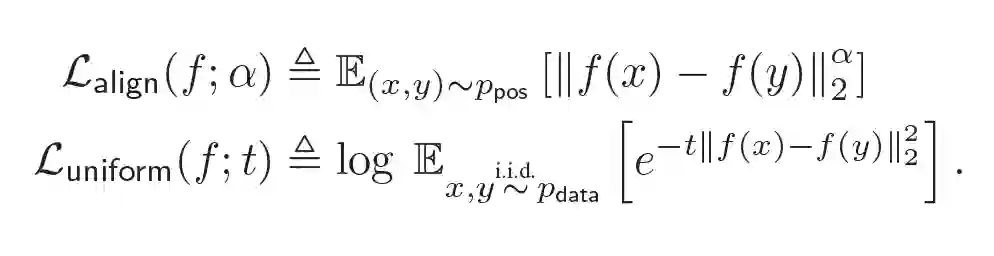
关键技术
1. 正负样本的构造
数据增强:给定训练数据,需要进行数据增强来得到更多正样本。正确有效的数据增强技术对于学习好的表征至关重要。比如SimCLR[6]的实验表明,图片的随机裁剪和颜色失真是最有效的两种方式。而对于句子来说,删除或替换可能会导致语义的改变。
负样本构造:一般对比学习中使用in-batch negatives,将一个batch内的不相关数据看作负样本。
多个模态:正样本对可以是两种模态的数据,比如图片和图片对应描述。
2. 大的batch size
在训练期间使用大的batch size是许多对比学习方法成功的一个关键因素。当batch size足够大时,能够提供大量的负样本,使得模型学习更好表征来区别不同样本。
对比学习在NLP领域的应用
A Simple but Tough-to-Beat Data Augmentation Approach for Natural Language Understanding and Generation
受多视图学习的启发,这篇文章主要提出了一种Cutoff的数据增强方法,包含以下三种策略:
Token cutoff:删除选中的token信息。为了防止信息泄露,三种类型的编码都被改为0。
Feature cutoff:删除特征,将整列置为0。。
Span cutoff:删除连续的文本块。
作者将Cutoff应用到自然语言理解和机器翻译任务上去,实验结果表明这种简单的数据增强方式得到了与基线相当或更好的结果。目前,Cutoff也作为一种常用的数据增强方法应用到不同的对比学习模型中去。
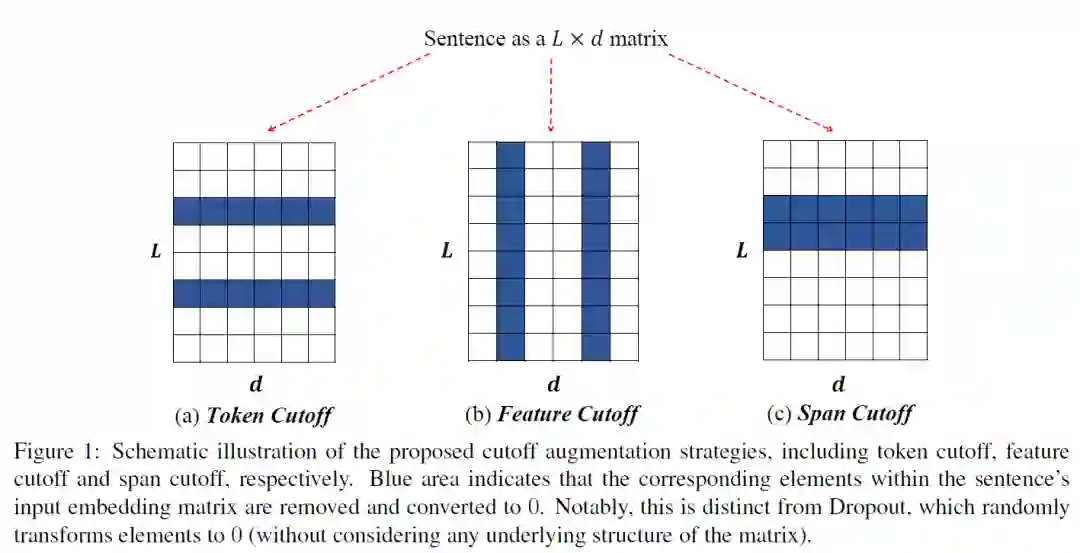
CERT:Contrastive Self-supervised Learning for Language Understanding
