居然被AI剧透了?可以看视频讲故事的机器学习模型来了

架起自然语言与视觉之间的桥梁一直是计算机视觉和多媒体领域追求的目标。这一领域早起探索的任务是对图片进行描述,也就是生成单个句子描述图片内容。近年来的工作则更多关注于对图片和短视频内容进行更为详尽的描述,生成包含多个句子的段落。同时,研究者们也探索了根据照片流来讲述故事。
不过,人们在记录人生中重要的事件时,相比于短的视频片段,往往更喜欢使用长视频,比如生日派对和婚礼。为此,来自新加坡国立大学与明尼苏达大学的研究者们提出了该领域新的任务:针对长视频生成简介、连贯的描述性故事。为此,他们建立了新的数据集并提出了新的模型。在该数据集上,他们将新模型与前人工作中效果最佳的模型进行了比较,新模型取得了更优的结果。


图|上图为人类所写的故事; 下图为新模型生成的故事; 均只选择了故事的前五句和视频中它们nm相应的关键帧的采样。
针对长视频生成故事这一新任务与以往的各项任务都存在着显著的差别。与短视频详细描述任务相比,该任务更关注包含复杂动态事件的长视频,抽取其中的重要场景生成故事,而不要求包含视频中出现的每一个细节。而与根据照片流生成故事相比,该任务更基于视觉内容。因为由照片流生成故事的任务中,视觉材料由一张张照片组成,相对贫乏,故而任务的关键是填补照片中间的信息鸿沟。这就意味着故事讲述的过程需要想象力和先验知识,得到的故事可能因为标注者的背景不同而产生很大差异。而这项任务的视觉信息十分充足,根据视觉信息就足以生成故事,不会受到过多主观因素的影响。
基于这些特性,这项新任务也主要面临两大挑战。第一,与单句描述相比,长故事包含数量更多,更多样化的句子。而对于相同的视觉内容,可能有多种多样的描述。为此,保证故事的简洁性和连续性就更为困难。第二,长视频中通常包含多个角色、地点和活动,难以把握故事的主线。
