文本分类:互联网内容王国的锦衣卫
一、文本分类与内容审核
内容是互联网公司线上业务流转的血液,重视内容生产也是各家互联网公司的常态,但是在追求内容量的同时,控制内容的质也是不可或缺的,因为内容是直接广播给亿万普通用户的,所以内容审核也是所有互联网公司要面临的难题。面对海量的内容,要做到自动高效地审核,文本分类就是一项关键技术,堪称互联网内容王国的锦衣卫。
文本分类作为NLP领域最经典的使用场景之一,已经积淀了许多方法,大致可以分为三类。
第一种是最早的专家规则(Pattern)方法,这种方法可以短平快的解决top问题,但覆盖的范围和准确率都非常有限。
第二种就是统计学习方法。在线文本数量增长和机器学习的兴起,一套‘人工特征工程+浅层分类模型’的方式逐渐形成,用来解决大规模文本分类问题。这一阶段主要的的特征表示方法为one-hot,连续词袋模型BOW,tfidf等等,主要的分类模型包括SVM,贝叶斯,决策树等等。
第三种就是深度学习方法,目的为了解决文本表示高纬度、高稀疏的特征表达能力弱,文本上下文依赖问题。google的Mikolov提出的word2vec词向量及工具包的开源,推动了文本语义的研究,与此同时,提出了Hierarchical Softmax 和 Negative Sample两个方法,很好的解决了计算效率问题。脱胎于word2vec,诞生了一个fasttext模型。强有力的词向量的表示方法,使得文本可以转化为类图片的稠密数据,从而诞生了基于cnn的模型,例如textcnn;为了解决文本上下文依赖问题,循环神经网络RNN,LSTM,BiLSTM等模型被应用。
基于此,本文将浅探SVM,fastText, GDBT三个常见文本分类模型在产业互联网内容审核业务中的实践效果。
二、相关技术
2.1.svm
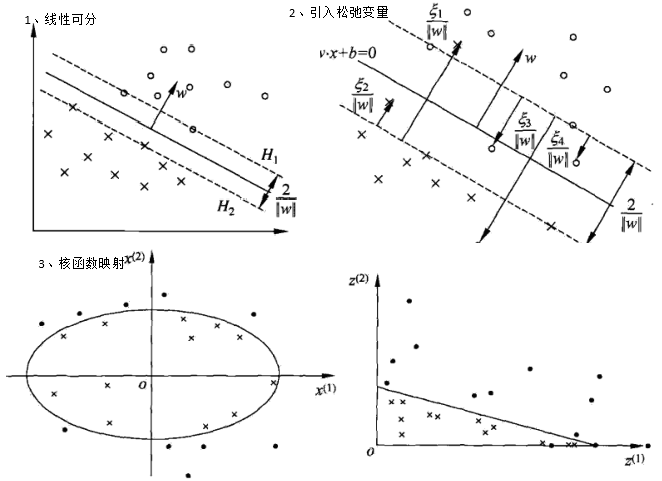
支持向量机(svm)通过寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解。通常有三种情况:
一、样本线性可分时,通过硬间隔最大化;
二、为了解决一些outliers,引入松弛变量,增强容错率,采用软间距;
三、为了解决线性不可分的样本,引入核函数,将原始样本映射到一个高维空间,从而使其线性可分。
这三种情况的描述如下:
为了更容易地求解支持向量的优化问题,和自然地引入核函数,应用拉格朗日对偶性将原始问题转化为对偶问题进行求解,线性可分svm原始问题与对偶问题对应关系如下:

在内容审核中,首先提取房评的tfidf特征,然后进行简单的svm分类,相关代码:
from sklearn.svm import SVC
def train(self, x, label):
self.svm = SVC(
kernel='rbf',
class_weight='balanced',
C=3,
gamma=1,
probability=True)
self.svm.fit(x, label)
2.2.fasttext
脱胎于word2vec的fastText主要包含三部分,模型架构,层次SoftMax和N-gram特征。原理是把句子中所有的词向量进行平均,然后直接接softmax层。与此同时,加入了一些n-gram特征来捕获局部序列信息。相关原理图如下:
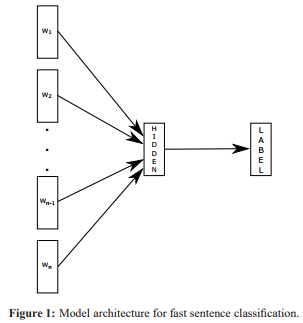
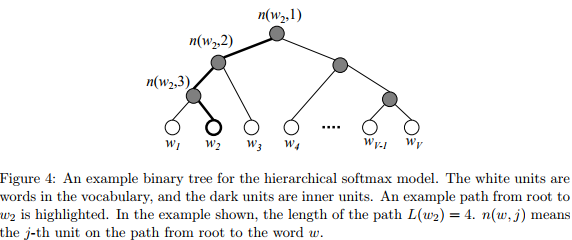
在内容审核中,先将内容信息分词,然后用调用fasttext,命令如下:
fastText/build/fasttext supervised \
-input data/raw/fasttext_train_1.txt \
-output data/fasttext_model/fst_1 \
-lr 1 -epoch 100
fastText/build/fasttext predict-prob data/fasttext_model/fst_1.bin \
data/raw/fasttext_test_1.txt > data/raw/fasttext_res_1.prob
2.3 GBDT