CERT主要流程图如下。可以看出,在预训练Bert的基础上,CERT增加了CSSL预训练任务来得到更好的表征。
本文首先通过back-translation方式进行数据增强,使用不同语言的翻译模型来创建不同的正样本。
CSSL Pretraining:使用类似MoCo[7]的对比学习框架,采用一个队列去存储数据增强后的keys,并且使用一种动量更新的方法对该队列进行更新。给定句子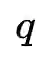
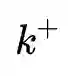
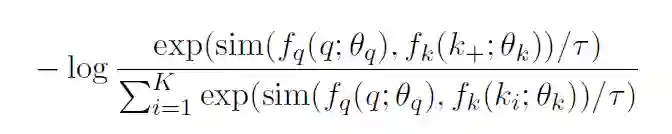
作者测试了CERT在GLUE 数据集的上的性能。在11个任务中,CERT在7个任务上优于BERT,2个任务上效果相当,整体性能优于BERT。这进一步证明了对比自监督学习是一个学习更好的语言表征的方法。
SimCSE: Simple Contrastive Learning of Sentence Embeddings(EMNLP2021)
SimCSE有两个变体:Unsupervised SimCSE和Supervised SimCSE,主要不同在于对比学习的正负例的构造。
Unsupervised SimCSE:
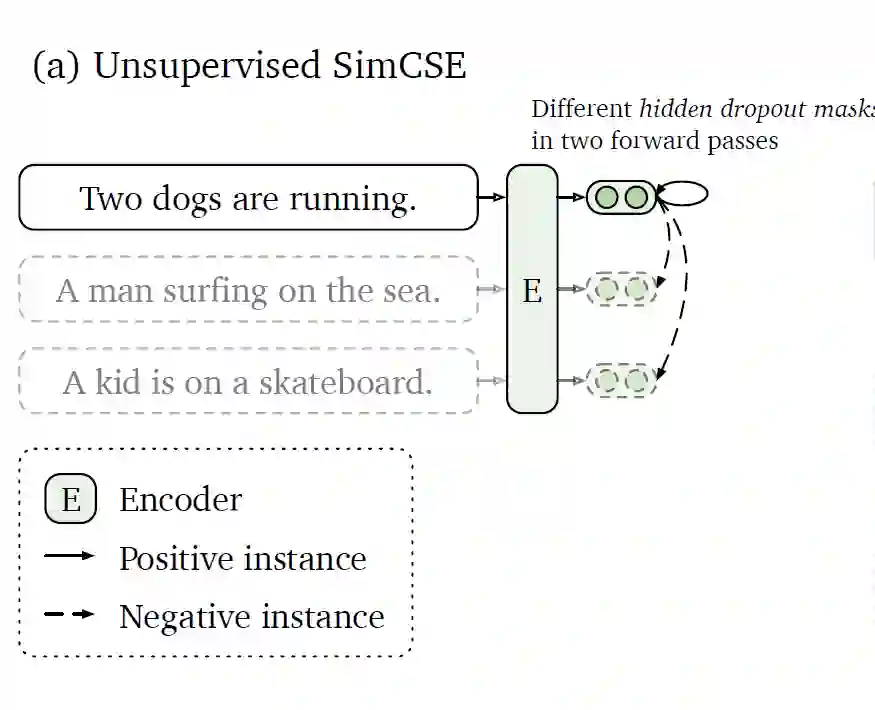
正样本:一个句子通过编码器进行两次编码,两次使用不同的dropout 掩码,得到的两个向量
,
为正样本对
负样本:使用in-batch negatives
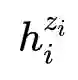
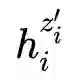
