终于有个能看懂的CS231n经典CNN课程了:AlexNet/VGG/GoogLeNet(上)

大家好,我是禅师的助理兼人工智能排版住手助手条子。
今天由条子给大家推送。其实条子对人工智能不是很了解,但是禅师说:你去看看斯坦福的 CS231n 教程就了解了。

快拉倒吧。我要是能看懂还给你当助手?
不过好在还是有明白人,对 CS231n 的 CNN 课程进行了翻译,并加入了译者对课程的理解和解读。
条子表示看过以后,确实对 CNN 有了一点点新的认识,不再像以前那样只能分清美国媒体 CNN 和神经网络 CNN …

本文由译智社的小伙伴翻译。这是一群来自全国多所顶级高校、很有理想的年轻人,因为热爱人工智能,组成了一个社团(字面意义的社团),努力推进人工智能的普及。
全文大约3500字。看完大概需要好几首这首歌的时间👇

文章 | gdymind
编辑 | strongnine
本文翻译总结自 CS231n Lecture 9:
https://youtu.be/DAOcjicFr1Y
本篇将深入介绍当前的应用和研究工作中最火的几个 CNN 网络架构 —— AlexNet、VGGNet、GoogLeNet 和 ResNet,它们都在 ImageNet 分类任务中有很好的表现。另外,本篇也会粗略介绍一些其他的架构。
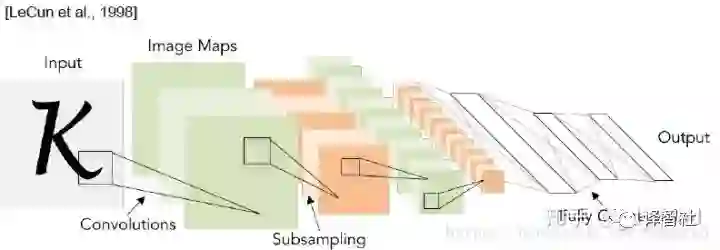
LeNet-5 回顾
我们先来回顾一下最基本的 LeNet,它可以说是首个效果比较好的 CNN。它使用了 5 x 5 的卷积核,stride 为 1。池化层卷积核是 2 x 2 的,stride 为 2。最后还有几个全连接层。网络结构很简单也很容易理解。
AlexNet
接下来讲的是 AlexNet,它是第一个在 ImageNet 分类上表现不错的大规模的 CNN,在 2012 年一举碾压其他方法获得冠军,于是开启了一个新的时代。
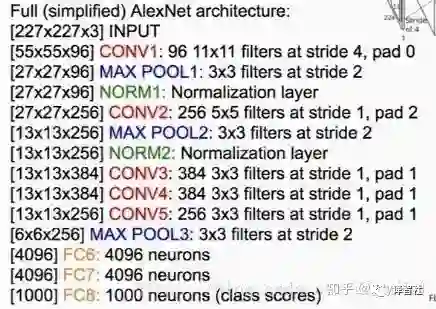
它的基本架构组成如下图,它是由若干卷积层、池化层、归一化层和全连接层组成的。左边方括号里的内容为数据的形状,右边有卷积核的详细参数。总体来说 AlexNet 和 LeNet 很像,只不过网络层数大大增加。
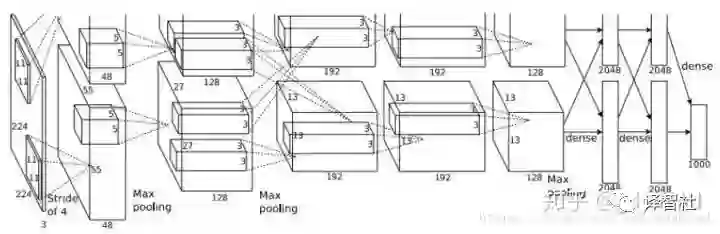
整个网络架构可视化出来是这样的(输入层的 224 x 224 应为 227 x 227):
下面总结一下这个网络的一些特点和小细节:
1. 它是第一个使用 ReLU 的网络;
2. 它使用了局部响应归一化层(Local Response Normalization Layers,LRN),。不过要注意,这种层现在已经不常用了,因为研究发现它的作用不是很大;