梯度提升决策树(GDBT)采用加法模型,不断减小训练过程产生的残差来达到将数据分类或者回归的算法。GBDT通过多轮迭代,每轮迭代产生一个弱分类器,弱分类器一般为CART TREE(分类回归树),每个分类器在上一轮分类器的残差基础上进行训练。最终的总分类器 是将每轮训练得到的弱分类器加权求和得到的。模型最终可以描述为:
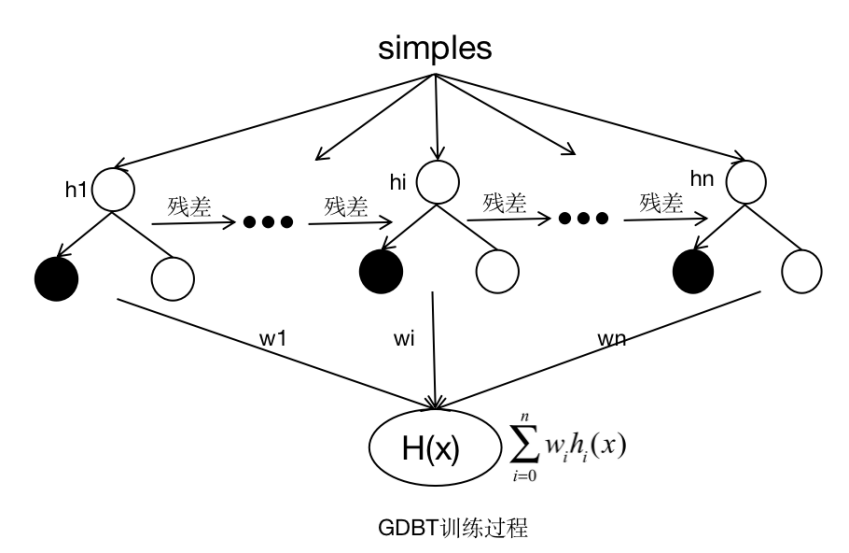
在内容审核中,对于不同的文本进行不同的处理,对于基础信息的类型字段做onehot特征处理,标签字段counter2vector特征处理,以及城市字段做onehot特征处理,对于内容详情分字段处理特征,关键词特征,从人工审核人员标红的内容中提取tfidf特征等,具体如下图所示:
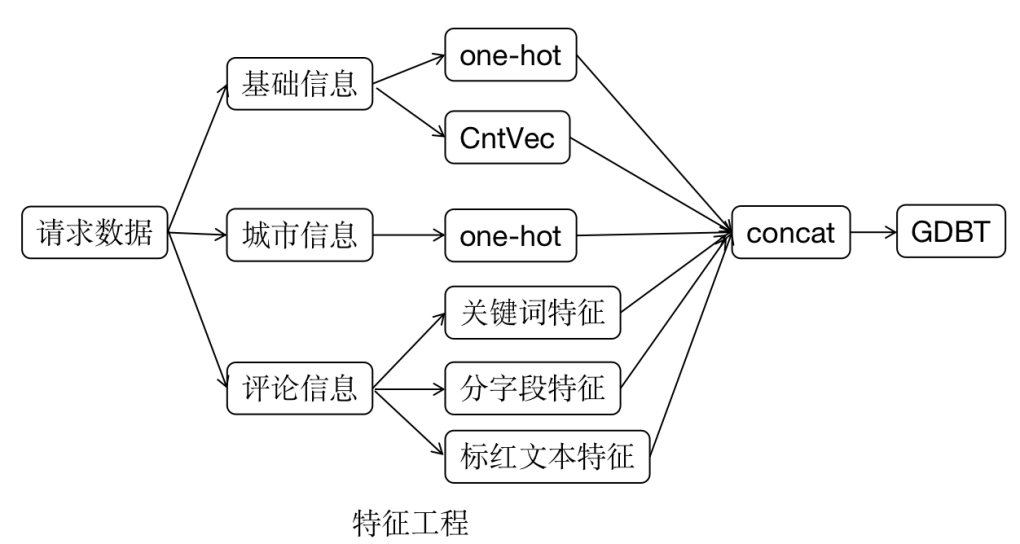
特征工程相关代码:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.preprocessing import OneHotEncoder,LabelEncoder
from sklearn.feature_extraction.text import TfidfVectorizer
def get_feature(self, input_path,all_data_path):
data = pd.read_csv(input_path)
data_all = pd.read_csv(all_data_path).fillna('')
#获取标红字段语料
data_all['SEG']=data_all['biaohong'].apply(seg_comment)
data['SEG'] = data['comment'].apply(filter_comment).apply(seg_comment)
data['comment_dict'] = data['comment'].apply(json_to_dict)
data['base_dict'] = data['base'].apply(json_to_dict)
features = list(data_all['SEG'])
tfidf_vec1 = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b",
stop_words=self.stopword)
tfidf_vec1.fit(features)
#关键词
tfidf_vec2 = TfidfVectorizer(
token_pattern=r"(?u)\b\w+\b",
stop_words=self.stopword,
vocabulary=set(self.keywords))
tfidf_vec2.fit(features)
# 划分数据集
np.random.seed(0)
test_index = np.random.choice(len(data), size=int(0.2 * len(data)))
train_index = list(set(data.index.tolist()).difference(set(test_index)))
test_data = data.loc[test_index, :]
test_x = tfidf_vec1.transform(list(test_data['SEG']))
test_y = list(test_data[self.class_used])
train_data = data.loc[train_index, :]
train_x = tfidf_vec1.transform(list(train_data['SEG']))
train_y = list(train_data[self.class_used])
arr_test = tfidf_vec2.transform(list(test_data['SEG']))
arr_train = tfidf_vec2.transform(list(train_data['SEG']))
test_x = sparse.hstack((test_x, arr_test))