故训练目标函数为:
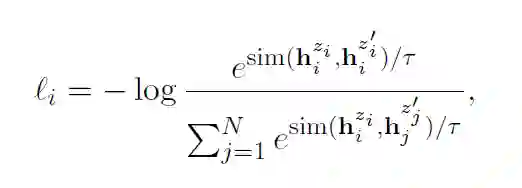
Supervised SimCSE:
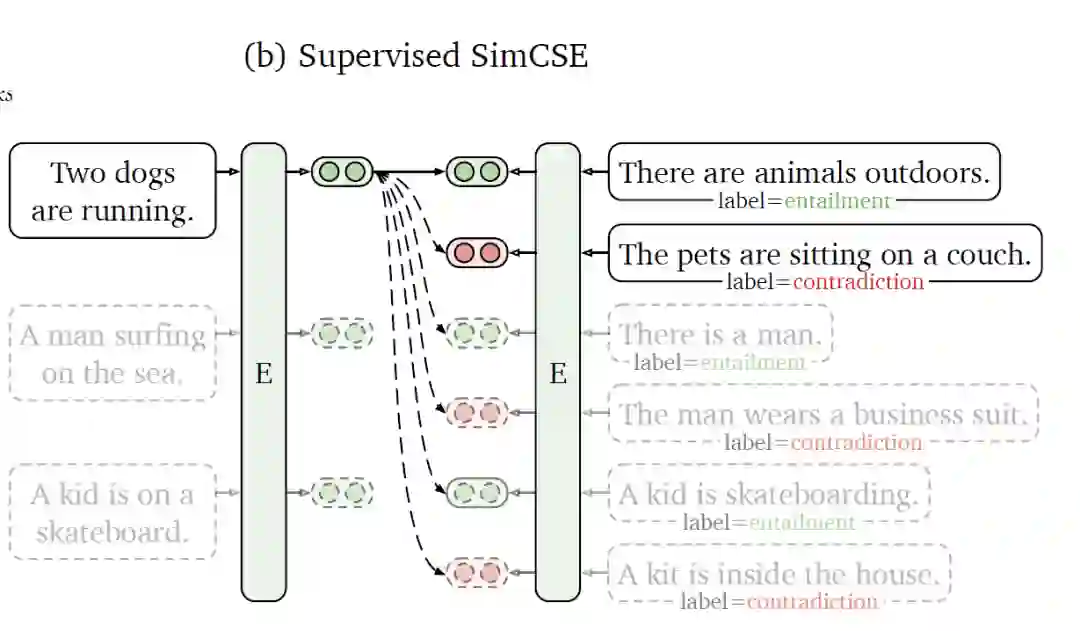
使用NLI(Natural Language Inference)数据集,利用其标注的句子之间的关系来构造对比学习的正负样本。如上图所示,给定一个前提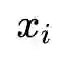
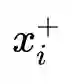
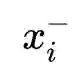
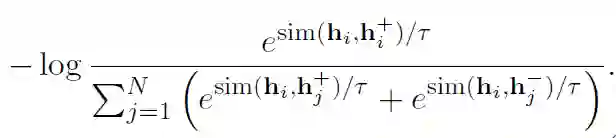
本文作者在多个数据集上评估了SimCSE的性能,发现在STS(语义文本相似性)系列任务上,SimCSE在无监督和有监督的条件下均大幅超越了之前的SOTA模型。
上面提到了衡量对比学习质量的指标:alignment和uniformity,作者将其进行了可视化,可以发现所有模型的uniformity都有所改进,表明预训练BERT的语义向量分布的奇异性被逐步减弱。
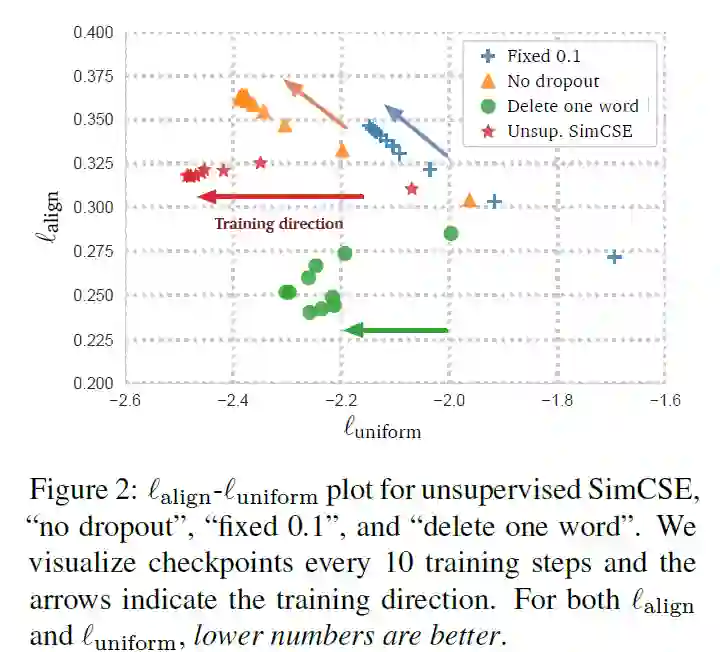
ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
ESimCSE是对上述SimCSE构建正负样本方法的改进,主要出发点如下:
句子的长度信息通常会被编码,因此无监督的SimCSE中的每个正对长度是相同的。故用这些正对训练的无监督SimCSE 往往会认为长度相同或相似的句子在语义上更相似。
Momentum Contrast(动量对比)最早是在MoCo提出,是一种能够有效的扩展负例对并同时缓解内存限制的一种方法。ESimCSE借鉴了这一思想来扩展负例。