为了应对这些挑战,研究者将该任务分解为两个子任务。首先从长视频中挖掘重要的片段,然后通过检索的方式选择合适的句子生成故事。根据这两个子任务,他们提出了由两个部分组成的模型。
模型的第一部分是上下文感知多模态嵌入学习框架,通过两个步骤,由局部到全局建立起多模态语意空间,也就是将视频内容和自然语言映射到同一语意空间中,将其联系在一起。它首先对视频片段-句子对进行建模,然后将长视频转化为一系列的视频片段。通过一个残差双向 RNN(Residual Bidirectional RNN)进行处理。该结构不仅能将上下文信息整合到多模态语意空间中,同时可以保证时序上的连贯性和语意嵌入的多样性。
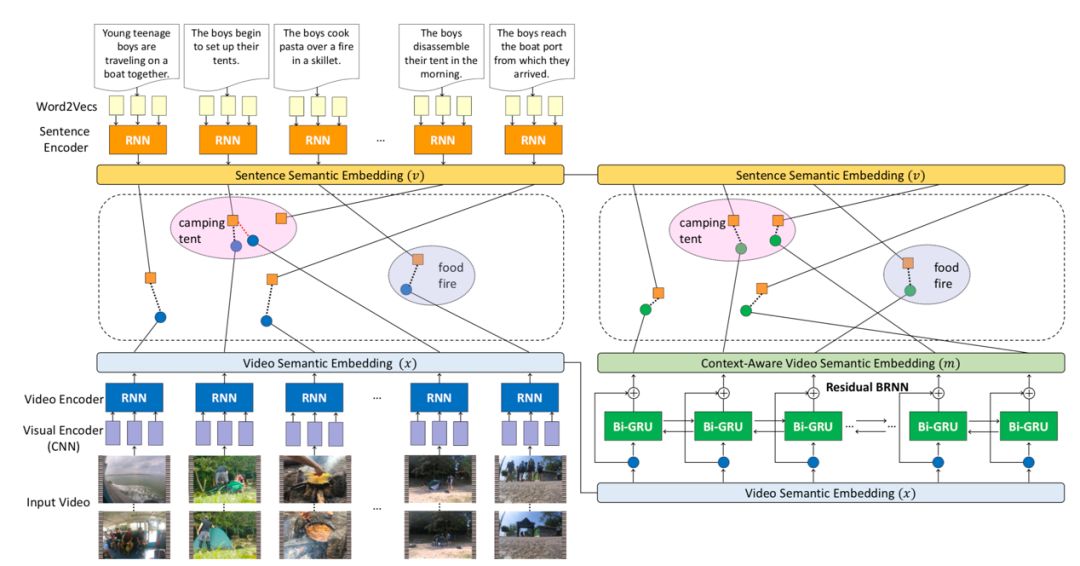
图|局部到整体的多模态嵌入式学习模型。左侧部分为局部嵌入学习。针对每一个输入的视频片段-句子对,利用 CNN+RNN 对视频片段进行编码,利用 RNN 对句子进行编码。
右侧为全局嵌入学习,将视频片段和句子应映射到同一语意空间。
模型的第二部分称之为“旁白”。给定一个视频,该结构首先从中抽取一系列重要的剪辑片段,接下来在语意空间中检索与这些剪辑片段最匹配的句子,生成整个故事。视频中哪些方面对于一个好故事是重要的呢?换句话说,什么样的片段是重要的呢?这显然没有一个明确的定义。因此,这一模块被设计为一个强化学习的代理,通过观察一系列的输入视频来学习一个策略,通过该策略选择奖励最大的剪辑片段。而这个奖励,就是通过这些剪辑片段生成的故事与人类书写的参考故事之间的相似度来决定。
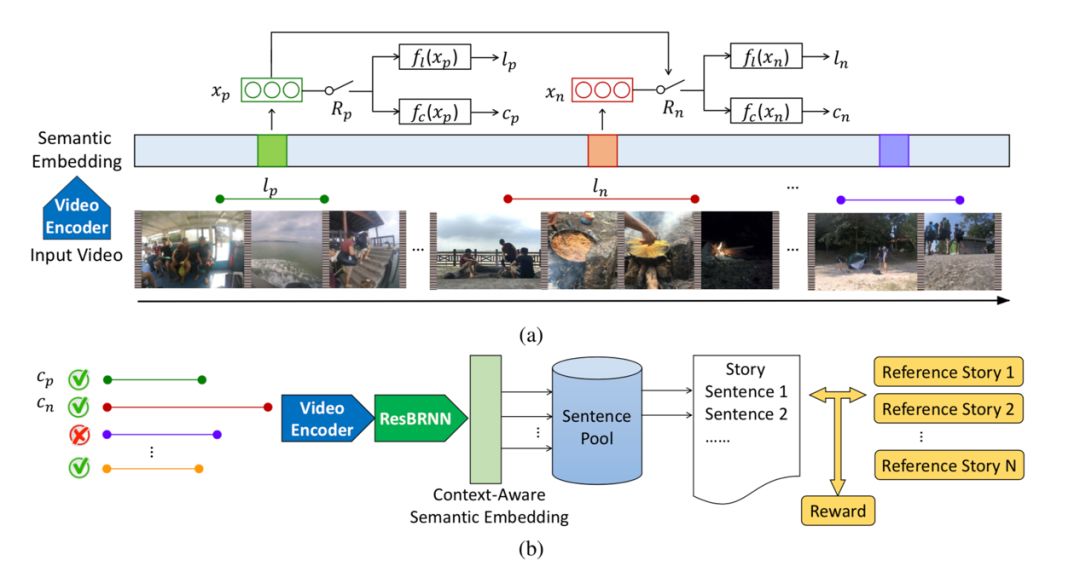
图|上图为旁白网络,根据输入的视频提取重要的视频片段。下图为根据提取出的片段检索出句子组合成故事的过程。