train_x = sparse.hstack((train_x, arr_train))
cont_vec = CountVectorizer(
token_pattern=r"(?u)\b\w+\b",
max_features=50,
stop_words=self.stopword)
# comment分字段特征提取
for field in self.comment_key:
data[field] = data.apply(
lambda raw: sub_feild_text(raw['comment_dict'], field), axis=1)
data[field] = data[field].apply(seg_comment)
cont_vec.fit(data[field])
arr_train = cont_vec.transform(data.loc[train_index][field])
arr_test = cont_vec.transform(data.loc[test_index][field])
train_x = sparse.hstack((train_x, arr_train))
test_x = sparse.hstack((test_x, arr_test))
#基础信息特征
onehot_vec = OneHotEncoder()
counter_vec = CountVectorizer(stop_words=self.stopword)
for field in self.base_key:
if field in self.onehot_field:
data[field] = data.apply(lambda raw: sub_feild_text(raw['base_dict'], field), axis=1)
data[field] = LabelEncoder().fit_transform(data[field])
onehot_vec.fit(data[field].values.reshape(-1, 1))
arr_train = onehot_vec.transform(data.loc[train_index][field].values.reshape(-1, 1))
arr_test = onehot_vec.transform(data.loc[test_index][field].values.reshape(-1, 1))
train_x = sparse.hstack((train_x, arr_train))
test_x = sparse.hstack((test_x, arr_test))
if field in self.counter_field:
data[field] = data.apply(lambda raw: sub_feild_text(raw['base_dict'], field), axis=1)
counter_vec.fit(data[field])
arr_train = counter_vec.transform(data.loc[train_index][field])
arr_test = counter_vec.transform(data.loc[test_index][field])
train_x = sparse.hstack((train_x, arr_train))
test_x = sparse.hstack((test_x, arr_test))
# 加入城市字段特征
counter_vec.fit(data['city_code'].apply(str))
arr_train = counter_vec.transform(
data.loc[train_index]['city_code'].apply(str))
arr_test = counter_vec.transform(
data.loc[test_index]['city_code'].apply(str))
train_x = sparse.hstack((train_x, arr_train))