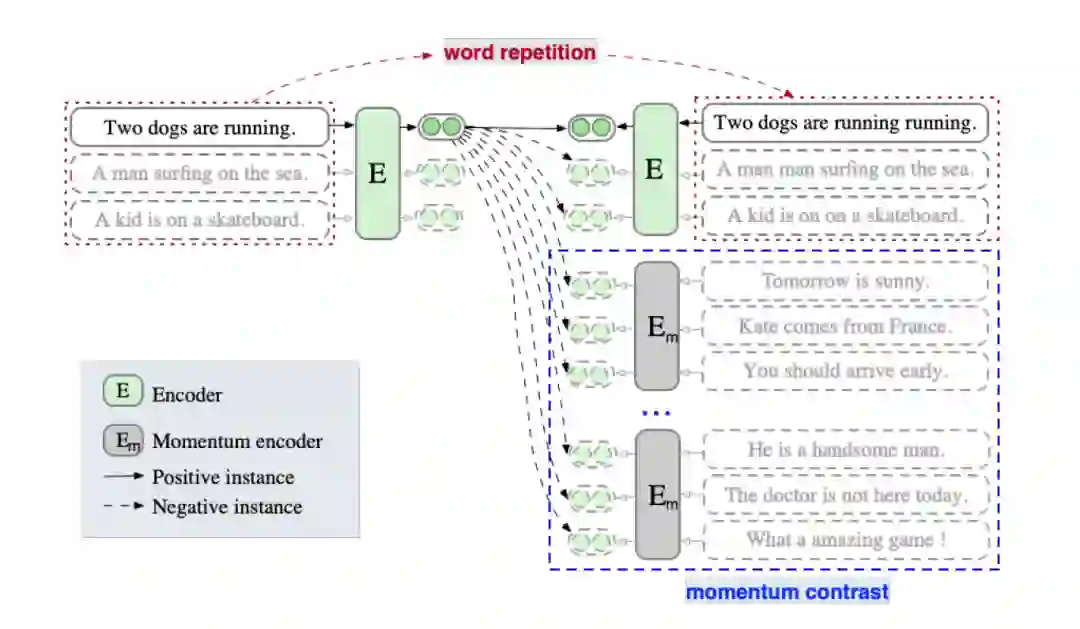
正例:作者先探究了句子对的长度差对SimCSE的影响,当长度差大于3时无监督SimCSE模型的效果大幅度降低。为了降低句子长度差异的影响,作者尝试了随机插入、随机删除和词重复三种方法构建正例,发现前两者导致语义相似度下降明显,而词重复可以保持较高的相似度,同时缓解了句子长度带来的问题。故使用word repetition进行正例构造。
负例:① in-batch negatives ② 动量更新队列中的样本
故损失函数如下:
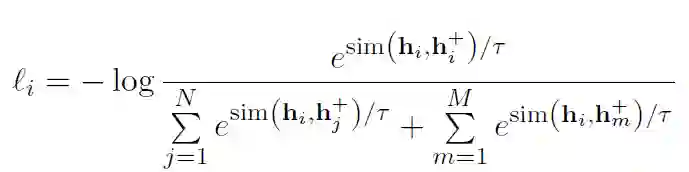
实验表明,ESimCSE整体效果优于无监督的SimCSE,在语义文本相似性(STS)任务上效果优于BERTbase版的SimCSE 2%。
对比学习在多模态中的应用
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision (ICML 2021)
本文提出ALIGN模型,作者利用了超过10亿的图像文本对的噪声数据集,没有进行细致的数据清洗或处理。ALIGN使用一个简单的双编码器结构,基于对比学习损失来对齐图像和文本对的视觉和语言表示 。作者证明了,数据规模的巨大提升可以弥补数据内部存在的噪声,因此即使使用简单的对比学习方式,模型也能达到SOTA的特征表示。
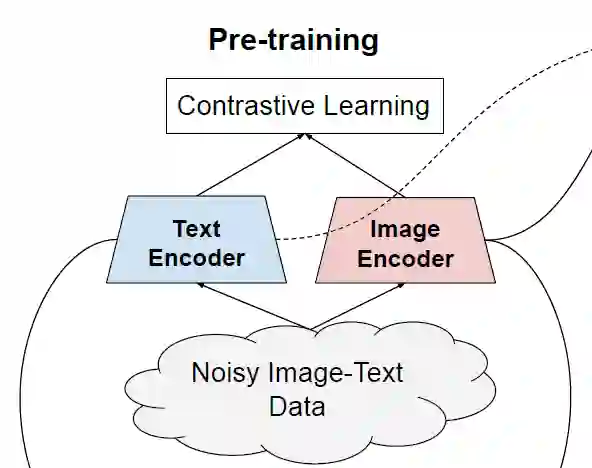
在预训练中,将匹配的图像-文本对视为正样本,并将当前训练batch中的其他随机图像-文本对视为负样本。损失函数如下:
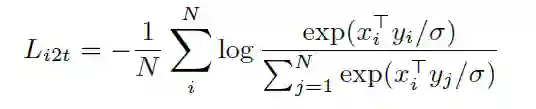
image-to-text loss