3. 它使用了很多数据增广(data augmentation)技术,比如翻转(flipping)、PCA Jittering、随机裁切(cropping)、颜色归一化(color normalization)等等;
4. 使用了 0.5 的 dropout;
5. batch size 为 128;
6. SGD Momentum 为 0.9;
7. 学习率为 0.01,每次 loss 不降的时候手动除以 10,直到最后收敛;
8. L2 weight decay 为 5e-4;
9. 使用 7 个 CNN ensemble(多次训练模型取均值),效果提升为 18.2% → 15.4%。
另外提一句,从上面的架构图中,CONV1 层的 96 个 kernel 分成了两组,每组 48 个,这主要是历史原因,当时用的 GPU 显存不够用,用了两块 GPU。CONV1、CONV2、CONV4 和 CONV5 在每块 GPU 上只利用了所在层一半的 feature map,而 CONV3、FC6、FC7 和 FC8 则使用了所在层全部的 feature map。
AlexNet 是第一个使用 CNN 架构在 ImageNet Large Scale Visual Recognition Challenge(ILSVRC)上取得冠军的网络,它能力挺不错,不过后面讲到的一些网络架构更加优秀,也是在我们实际应用中可以优先考虑使用的。
ZFNet 赢得了 2013 年 ILSVRC 的冠军,它所做的是对 AlexNet 的超参数进行了一些改进,网络架构没什么太大变化。但在 2014 年,有两个新的很厉害的网络架构被提出来 —— VGGNet 和 GoogleNet。它们与之前网络的主要差异在于网络深度大大增加,相比于 AlexNet 的 8 层,它们分别有 19 层和 22 层。下面我们分别具体讲一下两个网络。
VGG
VGG 主要有两点改进:
1. 显著增加了网络层数(16 层到 19 层)
2. 大大减小了 kernel size,使用的是 3 x 3 CONV stride 1 padding 1 和 2 x 2 MAX POOL stride 2 这样的 filter。
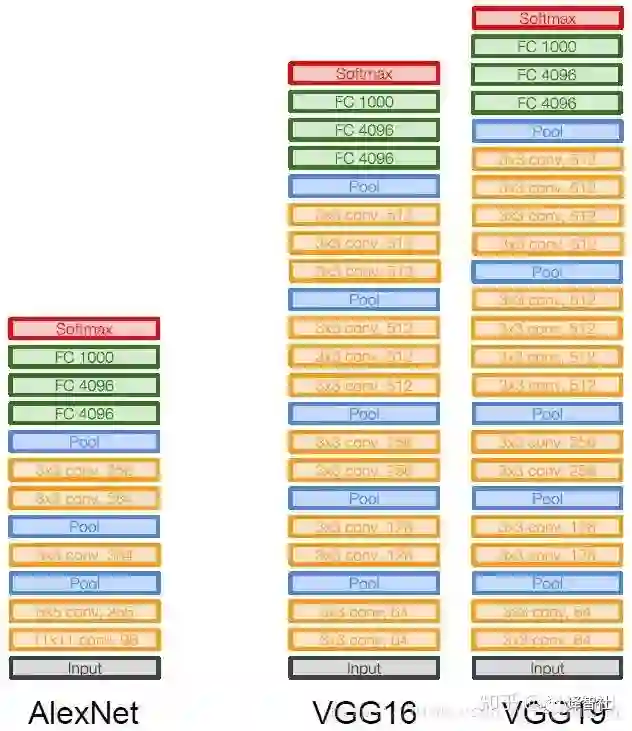
VGG 和 AlexNet 的对比如下:
加深网络很好理解,但为什么要缩小 filter 到 3 x 3 呢?我们来小小地计算一下:
当使用一个 7 x 7 的 filter 时,它的感受野是 7 x 7 的。但如果我们使用三个 3 x 3 的 filter 来替换这一个 7 x 7 的 filter 呢?