test_x = sparse.hstack((test_x, arr_test))
# 归一化
scaler = MaxAbsScaler()
scaler_path = self.vectorizer_path + 'nor_vec' + '.pickle'
scaler.fit(train_x)
train_x = scaler.transform(train_x)
test_x = scaler.transform(test_x)
self.save_model(scaler, scaler_path)
return train_x, train_y, test_x, test_y
模型代码:
from sklearn.ensemble import GradientBoostingClassifier
def train(self, x, label):
self.gdbt = GradientBoostingClassifier(
learning_rate=0.06,
n_estimators=1000,
random_state=0,
max_depth=9,
subsample=0.8,
min_samples_leaf=20)
self.gdbt.fit(x, label)
三、实验对比
首先,拉取数据库中的全量数据,统计各审核类型的占比。
其次,根据处理人字段,筛选出优秀审核人员的数据。
然后,对全量数据进行清洗,将明显的错误样本数据过滤掉,主要通过做了两部处理;一、关键词过滤明显判错的样本,二、采用simhash去掉两个字段完全相同但判错的样本。
再者,根据全量数据分布随机抽取各类数据;最后,构建了与线上分布一致的数据集。数据处理的流程如下:
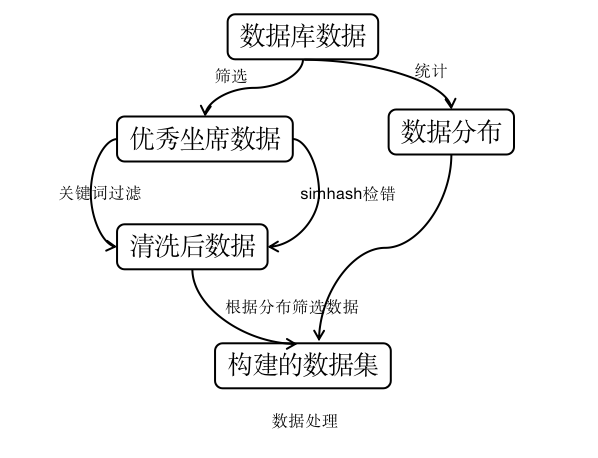
随机拉取了1000条数据用于验证。审核类型有11种,对于不同类别的要求,审核方给了详细的文档,根据文档说明,总结了各类的相关规则;整个项目流程是先规则审核,规则处理不了的,通过模型处理。
以上三种模型在此1000条数据上的效果如下:
| 模型 | 准确率 | 召回率 | F1 |
|---|---|---|---|
| SVM | 0.9 | 0.81 | 0.85 |
| fastText | 0.9 | 0.8 | 0.85 |
| GDBT | 0.9 | 0.84 | 0.87 |
从上表可以得出如下结论:在内容审核项目中,由于树模型与该问题决策过程比较吻合,且提取了大量可描述错误信息的特征,故性能表现较好。对于需要审核的内容,各字段描述的信息具有一致性,通过样本与不通过样本差异不明显,无明显语义区别,故而fasttext性能不佳。SVM是基于距离来优化模型的,对于离散型的特征,即使归一化了,计算距离时,影响较大,会导致效果不佳。
四、踩过的坑
尽管一般增加样本有防止过拟合、提高模型的识别能力等等优点,当训练样本大于2w条时,SVM会很吃力;当训练数据量比较大时,离群点变多时,也会导致SVM性能不佳。
数据分布很重要,但采样的数据分布差异较大时,评估的结果会存在较大的差异,数据集划分很重要。
五、参考文献
[1]李航统计方法学(第七章SVM)
[2]https://arxiv.org/pdf/1301.3781.pdf (word2vec)
[3]https://arxiv.org/pdf/1411.2738.pdf (word2vec)
[4]https://arxiv.org/pdf/1607.01759v2.pdf (fasttext)
[5]https://projecteuclid.org/download/pdf_1/euclid.aos/1013203451(gdbt)
作者介绍
江霜艳,2019年1月毕业于哈尔滨工业大学智能计算研究中心,毕业后加入贝壳语言智能与搜索部,主要从事意图理解、内容审核等工作。
推荐阅读
大幅减少GPU显存占用:可逆残差网络(The Reversible Residual Network)
AINLP-DBC GPU 云服务器租用平台建立,价格足够便宜
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