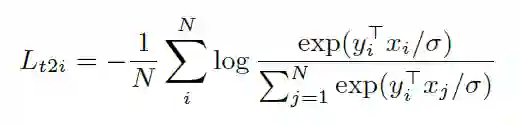
text-to-image loss
ALIGN模型得到的对齐的图像和文本表示在跨模态匹配/检索任务中实现了SOTA效果。同时ALIGN模型也适用于zero-shot图像分类、图像分类等任务。例如,ALIGN在ImageNet中达到了88.64%的Top-1准确率 。
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation (NeurIPS 2021)
作者提出了 ALign BEfore Fuse(ALBEF) ,首先用一个图像编码器和一个文本编码器独立地对图像和文本进行编码。然后利用多模态编码器,通过跨模态注意,将图像特征与文本特征进行融合。并提出动量蒸馏(Momentum Distillation)对抗数据中的噪声,得到更好的表征。
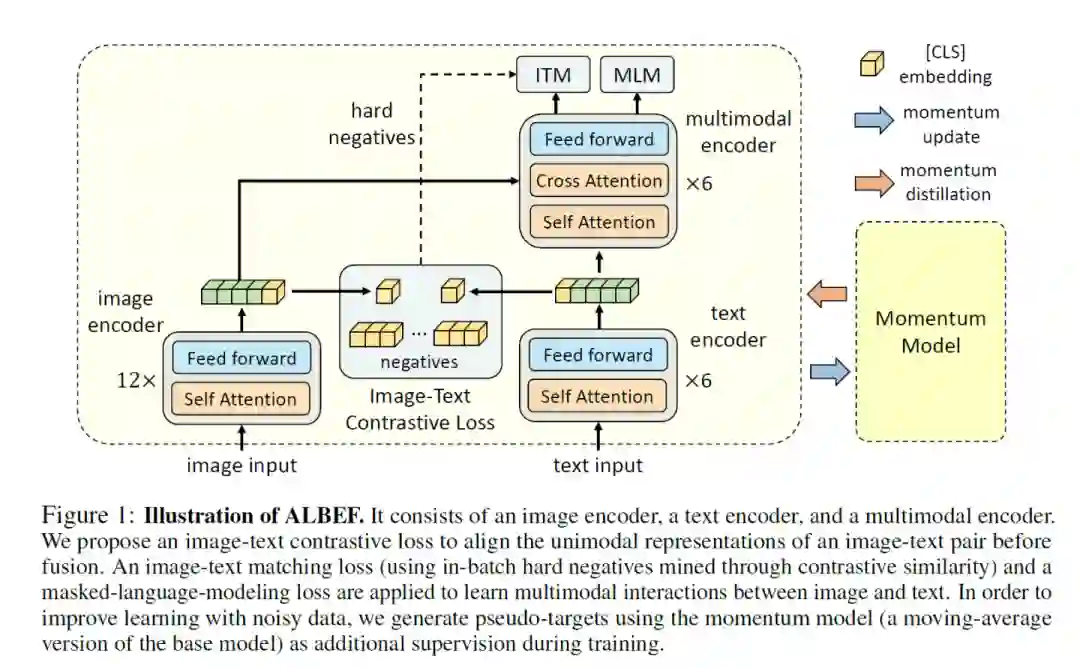
ALBEF预训练任务:图像-文本对比学习(ITC) 、掩蔽语言建模(MLM) 和图像-文本匹配(ITM) 。
ITC:Image-Text Contrastive Learning,目的是在融合前学习到更好的单模态表征。受MoCo的启发,作者维护了两个队列来存储最近的M个图像-文本表示,故对于每个图像和文本,作者计算图像到文本和文本到图像的相似度如下:
设
和
为ground truth(one-hot 编码),ITC定义为
和
之间的交叉熵:
MLM:Masked Language Modeling,利用给定图像和上下文文本来预测mask词
ITM:Image-Text Matching,把图像和文本是否匹配看作二分类问题
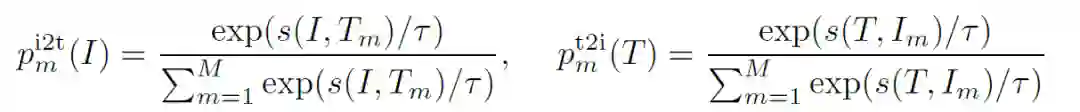