从输入经过第一个 3 x 3 filter,感受野为 3 x 3,第一个 filter 的输出再经过第二个 3 x 3 filter,感受野为 5 x 5(三个 3 x 3 的相邻的区域综合起来是 5 x 5),经过第三个 filter 之后,感受野为 7 x 7。这样,经过替代后,在感受野不变的情况下:
网络更深了,大大增加了网络的非线性能力;
网络参数变少了:
其中,
为分别为输入、输出的 feature map 数。
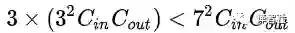
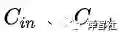
VGG16 的具体参数如下:

可以看到,每张图片 forward 的过程中需要占用约 100M 的内存,这确实是个很大的数字。另外 138M 的参数量,也比 AlexNet 的 60M 多出不少。其中占用内存大的主要是最前面的卷积层(因为网络前面部分数据量还比较大)和全连接层(之后我们可以看到一些架构通过去掉全连接层来节省内存)。
下面总结一下这个网络的一些特点和小细节:
1. 它赢得了 ILSVRC’14 的冠军;
2. 它使用了和 AlexNet 类似的训练方法;
3. 它没有使用 AlexNet 中用的 LRN 层(因为实验发现 LRN 用处不大);
4. 它分为 VGG16 和 VGG19(其中 VGG19 只是多了三层,效果稍好一些,占用内存也更多)。实际使用中 VGG16 用的更多;
5. 为了提升效果使用了 ensemble(多次训练模型,最后取均值);
6. FC7 中得到的 feature map(也就是一个 1 x 4096 的向量)提取出了很好的 feature,可以用来做其他任务。
接下来讲一下同样在 2014 年提出的网络 GoogleNet。
GoogLeNet
GoogleNet 是 ILSVRC’14 中的分类冠军,它除了使用更深的网络(22 层),还有一个更大的亮点——注重计算效率(Computational Efficiency)。GoogLeNet 中没有使用全连接层,这大大减少了参数量。此外,它还使用了「Inception 模块」(后面详细讲)。这样一来,整个网络只需要 5M 的参数量,仅仅是 AlexNet 的十二分之一!
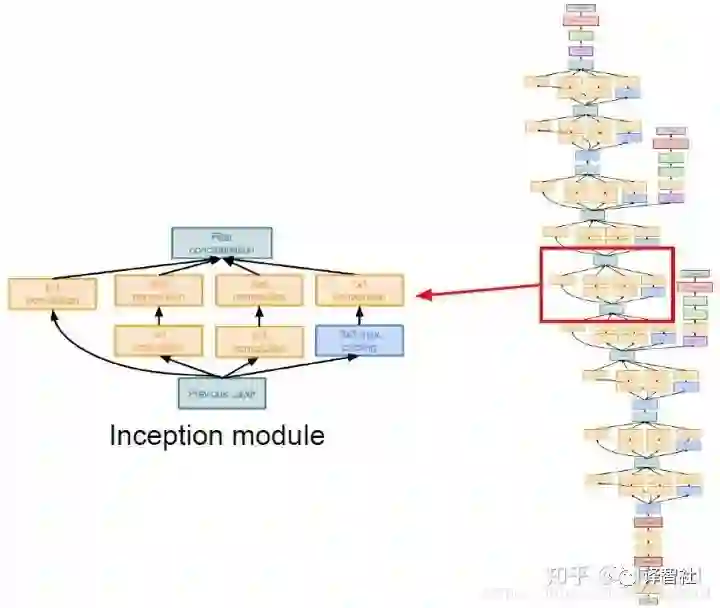
现在讲一下这个神奇的「Inception 模块」。它的主要思想是设计一种效果好的局部网络拓扑结构(local network topology),也就是在网络中嵌套网络,最后把这些网络堆叠成一个网络,示意图大概是这样的:
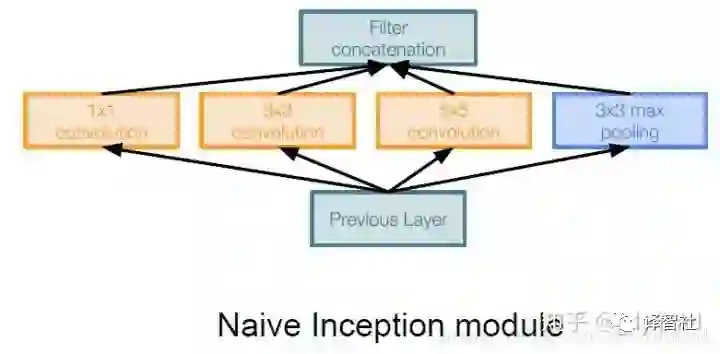
举个 Inception 模块的最 naive 的栗子(见下图),输入被分别送到不同 kernel size 的卷积核中(1 x 1, 3 x 3, 5 x 5),另外还加了一个池化。各部分分别产生输出之后,再把它们连成一个整体作为输出。
但是直接这样做会有问题,把各部分输出联系来之后,feature map 的数量成数倍的增长。我们的解决方案是引入「bottleneck」层,这种层使用 1 x 1 的卷积层,不过使用的 filter 数目更少,也就是说减少了 feature map 的数量,新的架构举例如下图:
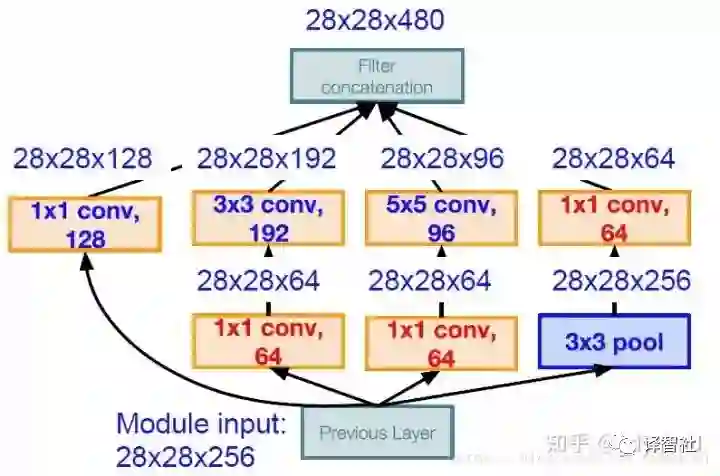
注意图中的红色部分,它们将 256 个 feature map 减少到了 64 个,也就大大降低了参数量。改进后的 Inception 模块只需要 358M 次操作(之前需要 854M 次)。
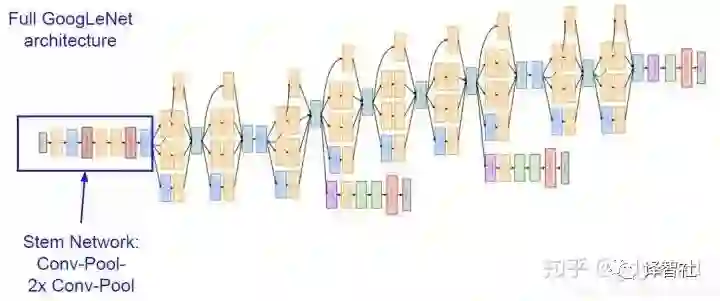
在 GoogLeNet 中,网络的开头部分是一个主干形的 stem network,这个部分和之前 AlexNet 和 VGG 中的差不多,是卷积池化之类的层的叠加(见下图蓝框)。之后把上面说的 Inception 模块串到了一起,最后加上用于分类的层形(注意没有全连接层)成了整个网络。
其中需要注意下图中框出来的部分,它们和网络的最后做了类似的工作,也输出了分类标签。最终使用三处输出一起计算 loss。这样做的原因是网络层数很多,中间的结果也很有用。此外中间的这两处输出也会计算梯度,这有助于缓解这种层数很多的网络中的梯度消失的问题。
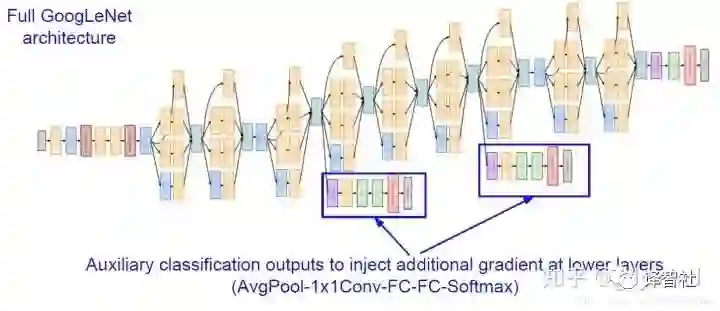
到这里,整个网络我们就介绍完啦,总体来说,网络之所以这样设计、之所以效果这么好有两方面原因。一是前面提到的 Inception Model 很有用。此外还有一个重要原因,就是 Google 财大气粗有钱任性,可以用大量的机器验证各种各样奇奇怪怪的网络架构,最后挑选出效果好的就行了(有钱真好.jpg)。
接下来我们的目光转向 2015 年的冠军 —— ResNet,具体请看下一篇文章~
LRN 链接:
https://blog.csdn.net/u014296502/article/details/78839881
https://prateekvjoshi.com/2016/04/05/what-is-local-response-normalization-in-convolutional-neural-networks/