数据集一直是驱动该领域研究进步的重要因素。为此,研究者针对这一新任务专门建立了 Video Story 数据集。该数据集包含四种常见而复杂的事件(生日、露营、圣诞、婚礼),通过关键字检索从 Youtube 上检索下载,最后手动选择 105 个在事件内部和不同事件之间都有足够差异性的视频。这些视频的故事通过亚马逊劳务众包平台 Amazon Mechanical Turk 收集。故事的选择必须满足以下三个条件:(1)至少包含 8 个句子;(2)每个句子至少包含 6 个单词;(3)故事内容要连贯,并合视频内容契合。最后研究者请工作人员针对每个故事中每个句子,标注其在视频中的开始时间和结束时间。最终,研究者收集了 529 个故事。

图|Video Story 与其他现存数据集的比较。
研究者在新数据集上对新模型和目前效果最好的模型进行了评估和比较,新模型均取得了更优的结果。
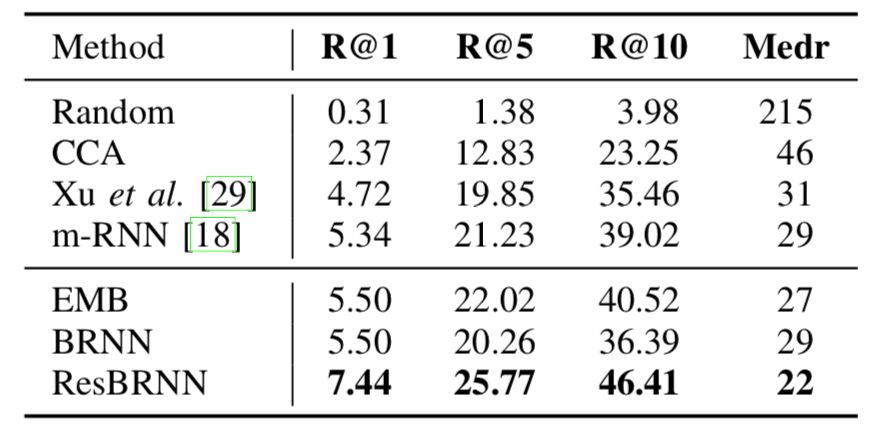
图|多模态嵌入评估:以一系列视频片段作为查询条件,检索得到一个句子序列。R@K 的数值越高,Medr 的数值越低表示效果越好
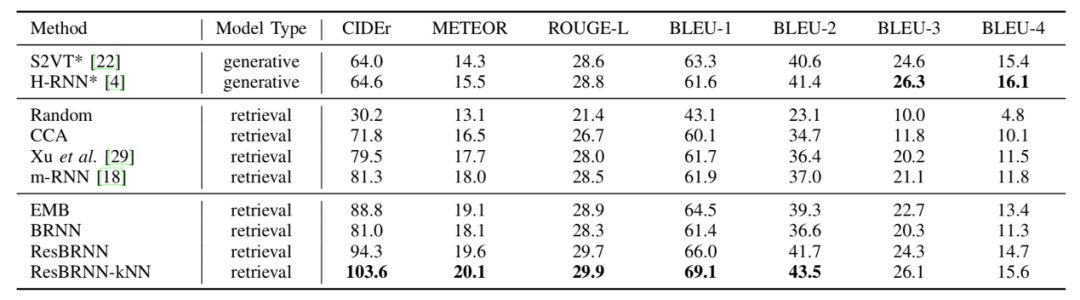
图|Video Story 数据集上的故事生成评估结果(针对对模型第二部分)。实验中,视频片段由各个模型自行提取,根据视频片段检索句子的方式固定。Narrator(旁白模型)各项指标均效果更佳。
不过,该模型目前还有很大的局限性。例如,生成故事的句子只能在数据集中检索。研究者表示,在接下来的工作中,他们将使用更多野生的句子来扩展故事的多样性,同时使用一些自然语言处理的方法使句子之间的的衔接更加自然。

图|不同模型生成的故事举例。Proposed 为研究者提出的新模型,GT 为作为参照的标准答案。绿色框为 GT 选择的重要视频片段,黄色框新模型选择的重要视频片段。红色框为二者共同选中的视频片段。
-End-
参考:https://arxiv.org/pdf/1807.09418.pdf