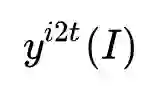 和
和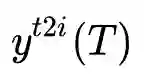
 和
和 之间的交叉熵:
之间的交叉熵: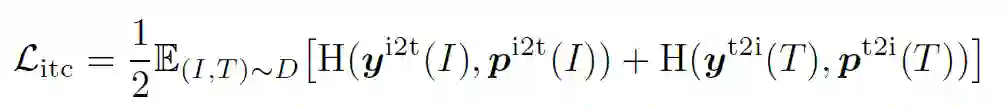
故整个预训练的损失函数为上述三者的和。
由于用于预训练的数据集往往含有噪声,作者提出同时从动量模型生产的伪标签中去学习。将上述相似度计算公式中的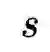
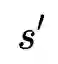
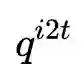
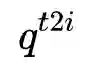
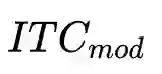
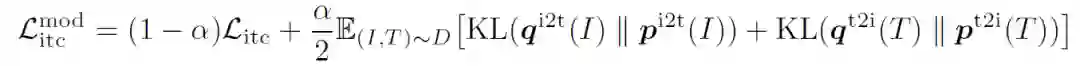
同时,作者从互信息最大化的角度来证明了ALBEF实际上最大化了图像-文本对的不同views之间的互信息的下界。
与现有的方法相比,ALBEF在多个下游视觉语言任务上达到了SOTA的效果。
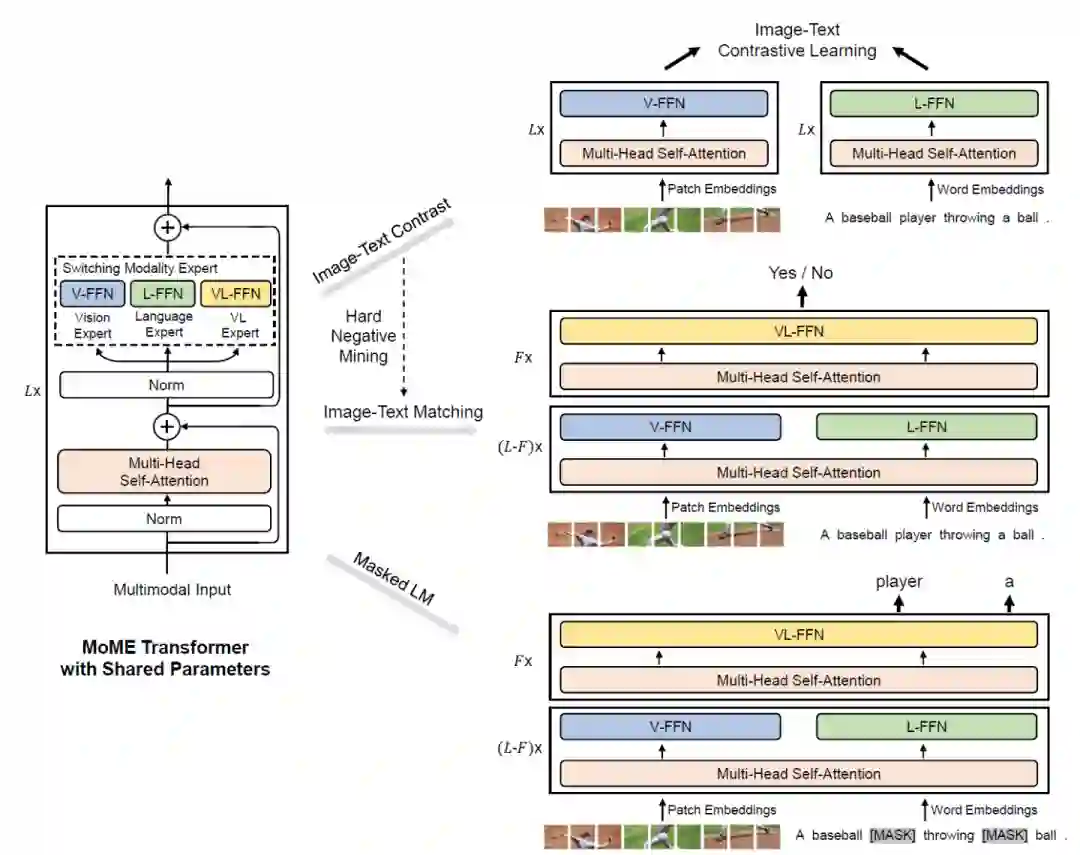
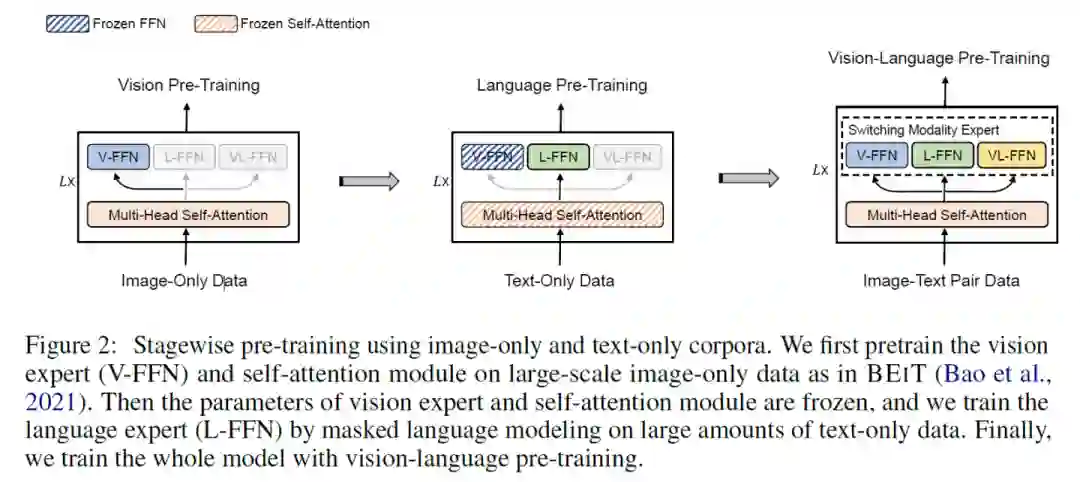
VLMO: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
本文提出VLMO模型,既可以作为融合编码器去做分类任务,也可以作为双编码器去做检索任务。VLMO引入一个 Mixture-of-Modality-Experts(MoME)的Transformer,能够根据输入数据的类型选择不同的expert,如下图所示。
VLMO的预训练任务与前面类似,通过图像-文本对比学习、掩码语言建模和图像-文本对匹配进行联合预训练。
其中,Image-Text Contrast预训练任务具体为:给定一个batch的图像文本对,图像文本对比学习的目标是从n*n个可能的图像文本对中预测匹配的对,事实上在这一batch中有N个正样本对,之后使用交叉熵损失进行训练。下式中,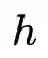
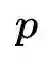
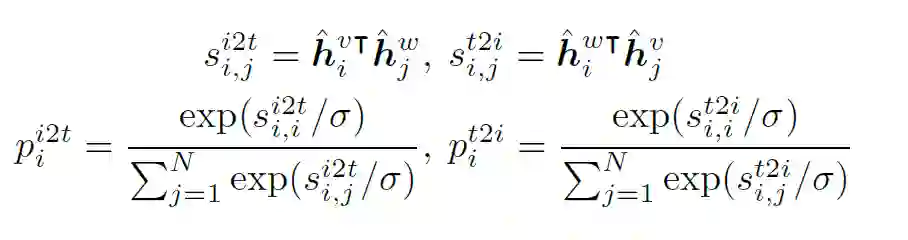
本文巧妙的地方在于采用了分阶段的预训练方式,得到了更泛化的表示。
VLMO模型在VQA等多模态下游任务上进行微调,效果达到了SOTA。
参考文献
[1] Gutmann M, Hyvärinen A. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models[C]//Proceedings of the thirteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2010: 297-304.
[2] Van den Oord A, Li Y, Vinyals O. Representation learning with contrastive predictive coding[J]. arXiv e-prints, 2018: arXiv: 1807.03748.
[3] Schroff F, Kalenichenko D, Philbin J. Facenet: A unified embedding for face recognition and clustering[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 815-823.
[4] Sohn K. Improved deep metric learning with multi-class n-pair loss objective[J]. Advances in neural information processing systems, 2016, 29.
[5] Wang T, Isola P. Understanding contrastive representation learning through alignment and uniformity on the hypersphere[C]//International Conference on Machine Learning. PMLR, 2020: 9929-9939.
[6] Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representations[C]//International conference on machine learning. PMLR, 2020: 1597-1607.
[7] He K, Fan H, Wu Y, et al. Momentum contrast for unsupervised visual representation learning[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 9729-9738.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“对比学习” 就可以获取《对比学习专知资料大全》专知下载链接






